Facial Keypoint Detection with Neural Networks
CS 194-26 | Project 5 | Catherine Gee
I use net to do the work for me
Part 1: Nose Tip Detection
First we predict nose tips. We load the data
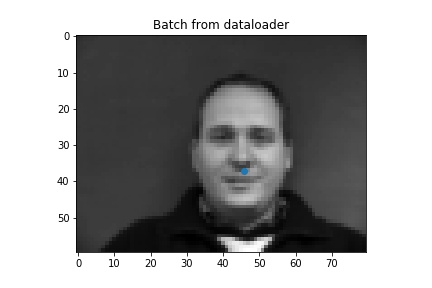
Nose1
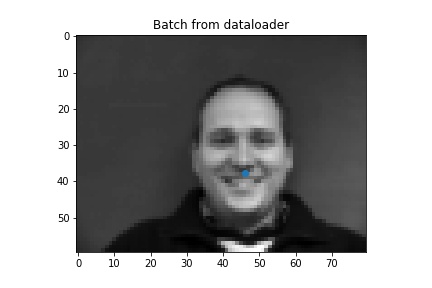
Nose2
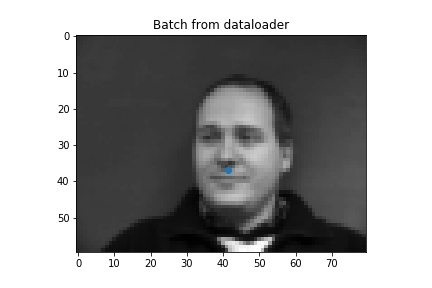
Nose3
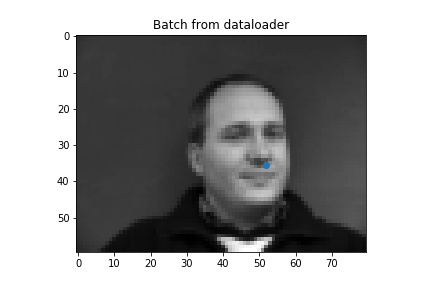
Nose4
Then we write the net with lr=1e-3 and 25 epochs
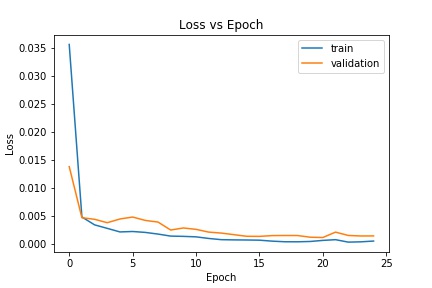
Loss of this model
Net( (conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1)) (conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=2560, out_features=128, bias=True) (fc2): Linear(in_features=128, out_features=2, bias=True))
I chnaged some parameters and it made my outputs worse... but first here are some ouputs. Some of these worse ones usually had a head titled to a side, so maybe my model did not like the lack of heads tilted to a side in the data.
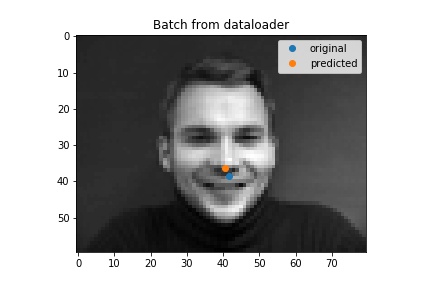
Good Result
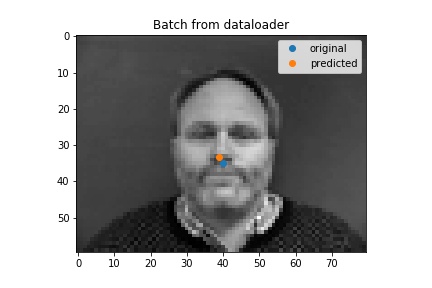
Good Result
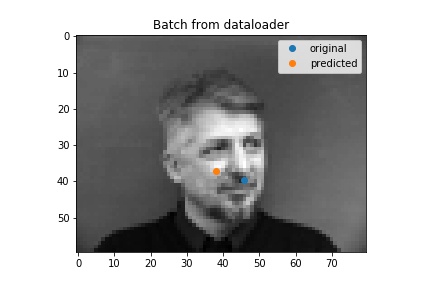
Bad results
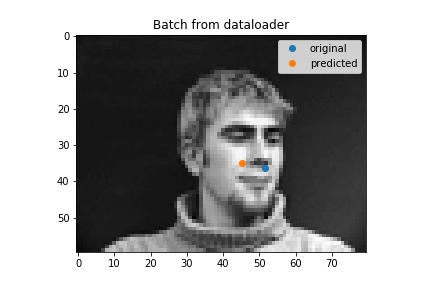
Bad result
When I changed some parameters (lr=1e-4 and epochs=10) this is what happened. It's still wrong but just a little more wrong.
