
|
|
|
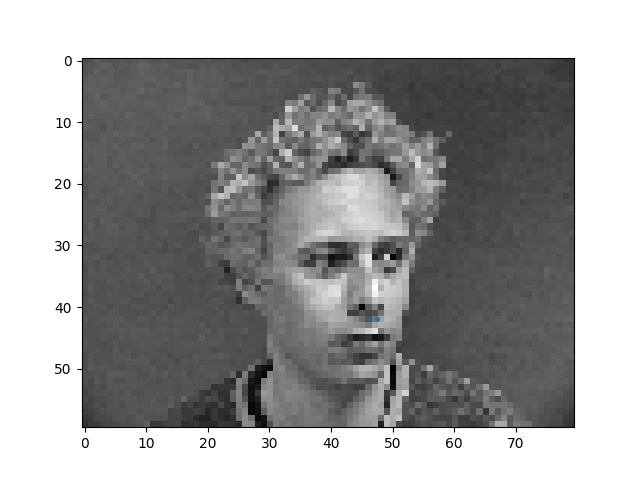
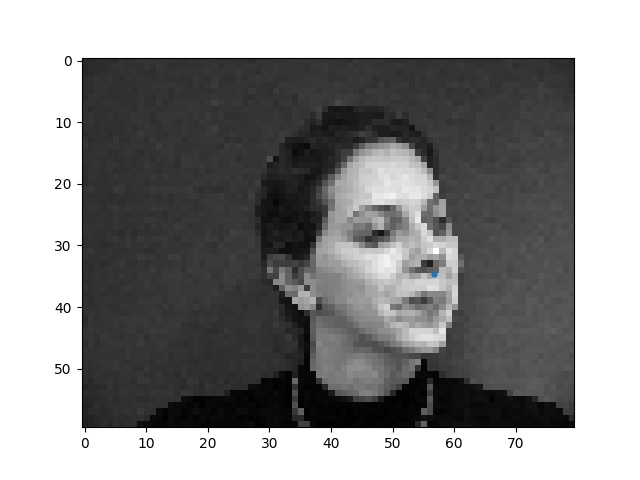
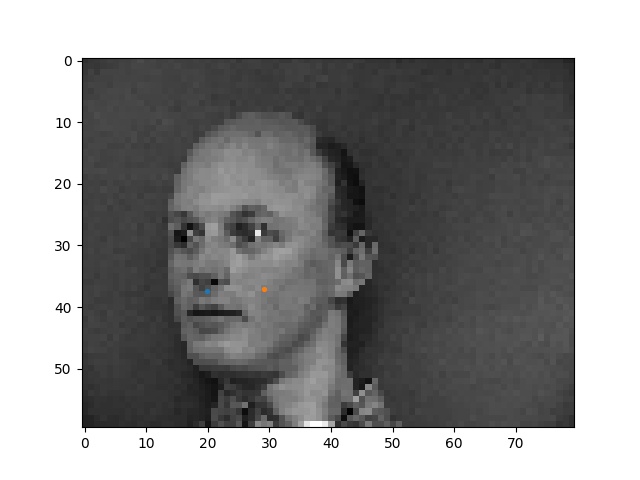
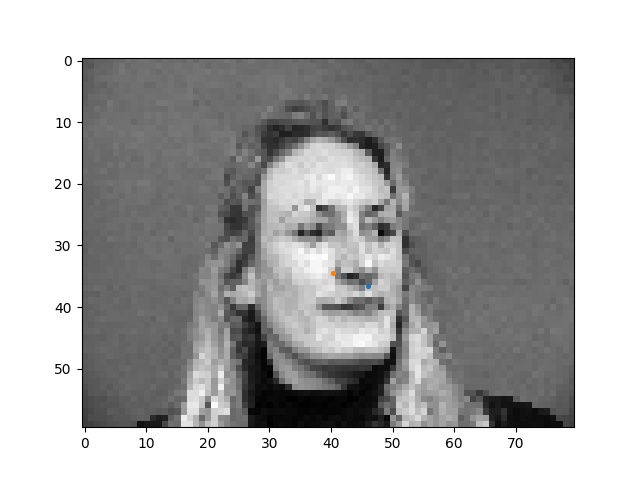
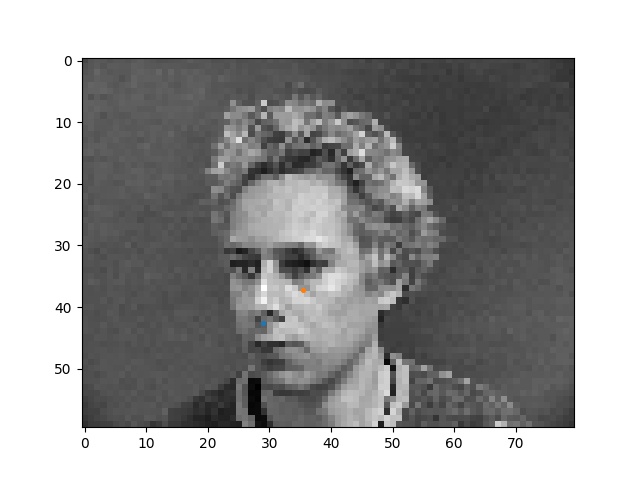
Here are some faces with the ground truth nose tip points shown. Sorry the