CS 194-26: Project 5
For this project, we used neural networks to predict the location of facial keypoints.
Part 1: Nose Tip Detection
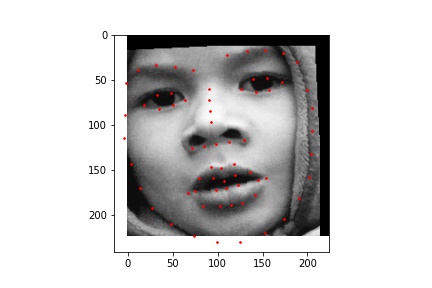
For this part, we were introduced to neural networks by creating a simple neural network to predict the location of the center nose keypoint.
Below are two images with the true nose keypoint along with other keypoints that are on the nose.
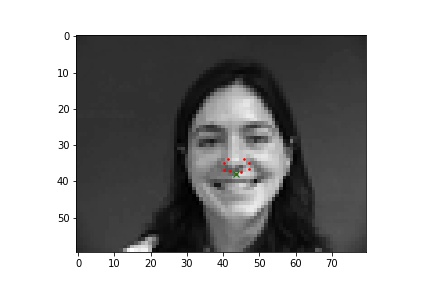
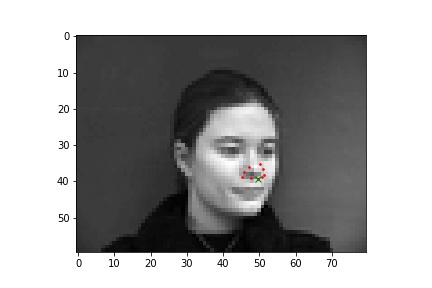
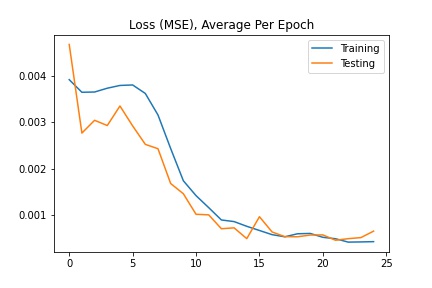
For this neural network, I used 4 convolutional layers and 2 fully connected layers with a training batch size of 24, learning rate of 0.01, and 25 epochs. The loss was calculated using MSE and the optimizer used the Adam optimizer.
Net(
(conv1): Conv2d(1, 8, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(8, 16, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(16, 24, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(24, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=64, out_features=32, bias=True)
(fc2): Linear(in_features=32, out_features=2, bias=True)
)
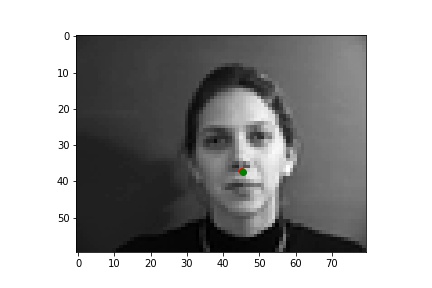
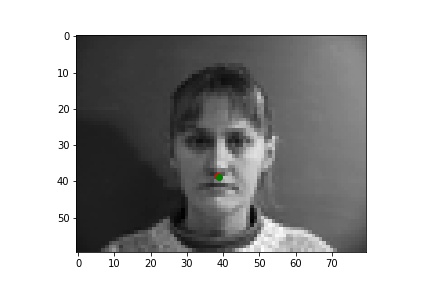
Two successful predictions of the nose keypoints where the green point is the true nose point and the red is the predicted nose point:
Two unsuccessful predictions of the nose keypoints where the green point is the true nose point and the red is the predicted nose point:
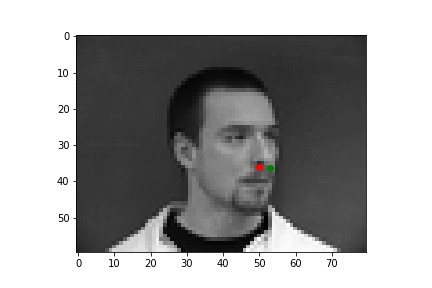
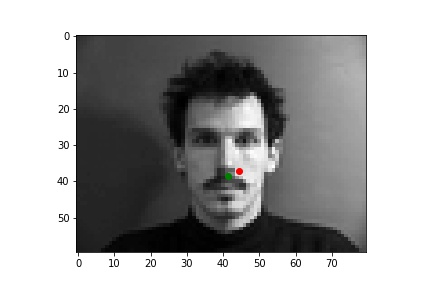
The first picture likely fails because the head is turned to the side. Since most of the training data is of faces looking directly at the camera, the neural net has a hard time finding the correct nose point for turned heads. The second picture likely fails because of the facial hair. The dark facial hair is not common in the sample, so the model mispredicts the nose point.