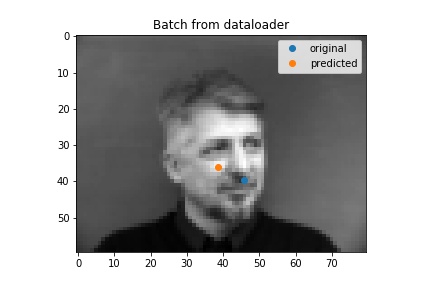
Bad results
Full Facial Keypoint Detection
Instead of 1 point we use 58
We load the data
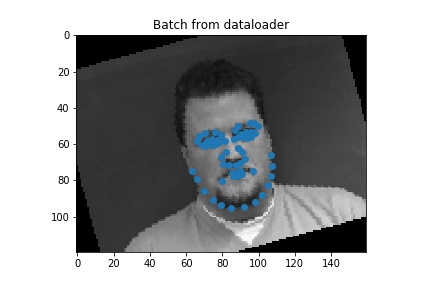
Nose1
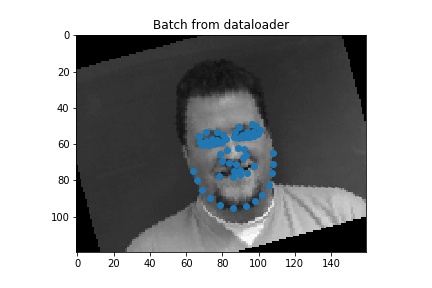
Nose2

Nose3
Then we write the net with lr=1e-3 and 50 epochs using MSE Loss and Adam optimizer with a batch size of 8. I also augemnted the data by rotating randomly and using color jitter.
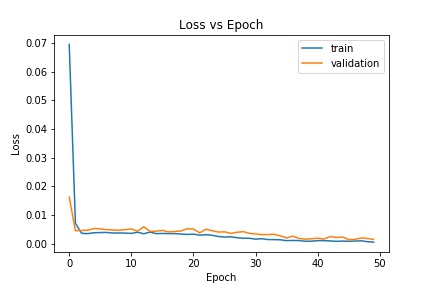
Loss of this model
FaceNet( (conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)) (conv3): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1)) (conv4): Conv2d(96, 128, kernel_size=(3, 3), stride=(1, 1)) (conv5): Conv2d(128, 160, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=6400, out_features=512, bias=True) (fc2): Linear(in_features=512, out_features=116, bias=True) )
Here are some outputs for my full face model. I think the ones that aren't too good the model would latch onto something and more or less just put a regular face down (sometimes this is not actually on the face) so in some cases turning the head was not good.
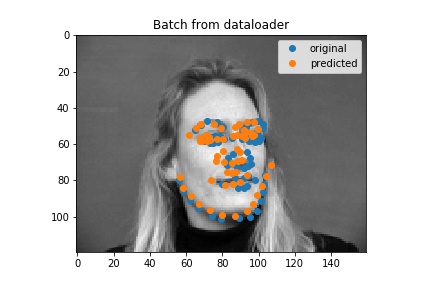
Good Result
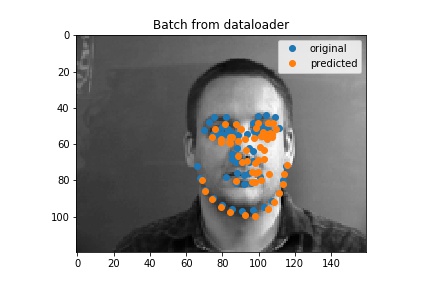
Good Result
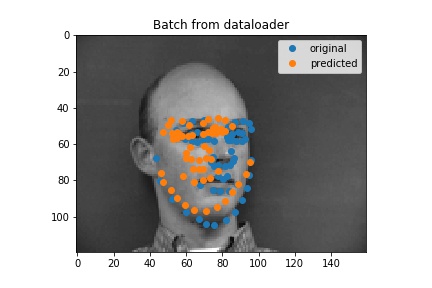
Bad results
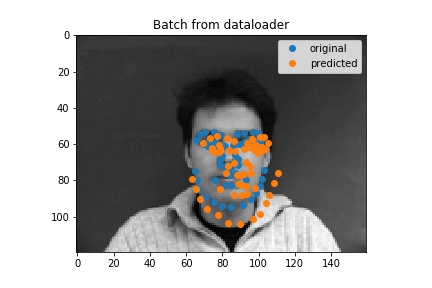
Bad result

conv1 filter
THE FINAL PART!!!! BIG DATA
So now we do the same thing but this time it's on abig dataset
We load the data
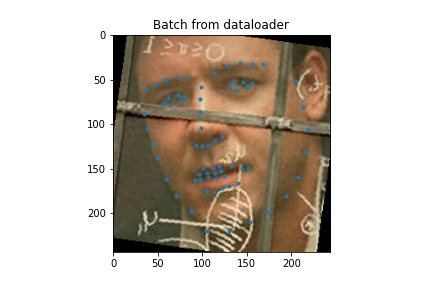
ground truth 1
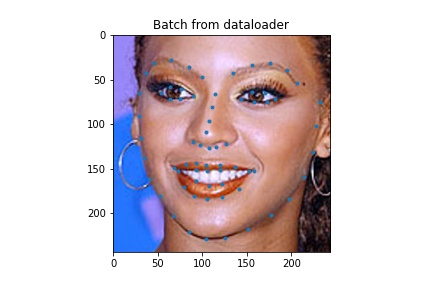
ground truth 2
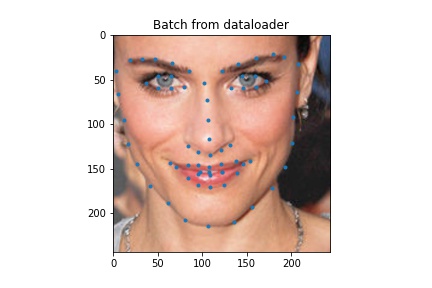
ground truth 3
Then we use resnet50 (with the last fully connected layer edited) with lr=1e-4 and 20 epochs using SmoothL1Loss and Adam optimizer with a batch size of 64. I also augemented the data the same as above.