points are kinda small, matplotlib was being difficult with me :(
|
|
|
|
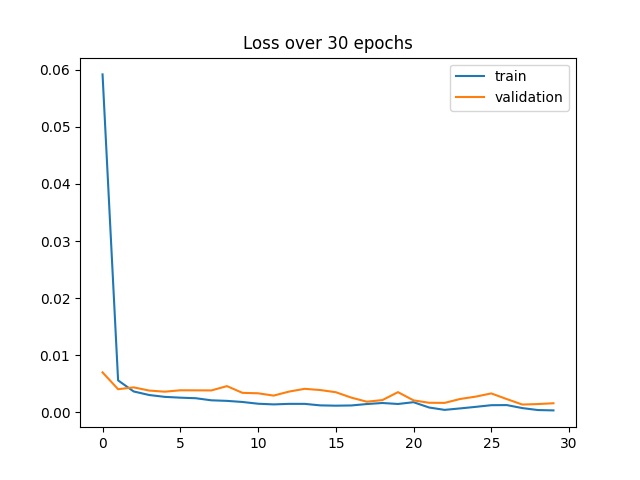
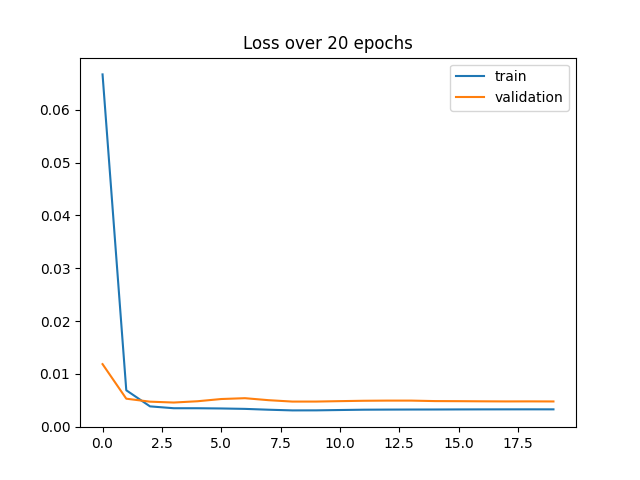
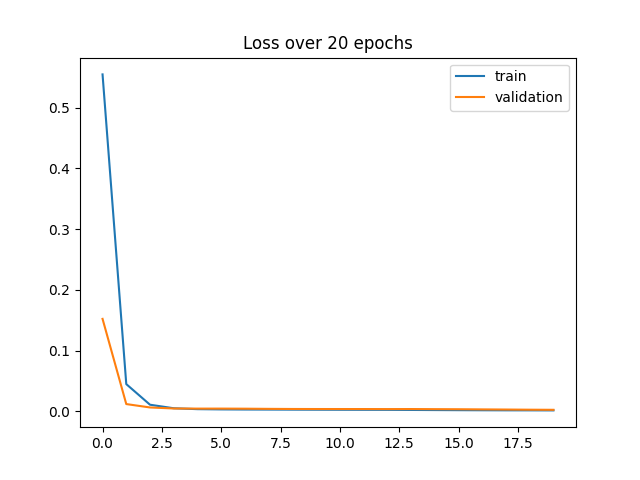
Here's a graph that shows botht the training and validation loss while training over 30 epochs.