Part 2: Full Face Keypoints Detection
For this part, we moved to creating a model that predicts all 58 face keypoints.
Below are images sampled from the training set with the true face keypoints that has some augmentation done to them. The augmentation modifies the original image by rotating, translating, or changing the color properties to provide more data to the neural network when training.
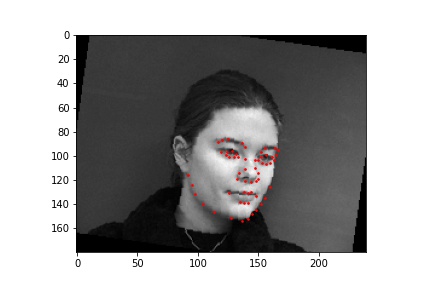
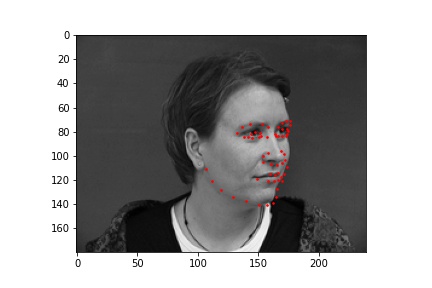
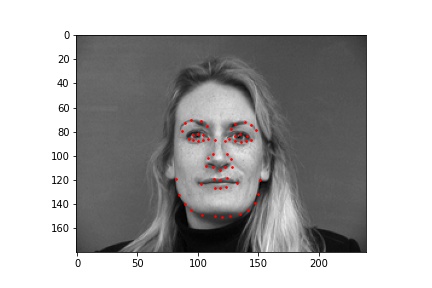
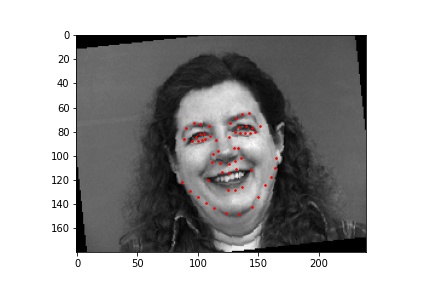
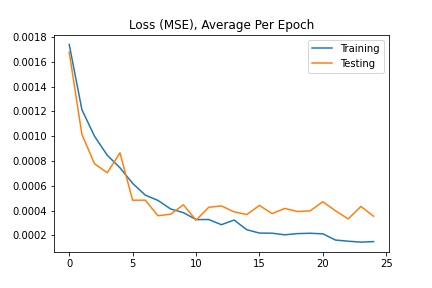
For this neural network, I used 6 convolutional layers and 2 fully connected layers with a training batch size of 24, learning rate of 0.001, and 25 epochs. The loss was calculated using MSE and the optimizer used the Adam optimizer.
CCN(
(conv1): Conv2d(1, 4, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(4, 8, kernel_size=(7, 7), stride=(1, 1))
(conv3): Conv2d(8, 16, kernel_size=(5, 5), stride=(1, 1))
(conv4): Conv2d(16, 24, kernel_size=(5, 5), stride=(1, 1))
(conv5): Conv2d(24, 32, kernel_size=(3, 3), stride=(1, 1))
(conv6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=256, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=116, bias=True)
)
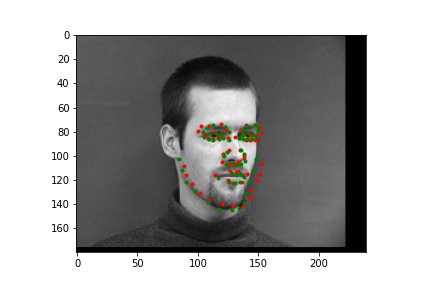
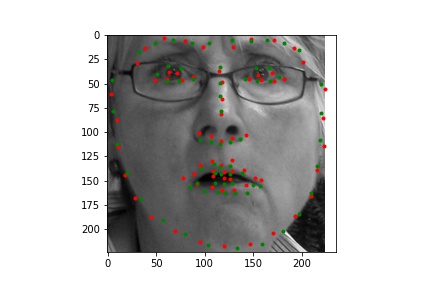
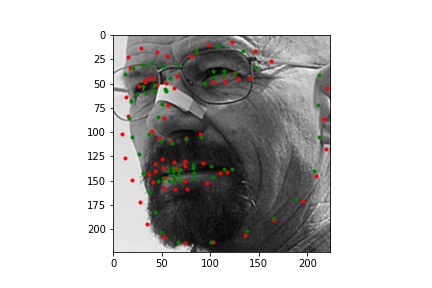
Two successful predictions of the face keypoints where the green point is the true nose point and the red is the predicted nose point:
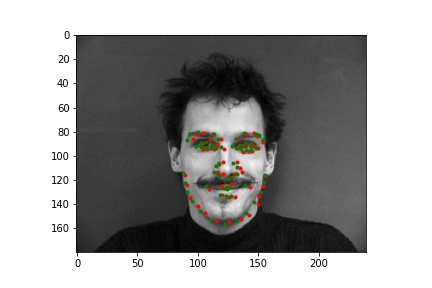
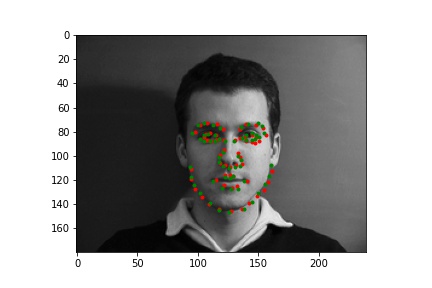
