CS194-26 Project 1: Colorizing the Prokudin-Gorskii Photo Collection
Brian Zhu
brian_zhu@berkeley.edu
Project Overview
Over 100 years ago, Sergei Mikhailovich Prokudin-Gorskii pioneered the development of color photography through his three-camera system, which created negatives in three color channels: red, green, and blue. Prokudin-Gorskii journeyed across Russia, documenting its various aspects and collecting over 10,000 of such novel exposures in the span of 10 years. His works have been saved in the Library of Congress, and with modern technology we are now able to composite Prokudin-Gorskii's negatives into color composites. The objective of this project is create our own homemade compositing algorithm.
Problem Statement
The input image is a stack of each of the three color negatives in the order of blue, green, red (top to bottom):

The goal is to split the input by channel (i.e. split into thirds) and stack the channels together to form an RGB image. For example, a good output would look like the following:

However, the results from doing a naive stack doesn't look very good:

Clearly some extra alignment needs to be done.
Methodology and Results
Starting Simple: Aligning with Single-Scale Search
First, establishing some quick terminology:
- We want to align a
sourceimage to atargetimage
The main idea: we start with the source and target with their top left corners aligned

The target stays fixed, and we "slide" the source around a small area (e.g. it can only move from its original position by up to 15px in any direction).
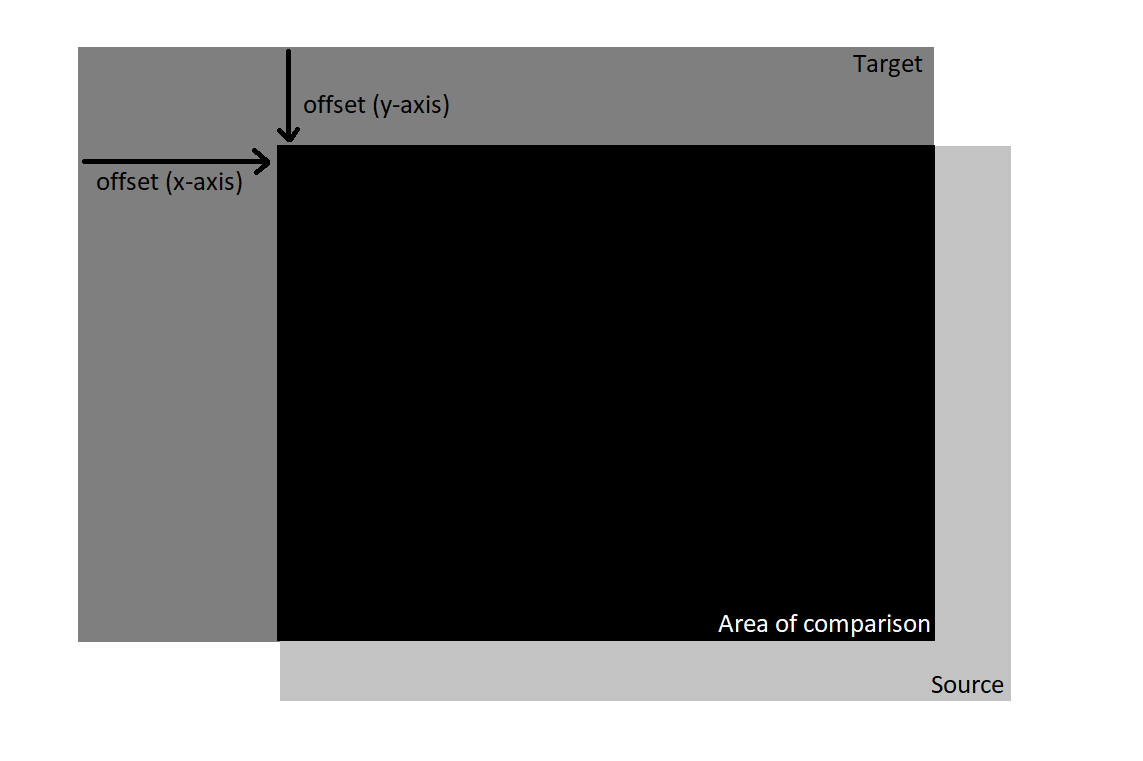
We then take the area of overlap between the source and target and calculate a difference score. The best offset is one which creates an area of overlap with the best difference score.
Difference Scores
The base difference metrics are the following:
- Sum of Squared Differences (SSD): Take the difference in values between each pixel, square them, and sum them together. The lower the score, the better,
- Normalized Cross-Correlation (NCC): Normalize each image (i.e. divide by its L2 norm) and calculate the dot product between them. The higher the score, the better.
However, it is important to note that these metrics are affected by the number of pixels being compared (e.g. 1 pixel with a difference of 1.0 compared to 100 pixels with a difference of 0.01). Since the area of overlap is not always the same, it may be safer to take the average instead:
- Sum of Squared Differences (SSD-Avg): Take the difference in values between each pixel, square them, and average them together. The lower the score, the better,
- Normalized Cross-Correlation (NCC-Avg): Normalize each image (i.e. divide by its L2 norm) and calculate the dot product between them. However instead of summing the elementwise product between the pixels, average them together. The higher the score, the better.
Single-Scale Search Results
Images used (from left to right): cathedral.jpg, monastery.jpg, tobolsk.jpg
Parameters:
- Maximum offset: 15px in any direction (31 x 31 search space)
- Only used inner 70% of
sourceandtargetfor comparison
- The red and green channels were aligned to the blue channel
SSD:

NCC:

SSD-Avg

NCC-Avg

We see that both SSD and SSD-Avg are able to align the color channels correctly, while NCC misaligns cathedral and monastery and NCC-Avg only misaligns cathedral. The final alignments are the following (negative offsets correspond to shifting left (x-axis) or upward (y-axis), positive offsets correspond to shifting right (x-axis) or downward (y-axis)):
Alignments on JPG Images
| File name | Offset (red channel) | Offset (green channel) |
|---|---|---|
| cathedral.jpg | x: 3px, y: 12px | x: 2px, y: 5px |
| monastery.jpg | x: 2px, y: 3px | x: 2px, y: -3px |
| tobolsk.jpg | x: 3px, y: 6px | x: 3px, y: 3px |
Aligned JPG images:
cathedral.jpg
monastery.jpg
tobolsk.jpg
From this point on, the SSD-Avg metric is used for difference scoring
A Recursive Upgrade: Pyramid Search
It is important to note that the above images were only about 350 x 350 pixels in size. What happens if the image is much larger, say 3500 x 3500 pixels? If a 16 x16 search would suffice for the smaller images, it could mean that search space will need to be much larger, e.g. 160 x 160, which is 100 times larger!
To reduce the total amount of searching, we can try to take a coarse-to-fine approach (e.g. search a 100 x 100 area with a stride of 10 pixels, find the best offset so far, then search in a 10 x 10 area around the best offset with a stride of 1 pixel).
The idea is the following:
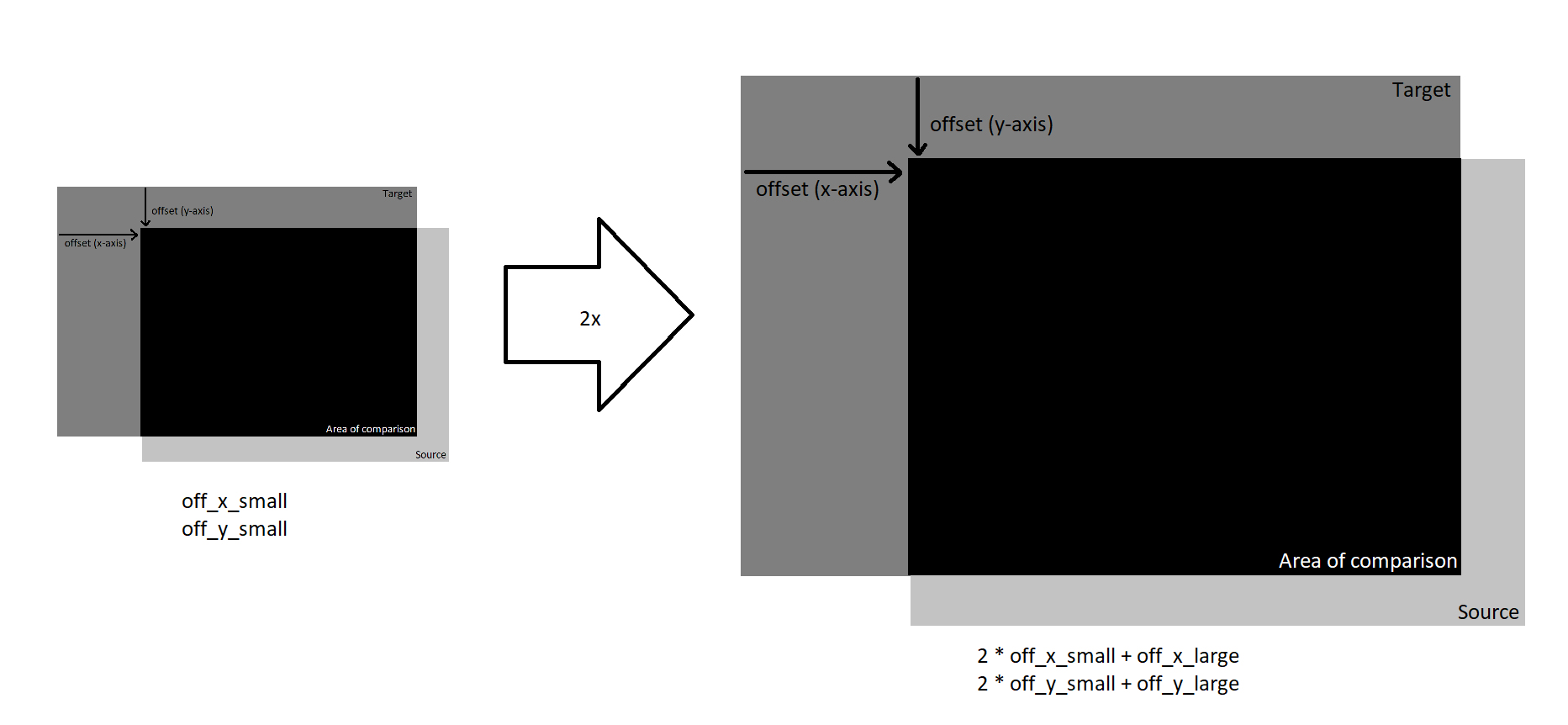
- Fix a search area (e.g. 10 x 10)
- Start with a scaled-down version of the image, and run the algorithm from single-scale search using the fixed search area.
- Scale up the image (e.g. by 2x) as well as the offsets found from before. Run single-scale search around the found offset using the same sized-search area.
- Repeat the above step until back at full resolution
The repeated scaling of the image can be done recursively, and even with a small search area per layer, we can end up covering a large search space. For example, if we scale the image down by 2x 4 times and use a 2 x 2 search area, we still are effectively searching a 16 x16 area.
Using this method, we can align the larger tif images, which are about 3500 x 3500 pixels in size, without expending too much time.
Pyramid Search Results
Parameters:
- Scaling factor: 2x
- Search area per scaling layer: 4 px in each direction (9 x 9 search space)
- Minimum image size: at least 64px wide and 64px high
- Crop: Used inner 70% of image for comparison
- Difference Scoring: SSD-Avg
At the same time I also tried varying the target channel between red, green, and blue
Using blue as target channel:

church.tif

icon.tif

onion_church.tif

train.tif

emir.tif

lady.tif

self_portrait.tif

workshop.tif

harvesters.tif

melons.tif

three_generations.tif
Using green as target channel:

church.tif
icon.tif

onion_church.tif

train.tif

emir.tif

lady.tif

self_portrait.tif

workshop.tif

harvesters.tif

melons.tif

three_generations.tif
Using red as target channel:

church.tif

icon.tif

onion_church.tif

train.tif

emir.tif

lady.tif

self_portrait.tif

workshop.tif

harvesters.tif

melons.tif

three_generations.tif
In all three cases, the pyramid search works well in general. However, looking at emir.tif in particular, we see that using the green target channel yields the most robust results:

Aligning to blue channel

Aligning to green channel

Aligning to red channel
The final alignments are the following (negative offsets correspond to shifting left (x-axis) or upward (y-axis), positive offsets correspond to shifting right (x-axis) or downward (y-axis)). The offsets reported are for alignment against the green channel:
Alignments on TIF images
| Name | Offset (red channel) | Offset (blue channel) |
|---|---|---|
| church.tif | x: -8px, y: 33px | x: -4px, y: -25px |
| emir.tif | x: 17px, y: 57px | x: -24px, y: -49px |
| harvesters.tif | x: -3px, y: 65px | x: -17px, y: -59px |
| icon.tif | x: 5px, y: 48px | x: -17px, y: -41px |
| lady.tif | x: 3px, y: 62px | x: -9px, y: -55px |
| melons.tif | x: 3px, y: 96px | x: -10px, y: -81px |
| onion_church.tif | x: 10px, y: 57px | x: -27px, y: -51px |
| self_portrait.tif | x: 8px, y: 98px | x: -29px, y: -79px |
| three_generations.tif | x: -3px, y: 59px | x: -14px, y: -53px |
| train.tif | x: 27px, y: 43px | x: -6px, y: -43px |
| workshop.tif | x: -11px, y: 52px | x: 0px, y: -53px |
Custom Images 🙂
With pyramid search finding pretty good offsets at decent speeds, it's time to try running the same search on other images from Prokudin-Gorskii's collection.
Parameters used:
- Scaling factor: 2x
- Search area per scaling layer: 4 px in each direction (9 x 9 search space)
- Minimum image size: at least 64px wide and 64px high
- Crop: Used inner 70% of image for comparison
- Difference Scoring: SSD-Avg
- Aligned red and blue channels to green channel

adobe_house.tif

creek.tif

flowers.tif

sculpture.tif

bridge.tif

floodgates.tif

marsh.tif
Conclusions
It was really fun to build an algorithm from scratch that allows us to take a more colorful (pun intended) view of the past! Looking at the same photos in the Library of Congress, there clearly still is a lot more progress that can be made in terms of improving image processing beyond alignment. Perhaps developing automatic cropping, color balancing, as well as ways to clean up artifacts in the image are further steps to look into!