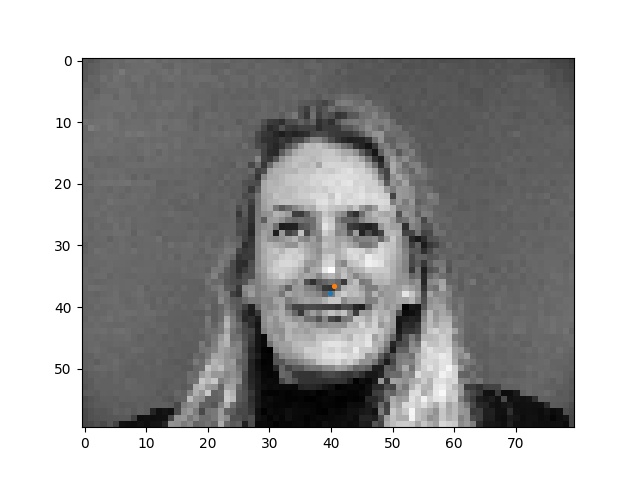
Let's first look at the cases where the network worked well.
|

|

|
Next, here are some fail cases. I think these images failed because the network is looking for dark spots near the center of the image, so when there are multiple dark spots near the center, or if the nose is too far from the center, it gets a little confused.
|
|
|
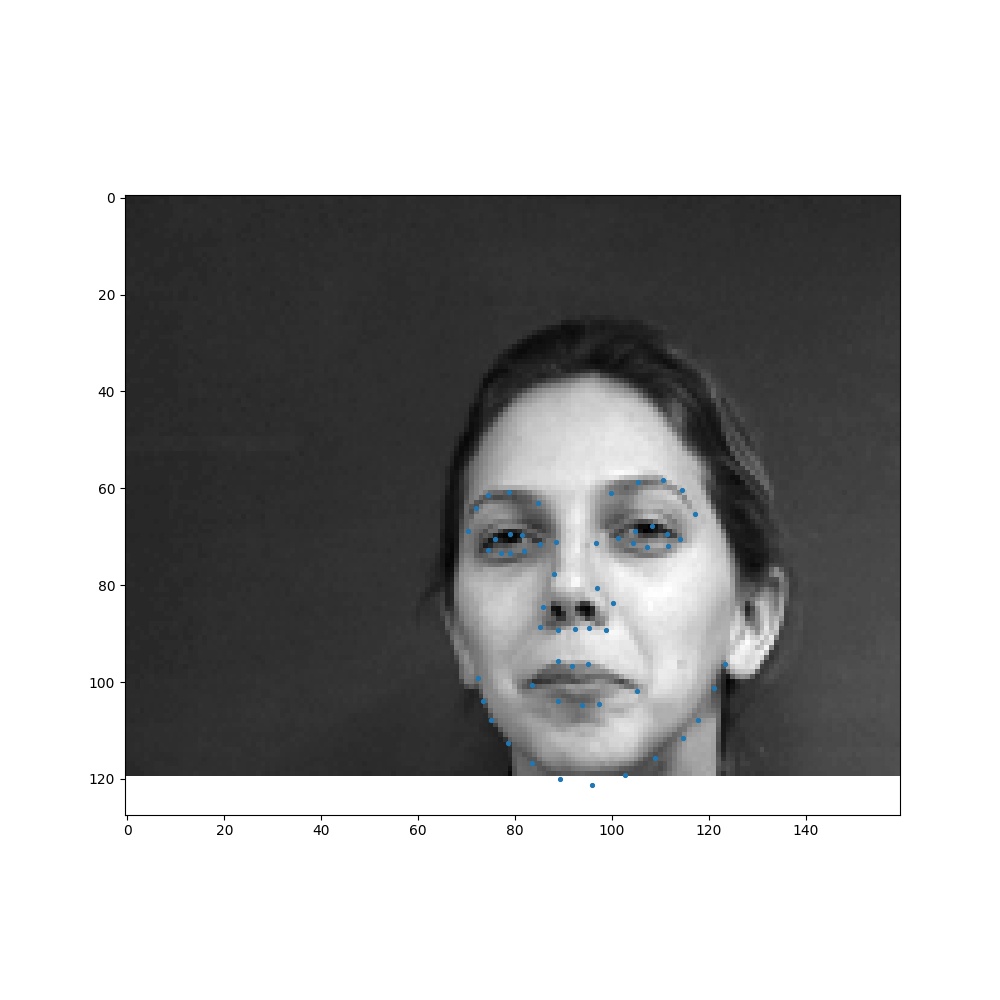
Here are some images with their ground truth keypoints. I did some random cropping of images, so some faces will be off-centered to help vary my training set.

