Project 5: Facial Keypoint Detection with Neural Networks
Part 1: Nose Tip Detection
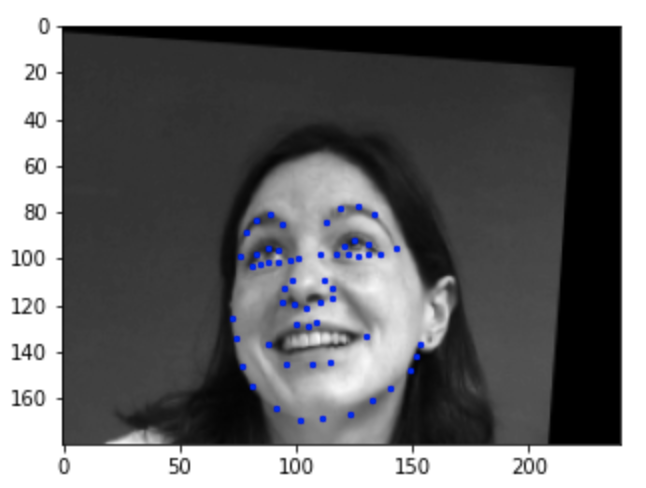
Below are the ground truth labels. The nose keypoints are labeled in red.
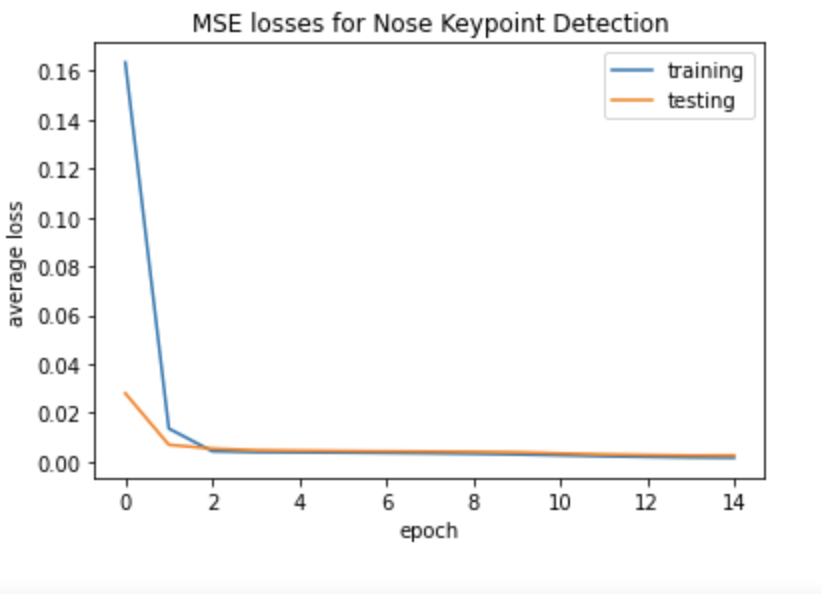
MSE losses for training with 15 epochs on the following CNN.
Below are the results of the test set predictions. Blue is the ground truth and red is the CNN prediction.
Bad predictions:
I think the left image failed because the eye corner is really dark, so it's similar to the shadow below the tip of the nose.
I think the right image failed because the face was turned to the side. There are a lot more front facing images in the train set
than faces turned to the side.
