Facial Keypoint Detection with Neural Networks
COMPSCI 194-26: Computational Photography & Computer Vision
Professors Alyosha Efros & Angjoo Kanazawa
November 12, 2021
Ethan Buttimer
Overview
Using a convolutional neural network (CNN), I built a model that predicts up to 58 facial keypoints (such as the tip of the nose and corners of the lips) based on an input image. I used PyTorch as my main machine learning framework, and started with a small dataset of face images and keypoints from the IMM Face Database for training and validation. To achieve a low loss while preventing overfitting, I augmented this dataset with various image transformations (translation, rotation, scaling), and adjust hyperparameters such as the size of the hidden layers and the learning rate. Lastly, I trained a more complex model on a much larger dataset for the same facial keypoint prediction task.
Part 1: Nose Tip Detection


Above, I've shown two images and their ground-truth keypoints, sampled by my custom dataloader.
To get started, I restricted the model to only predicting the 2D location of the tip of the nose, based on a small (60x80 pixel) image. The CNN itself contained three convolutional layers, each with 16 or 32 channels and a max-pooling step, as well as a flattening step and two fully connected layers. All layers (except the last) used ReLU as the nonlinearity.
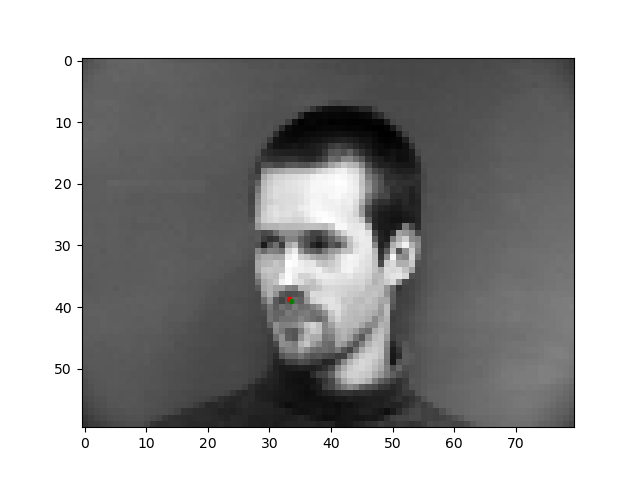

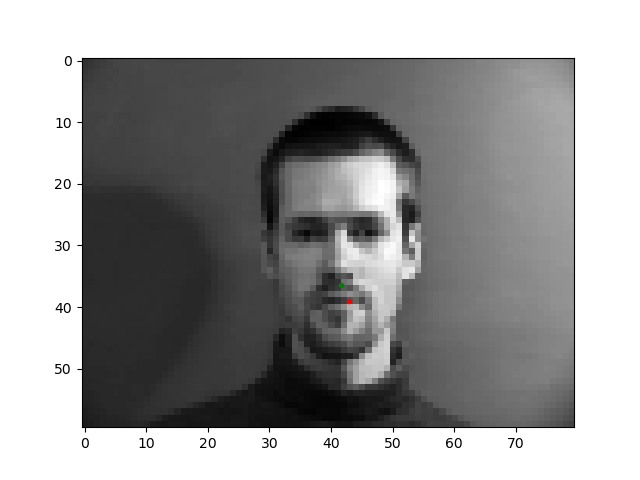

In the images above, the green point shows the ground-truth, while the red point is the prediction. The first row shows two images in which the trained model predicts this keypoint accurately. The second row shows two images on which the model was not as successful. The model performed relatively poorly on images in which the subject rotated their head, possibly because the subjects were not consistent in the amount of rotation and therefore there was less training data closely resembling these cases. Also, mustache and shadowing in the bottom left image could have 'confused' the model.