|

|

|
|
Here are all of the layers I used in my model.
FacialPointsNet(
(conv1): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(conv4): Conv2d(64, 96, kernel_size=(5, 5), stride=(1, 1))
(conv5): Conv2d(96, 128, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=14400, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=116, bias=True)
)
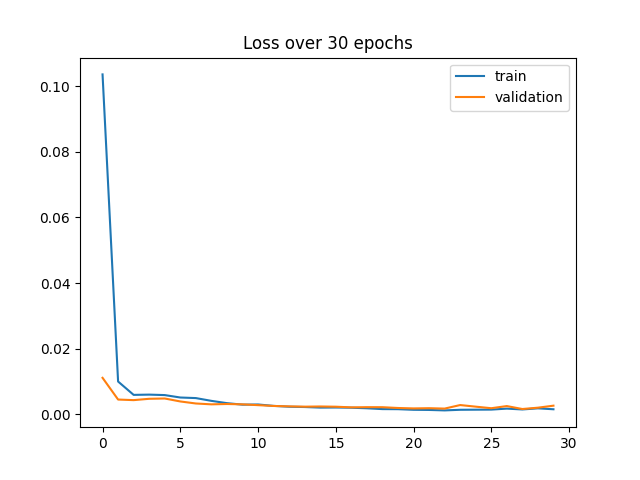
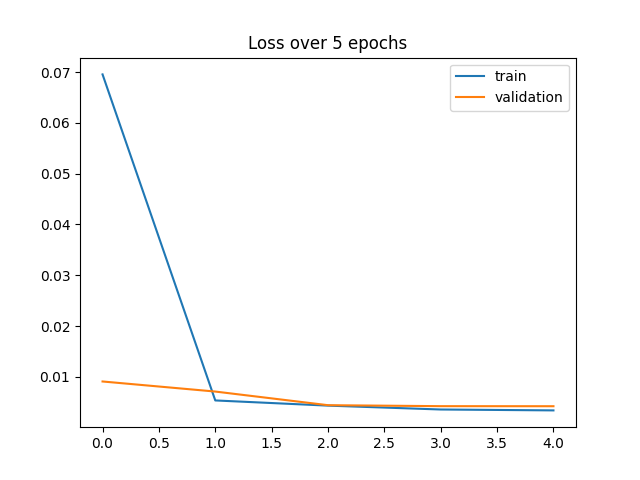
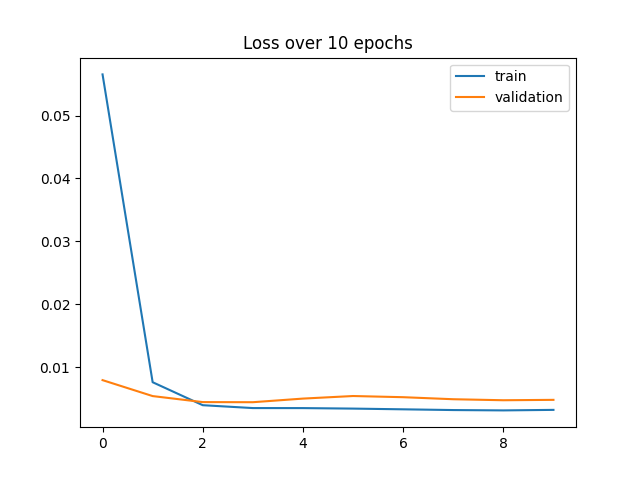