Part 2: Full Facial Keypoints Detection
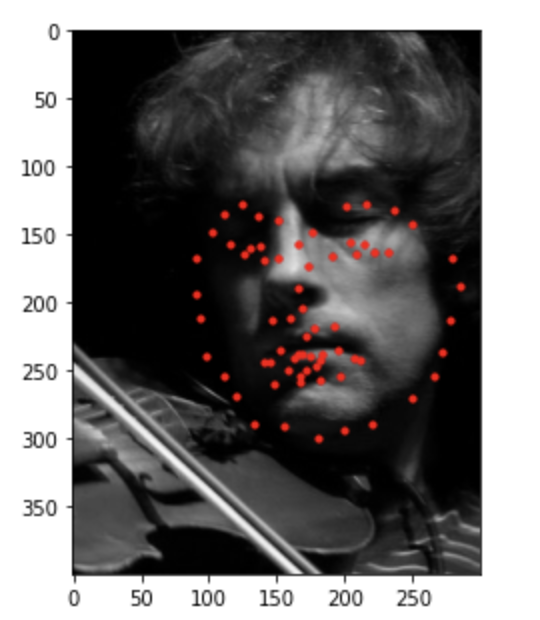
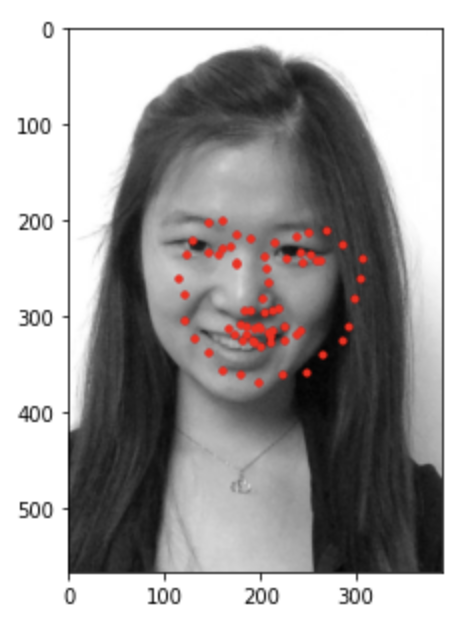
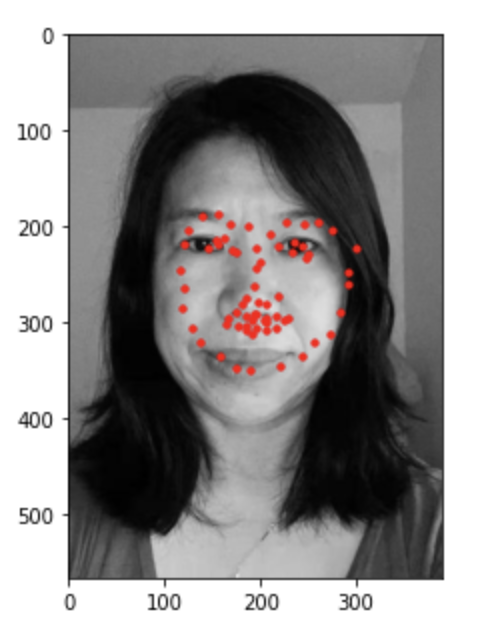
Below are the ground truth labels.
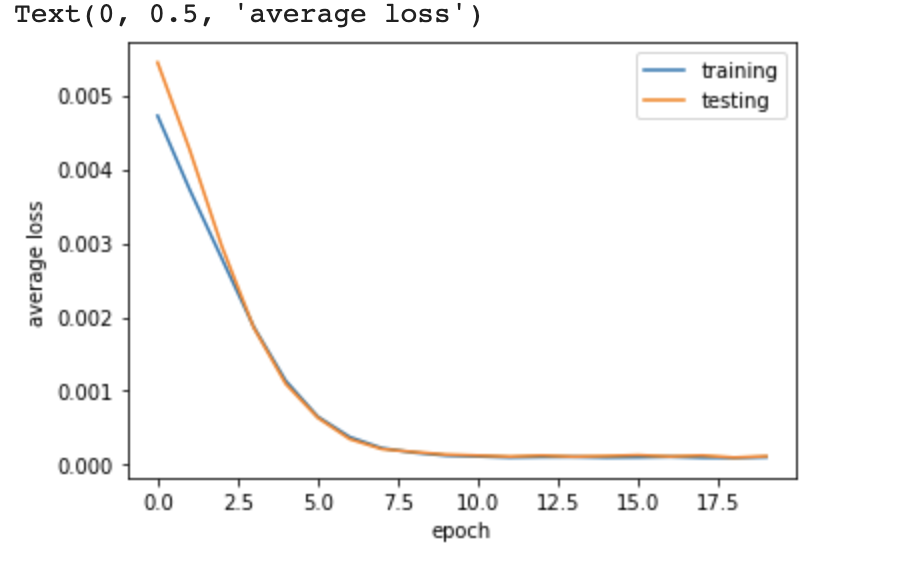
MSE losses for training with 20 epochs on the following CNN, with the Adam optimizer and a learning rate of 0.001.