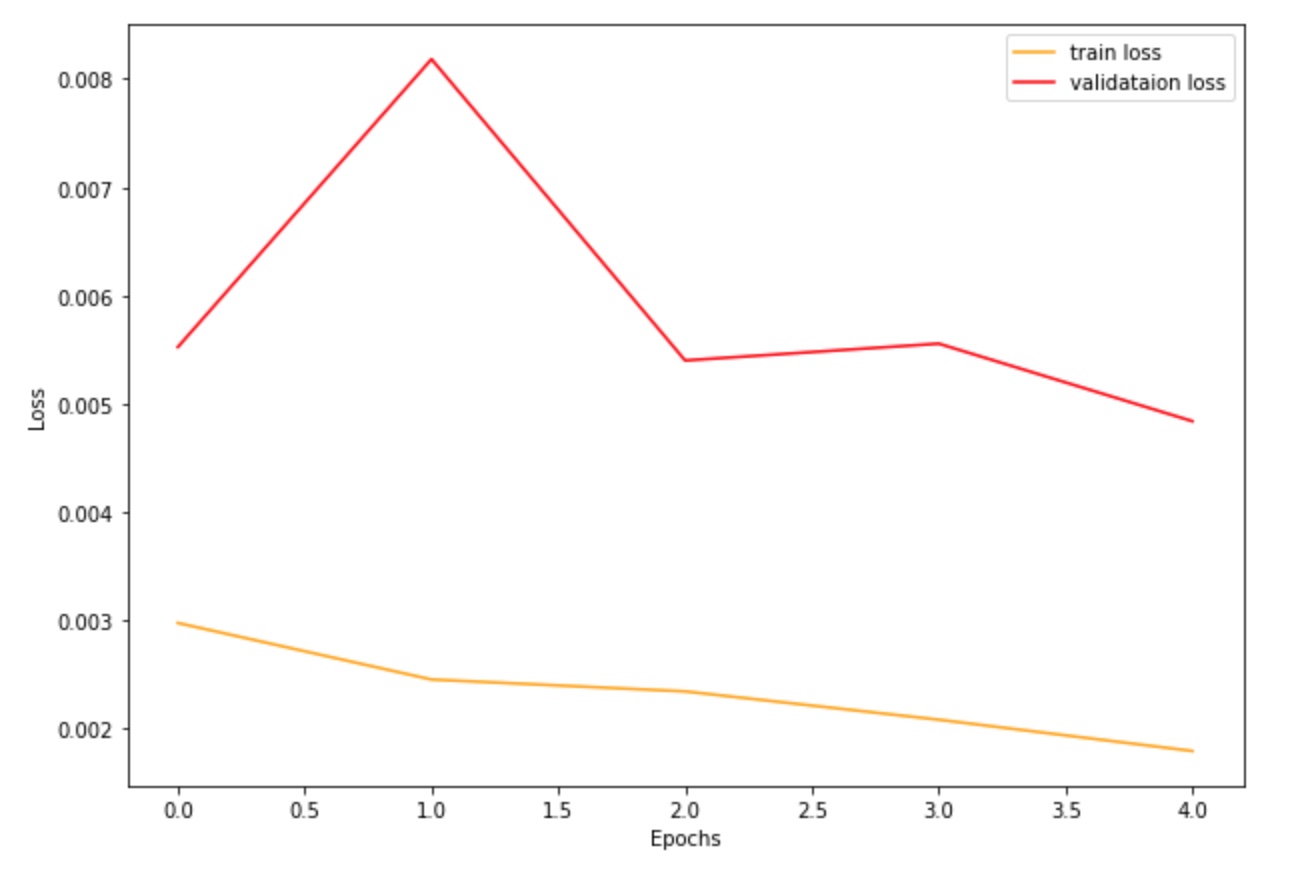
Finally, the graph above shows the training and validation loss at each epoch during training. The loss metric used was mean squared error (MSE).
Part 2: Full Facial Keypoints Detection
Moving on to detection of all 58 keypoints, I used larger (120x160 pixel) images, along with a deeper network. The new CNN contained five convolutional layers and three fully connected layers. All convolution kernels had size 3x3 and step size. The number of channels per layer were the following, in order: 16, 32, 32, 16, 16. The learning rate was 0.001, the batch size was 4, and the number of epochs was 30. The images and keypoint data were augmented through rotation, translation, scaling, and color adjustment.