The hyperparameters I ended up using were 30 epochs, and a learning rate of 1e-4. I tried different learning rates, and different numbers of epochs, whose loss graphs are also shown below, but I mostly looked at what the results looked like on the pictures to determine the best parameters. I also used the actual loss numbers rather than the graph to determine which hyperparameters were best
|
|
|
|
|
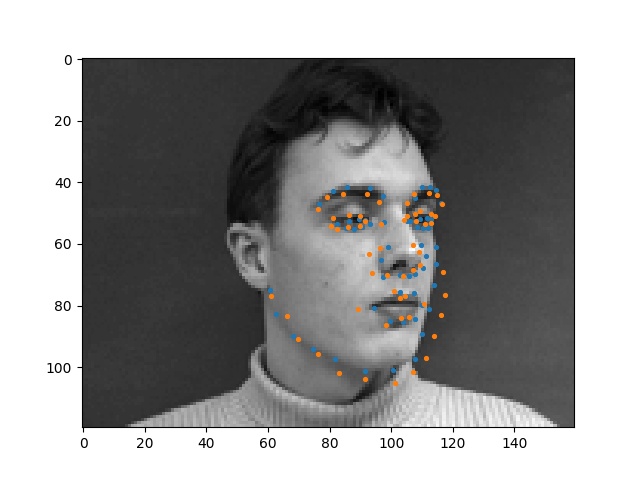
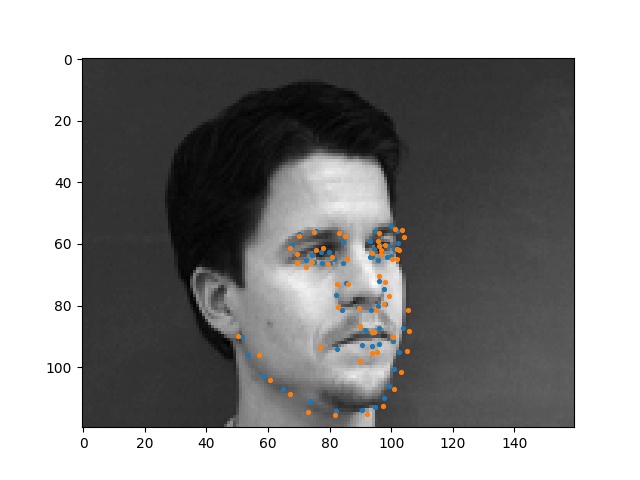
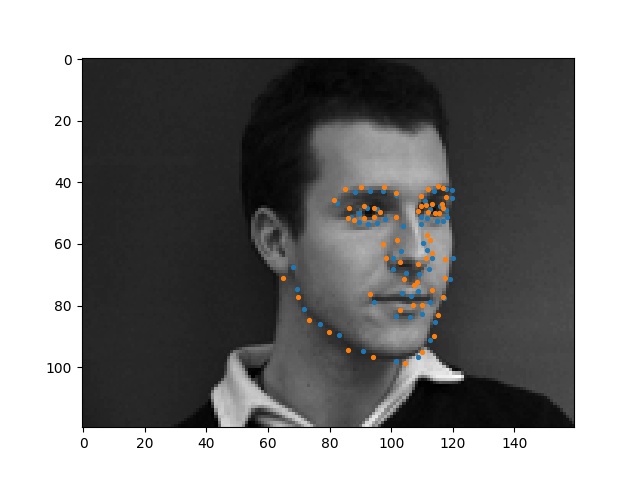
Here are some faces that my model performed well on.