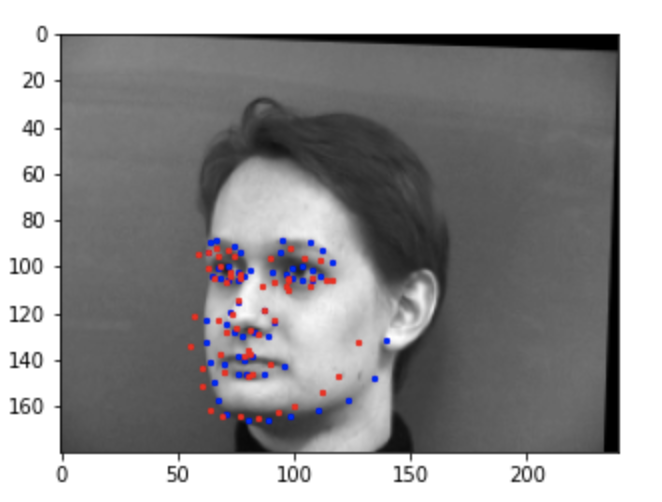
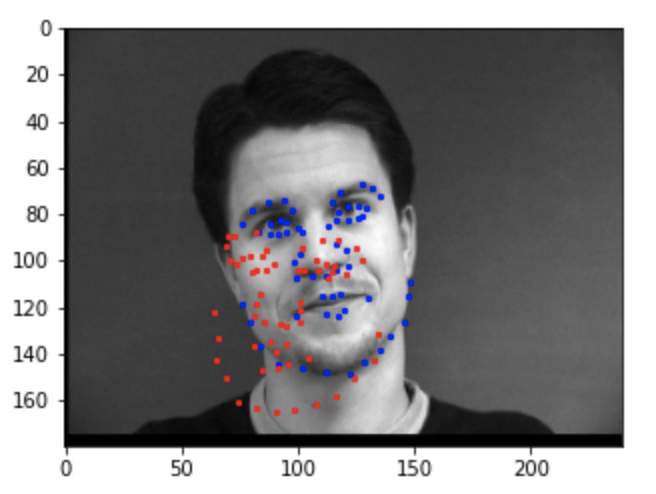
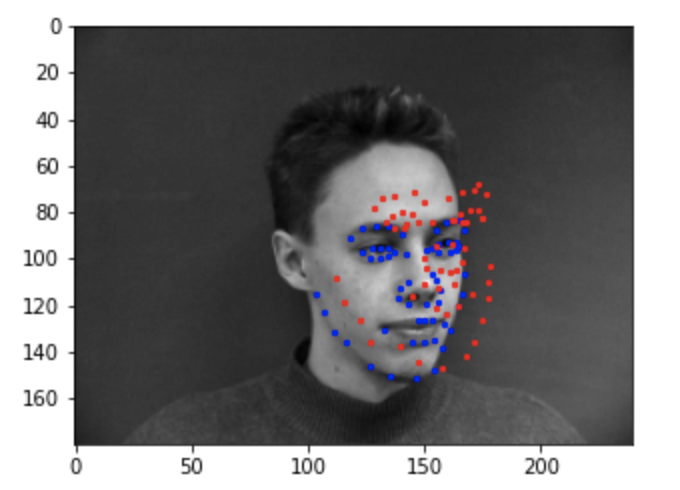
Below are the results of the test set predictions. Blue is the ground truth and red is the CNN prediction.