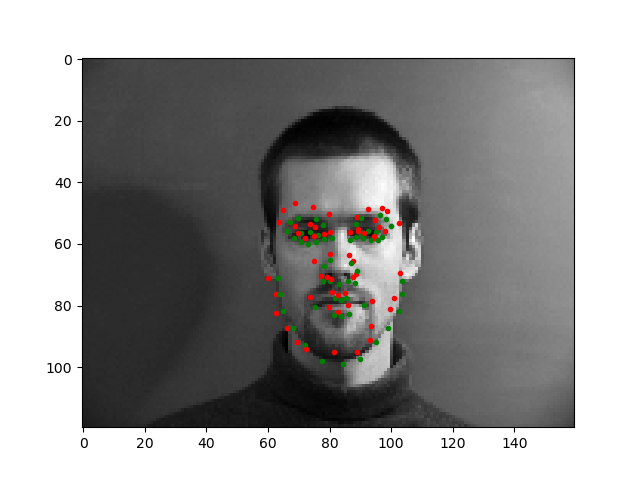

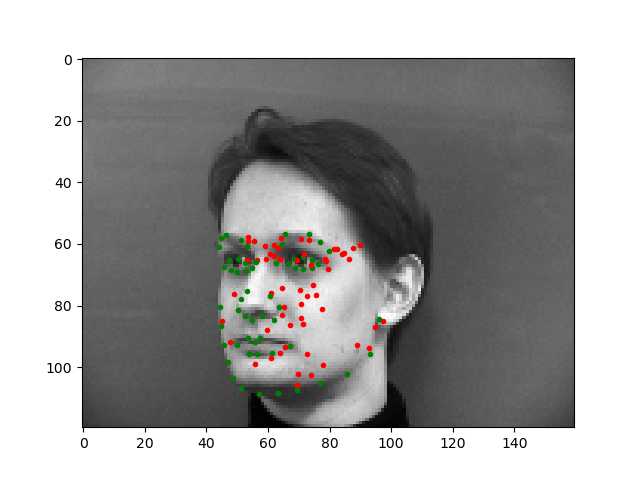
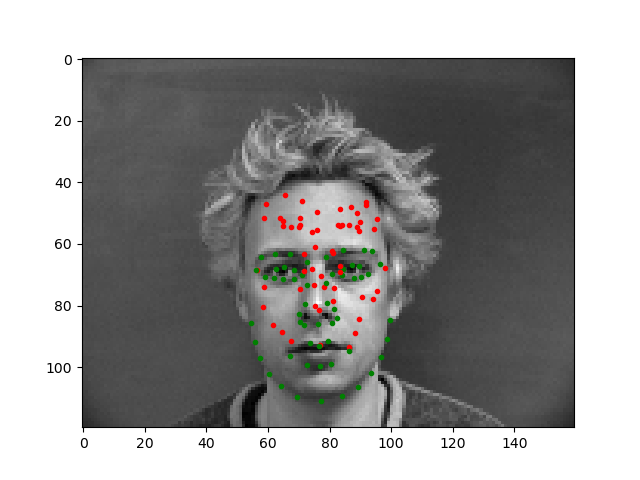
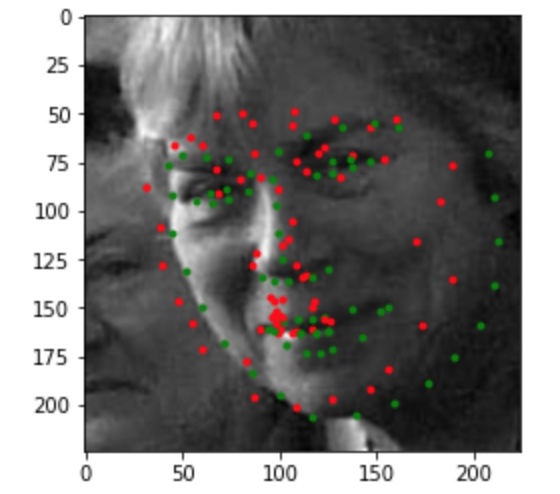
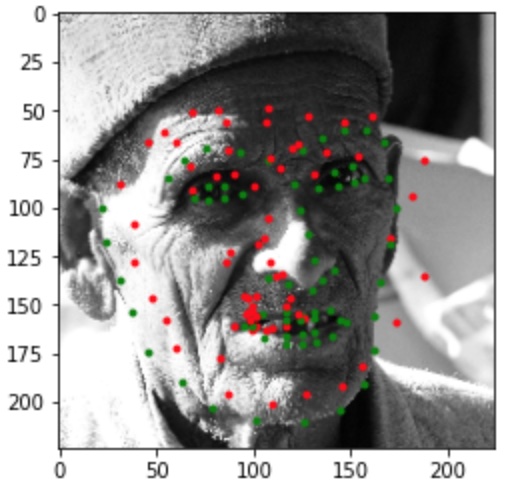
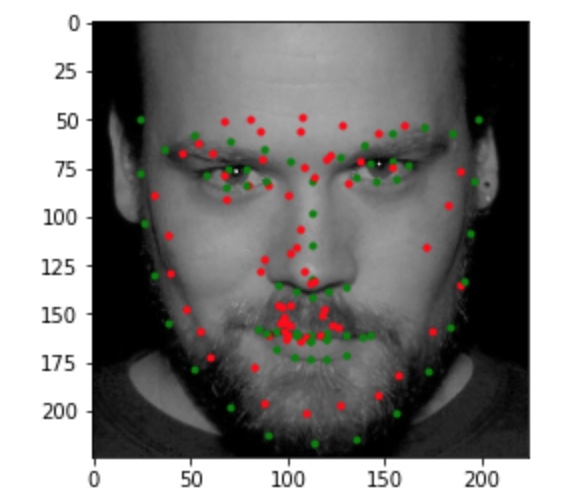
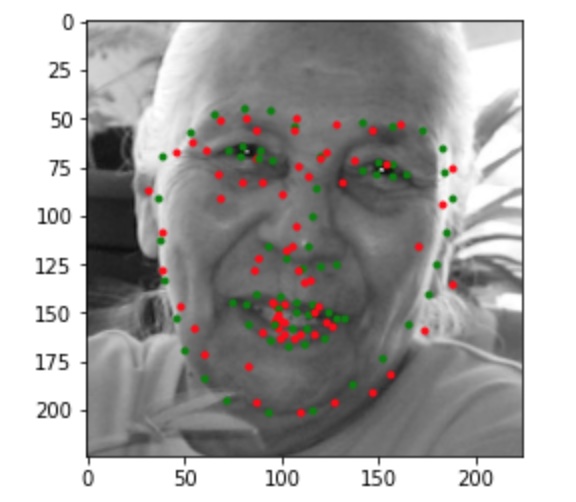
In the images above, the green points shows the ground-truth, while