|
|
|
|

|

|
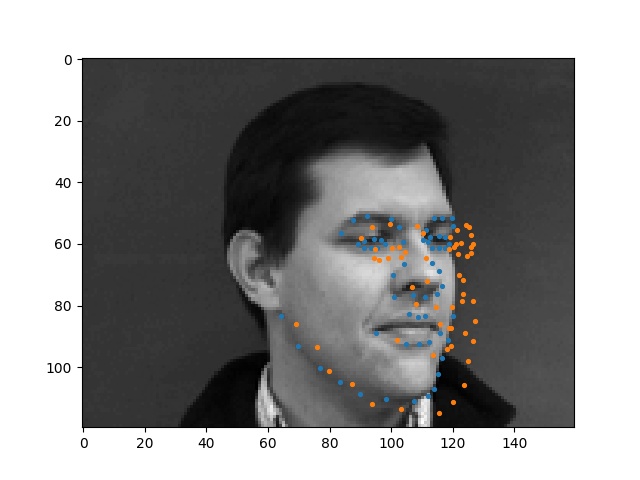
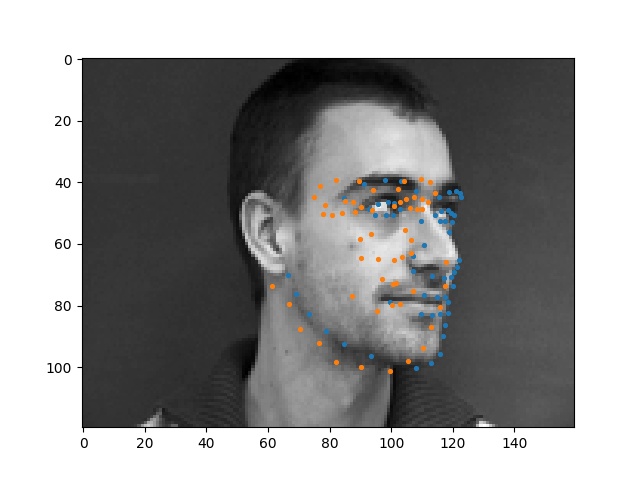
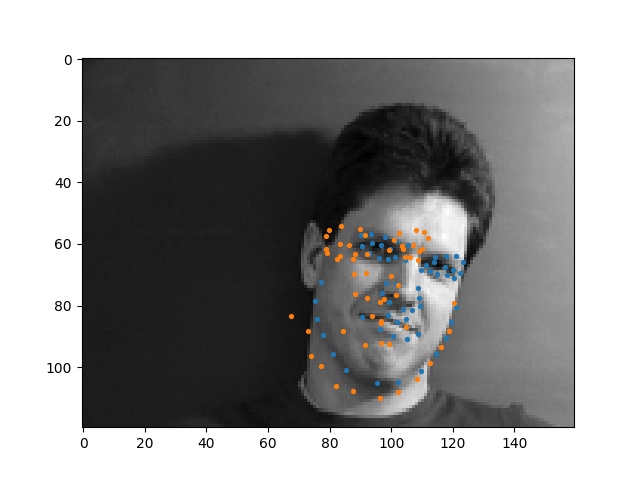
Here are some faces that my model just couldn't figure out. I think my model failed here because these people had their faces turned in ways that were unusual (face is at a weird angle), so my model did not know how to interpret this.
|
|
|
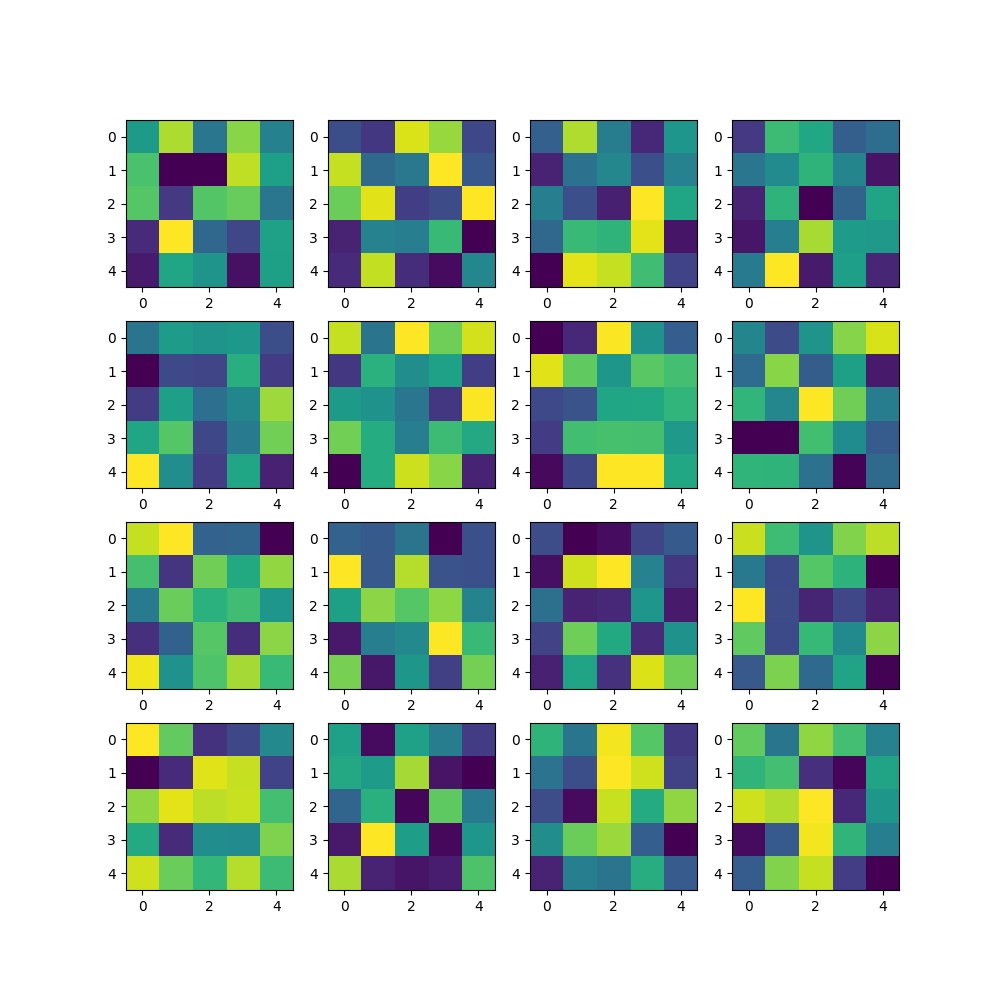
Here are the filters for my first convolutional layer after training.
|
To be honest I expected my Kaggle Score to be really bad which it kind of is but it could be worse. My score is 43.04827.
For this part of the project, I decided to use resnet18 as my model. I just changes the last fully connected layer so that it outputs 136 so we get the right number of points. Here are the details of the model.