Bad predictions:
I think the left image failed because the head was slighted tilted to the side, and the network was confused thinking the entire
image had been rotated. I think the right image failed because the head was turned to the side, and there weren't enough
training images with the head turned.
Below are the learned filters for the first convolution layer.
Part 3: Train with Larger Dataset
Kaggle Score: 105.66947
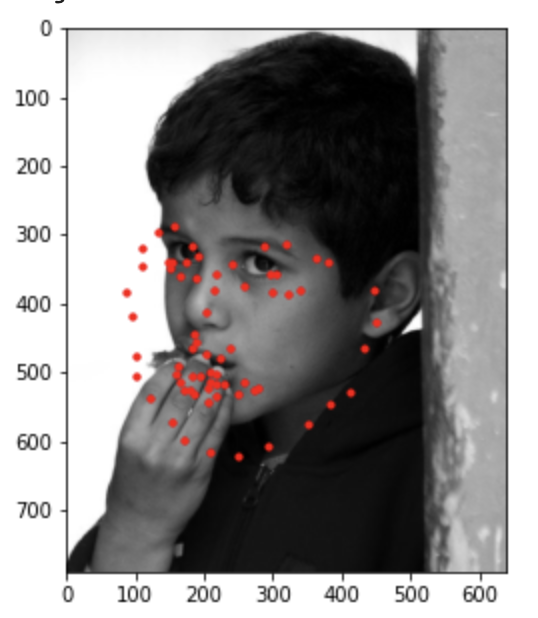
Below are the ground truth labels.
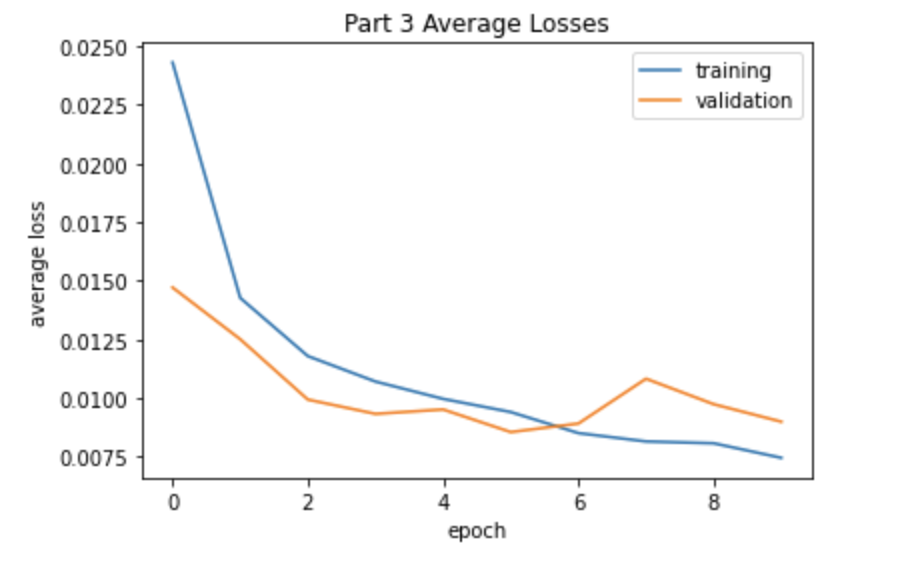
MSE losses for training with 10 epochs on the following CNN, with the Adam optimizer and a learning rate of 0.001.
QuantizableResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): QuantizableBasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
(1): QuantizableBasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
)
(layer2): Sequential(
(0): QuantizableBasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
(1): QuantizableBasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
)
(layer3): Sequential(
(0): QuantizableBasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
(1): QuantizableBasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
)
(layer4): Sequential(
(0): QuantizableBasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
(1): QuantizableBasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(add_relu): FloatFunctional(
(activation_post_process): Identity()
)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
(quant): QuantStub()
(dequant): DeQuantStub()
)
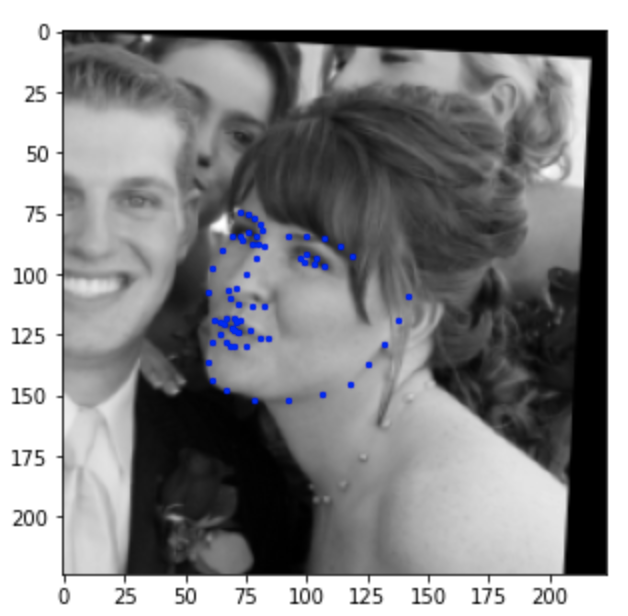
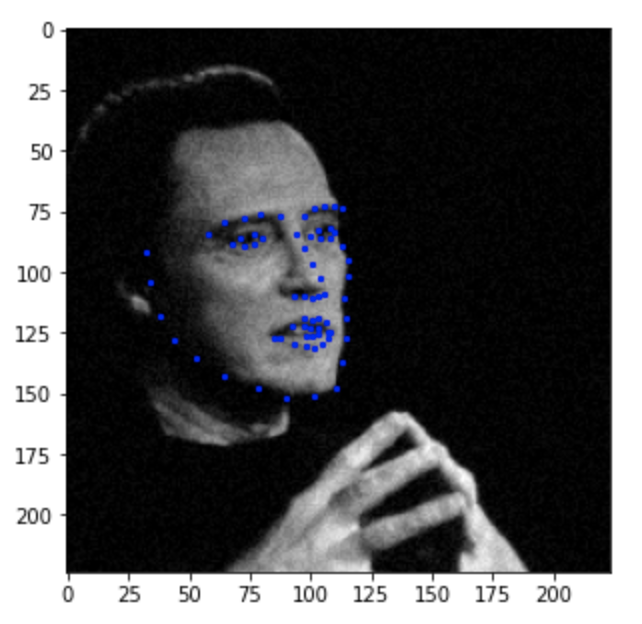
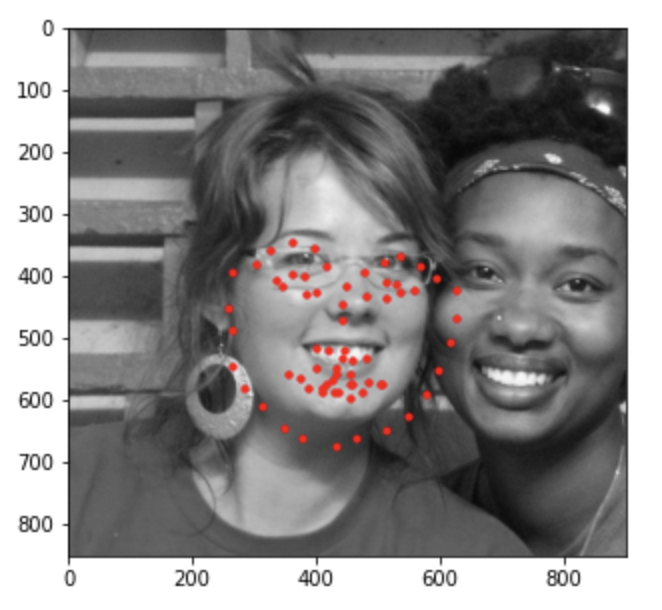
Below are the results of the test set predictions.