Two unsuccessful predictions of the face keypoints where the green point is the true nose point and the red is the predicted nose point:
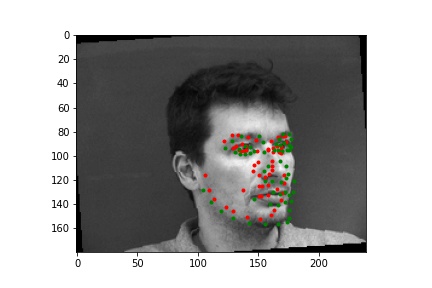
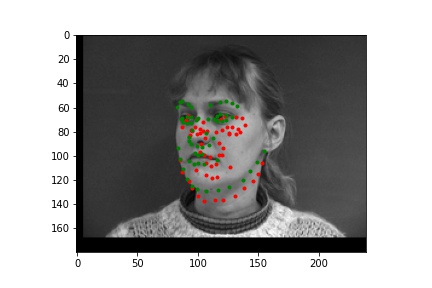
The two failed cases are likely primarily due to the turned head. You can see that the neural net predicted that the nose is off to the side of where it actually is, suggesting that it is only able to successfully predict face keypoints of faces that look directly to the camera.
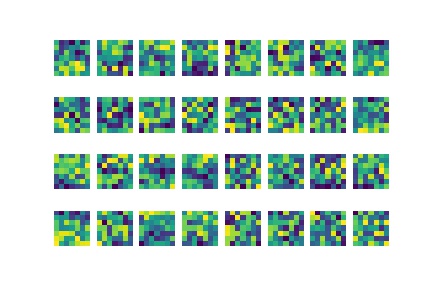
Below are the visualized learned filters for the first and second convolution layers of the face keypoint neural network:

Part 3: Train With Larger Dataset
For this part, we trained a neural network on a dataset of 6666 images of people in an uncontrolled environment. In order to train the model, we had to crop the image to the face to remove any extra information and augment the image to provide more data. We were given bounding boxes for the face and the points for the true face keypoints. However, since the bounding boxes often did not include all the keypoints, I instead used the min and max x and y values as the bounding box when training the neural net.
Below are sampled images from the dataset with the true face keypoints that has some augmentation done to them.
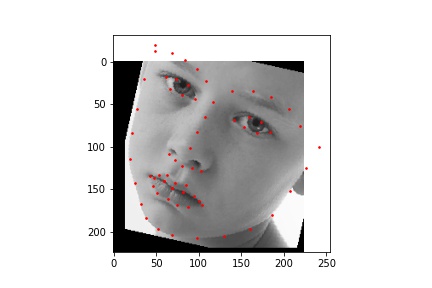
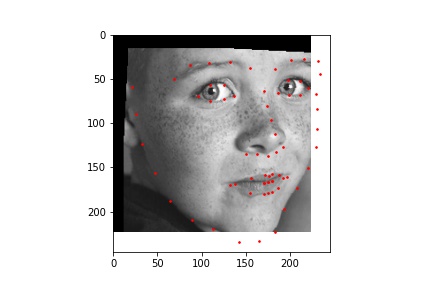

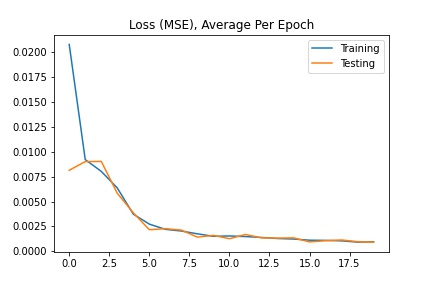
For this neural network, I used ResNet18 with a training batch size of 64, learning rate of 0.001, and 20 epochs. The loss was calculated using MSE and the optimizer used the Adam optimizer.