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
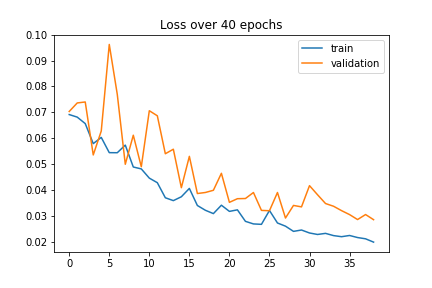
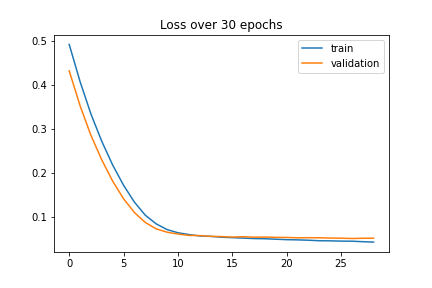
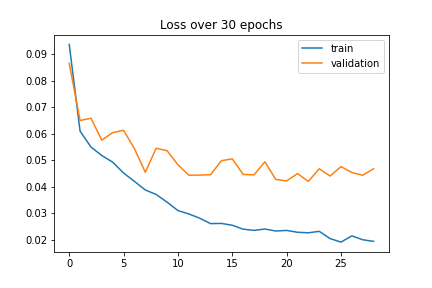
For training, I decided to use L1 loss to help prevent overfitting. I chose to do 50 epochs and decided on a learning rate of 1e-3 since this gave me the best results when I tried other learning rates. I included graphs below to show how the learning rate changed the loss. A learning rate of 1e-5 was over fitting on my training data, so I increased the learning rate.
|
|
|
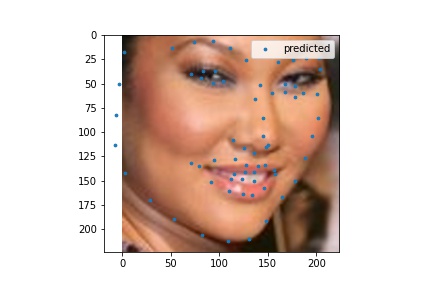
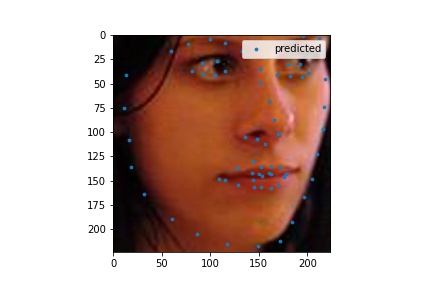
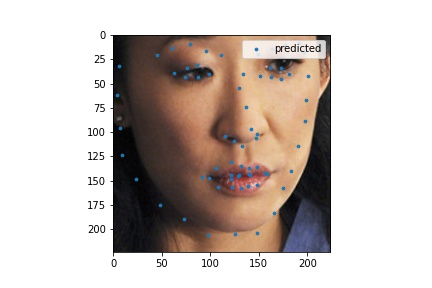
Here are some of the decent test set predictions.