Good/Mediocre predictions:
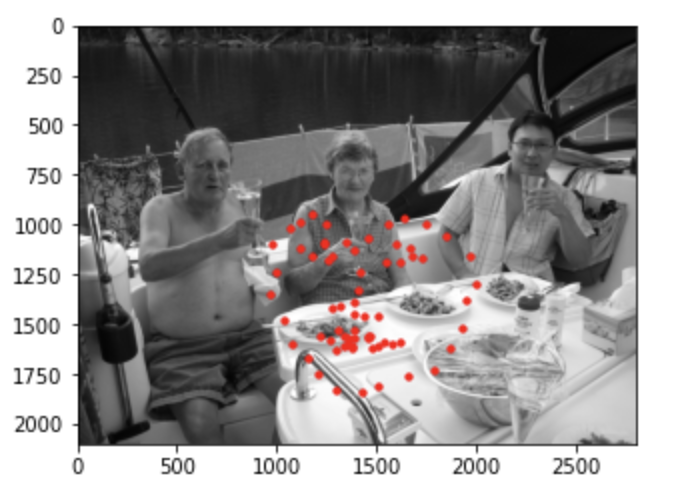
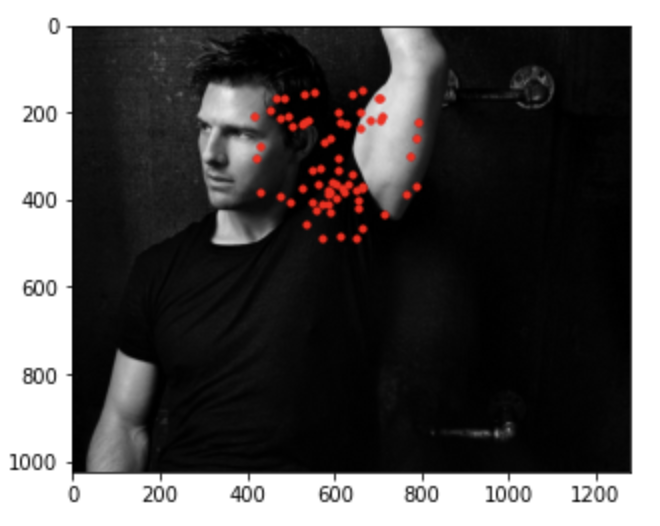
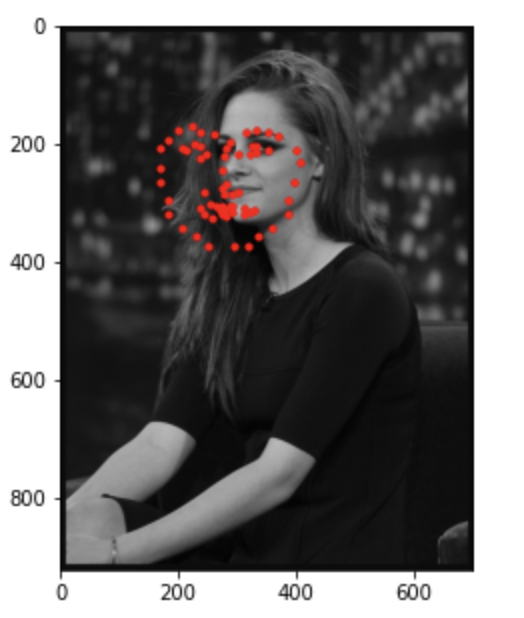
Below I've visualized the result of running the trained model on photos from my collection.