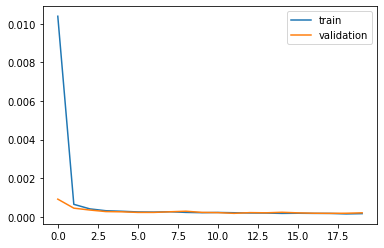
Loss of this model
hello if you want to look at the layers you should go here
Here are some outputs for my full face model. I think the ones that aren't too good the model would latch onto something and more or less just put a regular face down (sometimes this is not actually on the face) so in some cases turning the head was not good. My MAE was 37.82058 which is probably not that good.
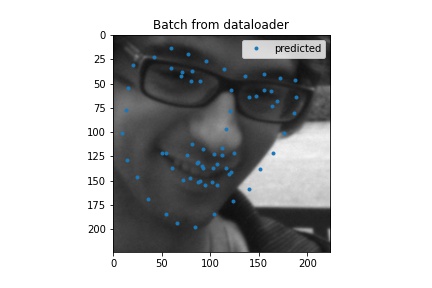
Test output example
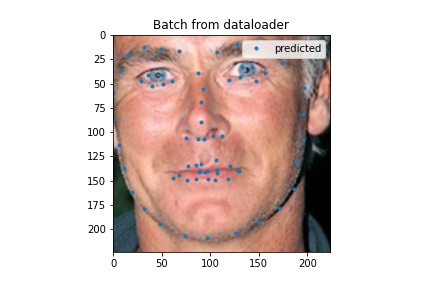
Test output example
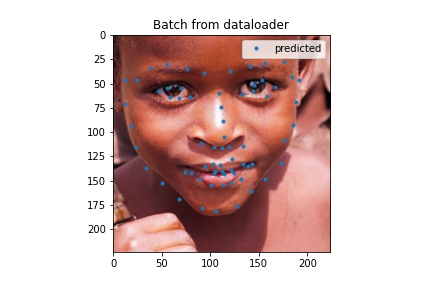
Test output example
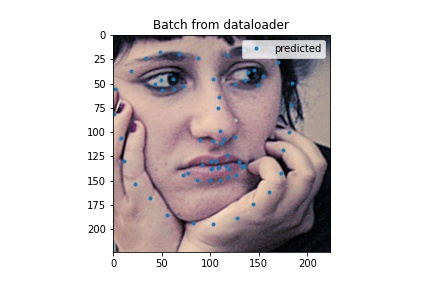
Test output example
below, with the last dregs of my sanity i ran my model using some of my very own inputs. its not too good for this first one here likely because her hair is covering half her face (the angle also doesn't help). I still like the show though. stream arcane

Vi from the HIT NETFLIX SHOW ARCANE!!!!
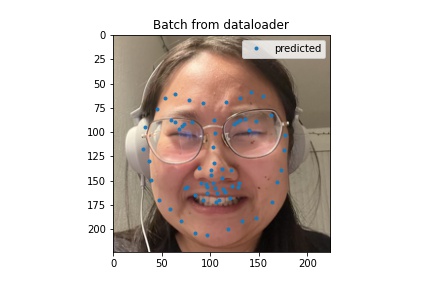
This is me
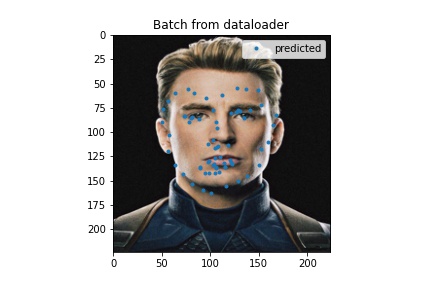
WOOOO CAPTAIN AMERICA!!!