|

|
|
|
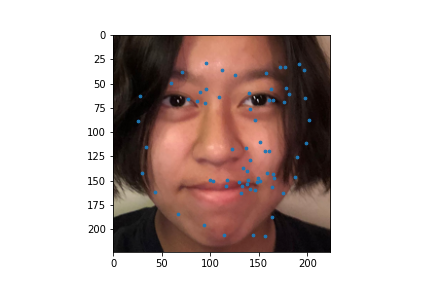
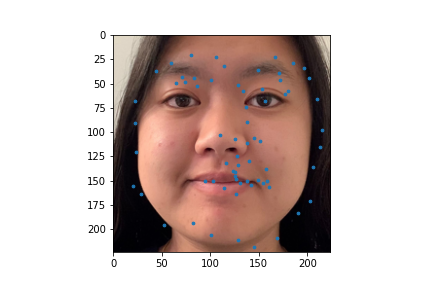
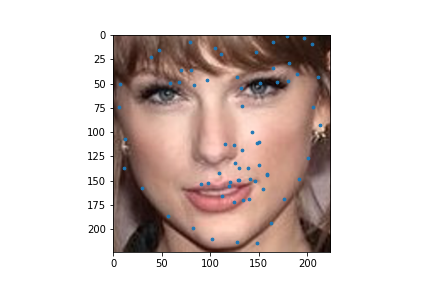
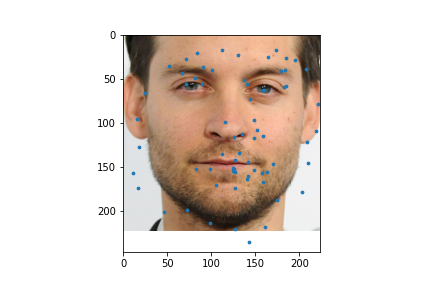
I used my model on some faces. The model works best on faces that are turned to the right slightly. This is probably because most of the images in the training set are facing that way. I could help account for this by adding random horizontal flips. Adding random rotations will probably help with this too. The model performs the worst on faces that are facing left for the same reason.
|
|
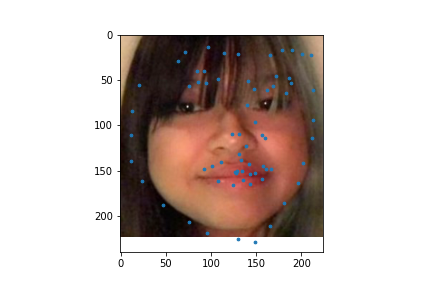
|
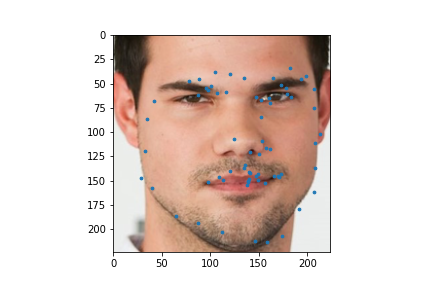
|
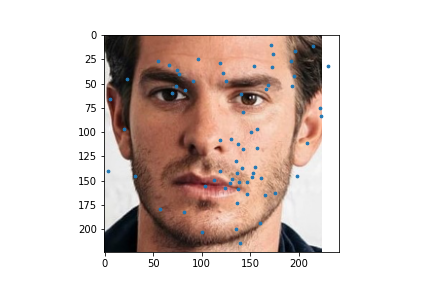
|

|
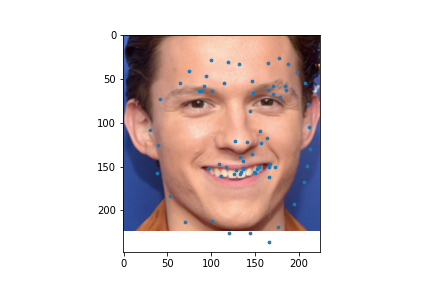
|
|
|