Net(
(model): ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
)
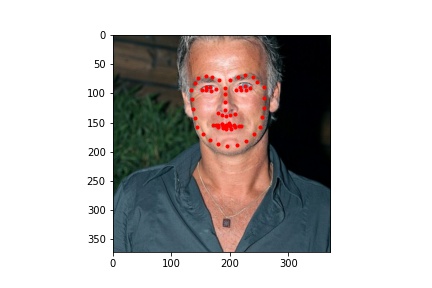
Below are images from the test sample with the predicted face keypoints in green and the true face keypoints in red:
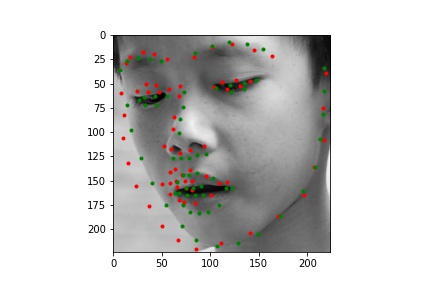
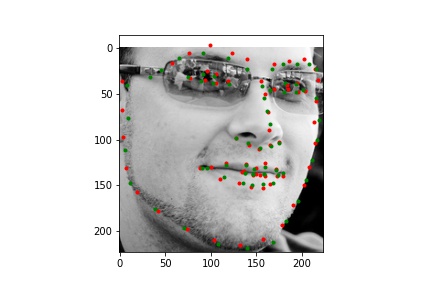
Below are images with the predicted face keypoints on top of the full image.
.jpg)
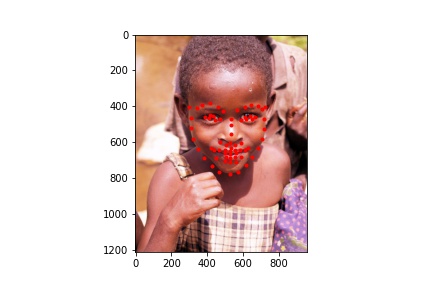
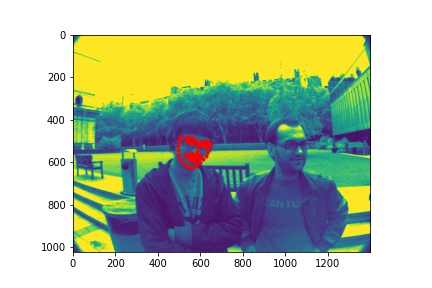
Below are some images I chose to predict face keypoints on:
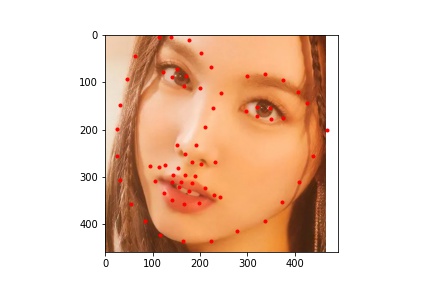
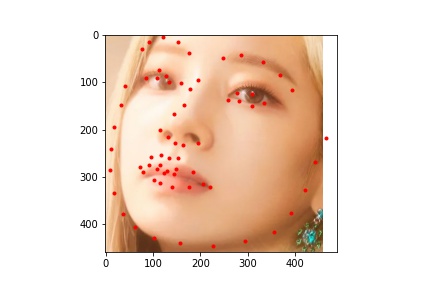
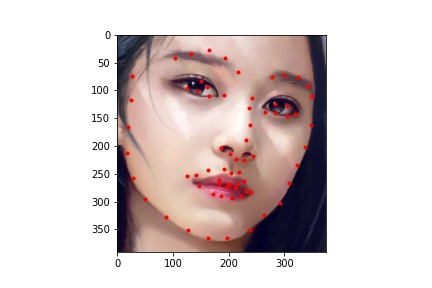
.jpg)
The neural network seems to handle most faces with no obstruction fairly well. It is able to predict the keypoints of turned faces better than the previous model. However, it struggles with uncommon facial expressions and other obstacles to the face. For example, in the image with the caption "predict 2", the boy has his hand to his mouth which covers part of his face, resulting in a less accurate prediction of the face keypoints. In the image with the caption "twice 4", the girl has glasses and is making an unusual facial expression which causes the model to mispredict the keypoints around her eyes and mouth.