the red points are the predictions. The first row shows two images in which the trained model predicts this keypoints fairly successfully. The second row shows two images on which the model was not as successful. Once again, the model performed relatively poorly on images in which the subject rotated their head, possibly because the subjects were not consistent in the amount of rotation, resulting in less training data closely resembling these cases. For the last image, the model seems to have confused the lips for the chin since the head was low in the frame.
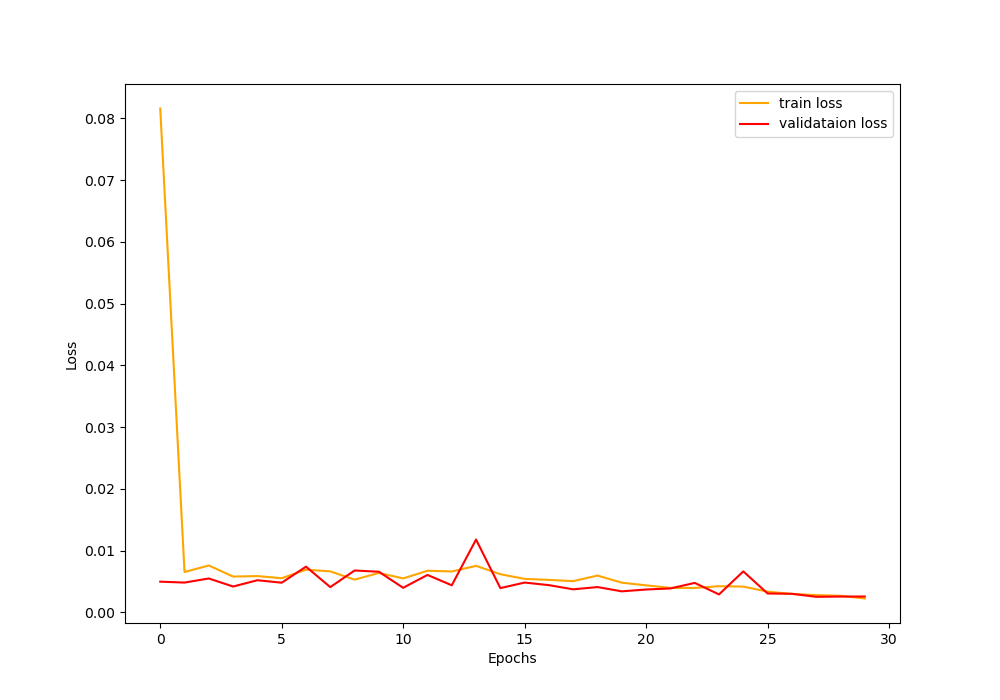
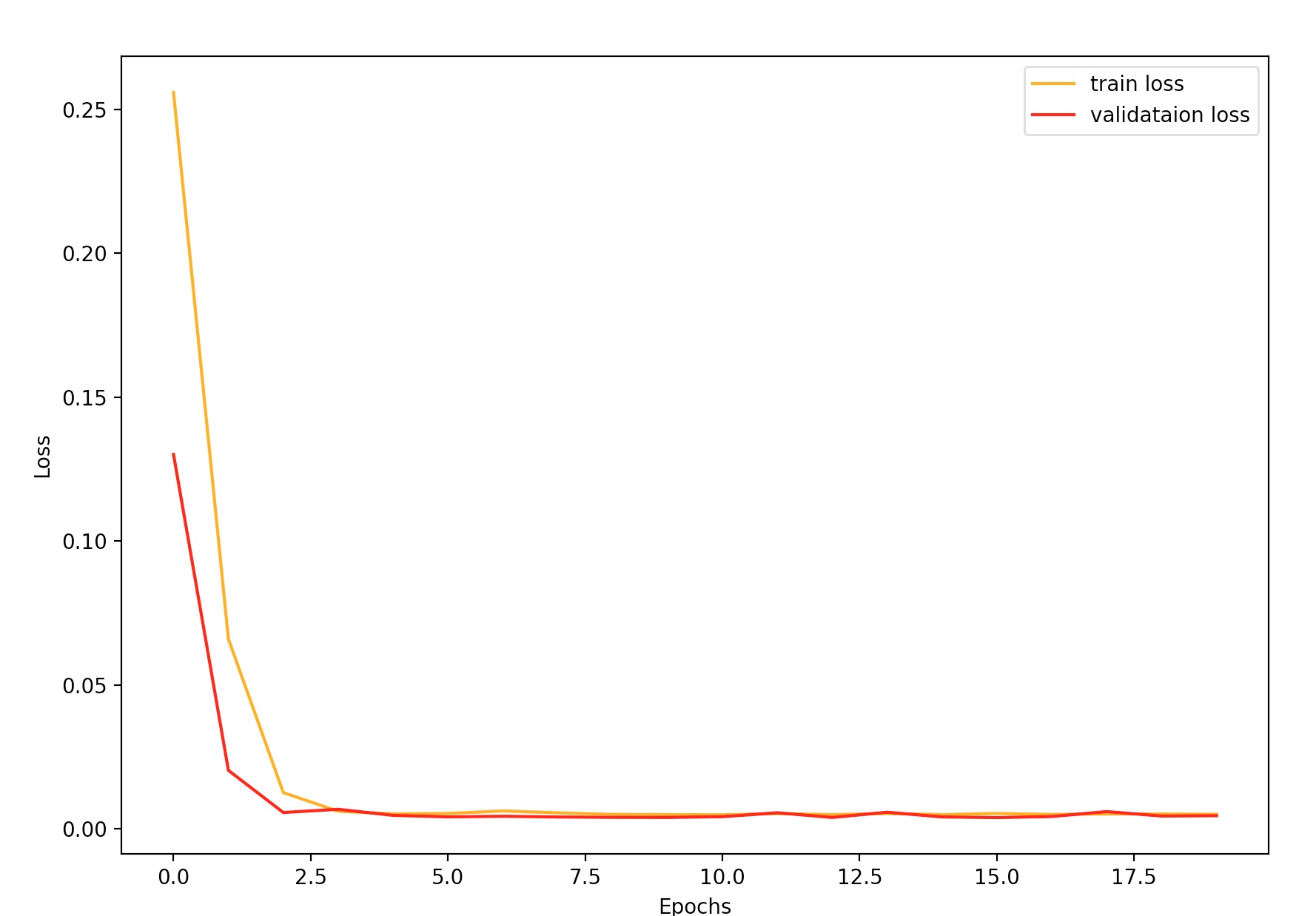
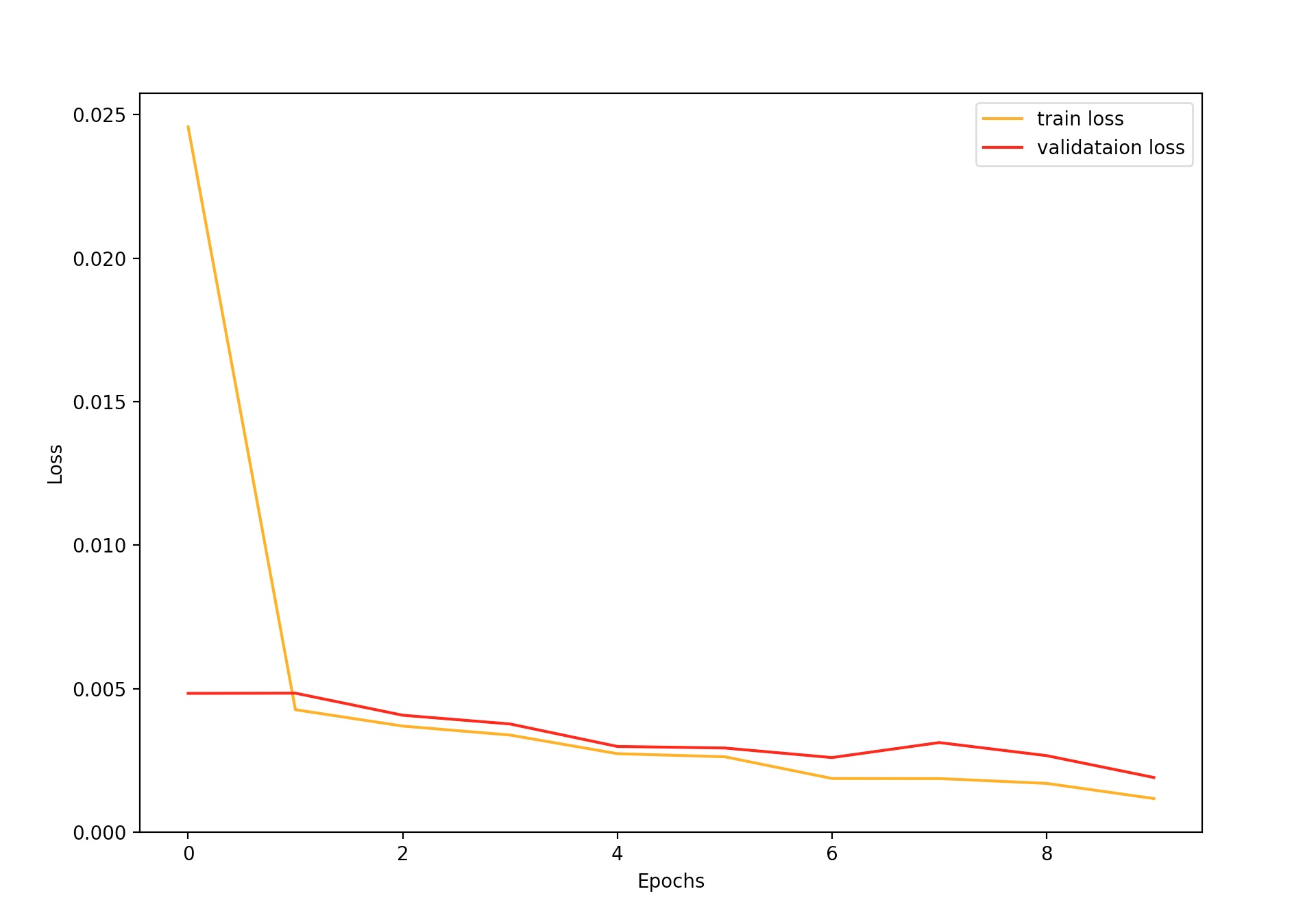
The graph above and to the left shows the training and validation error at each epoch during training. I've also included the graph for the loss when trained with a larger batch size of 10, which gave a smoother decrease in loss but ultimately settled on a higher loss value.
Lastly, I've visualized the 16 filters learned by the model at the first convolution layer.