
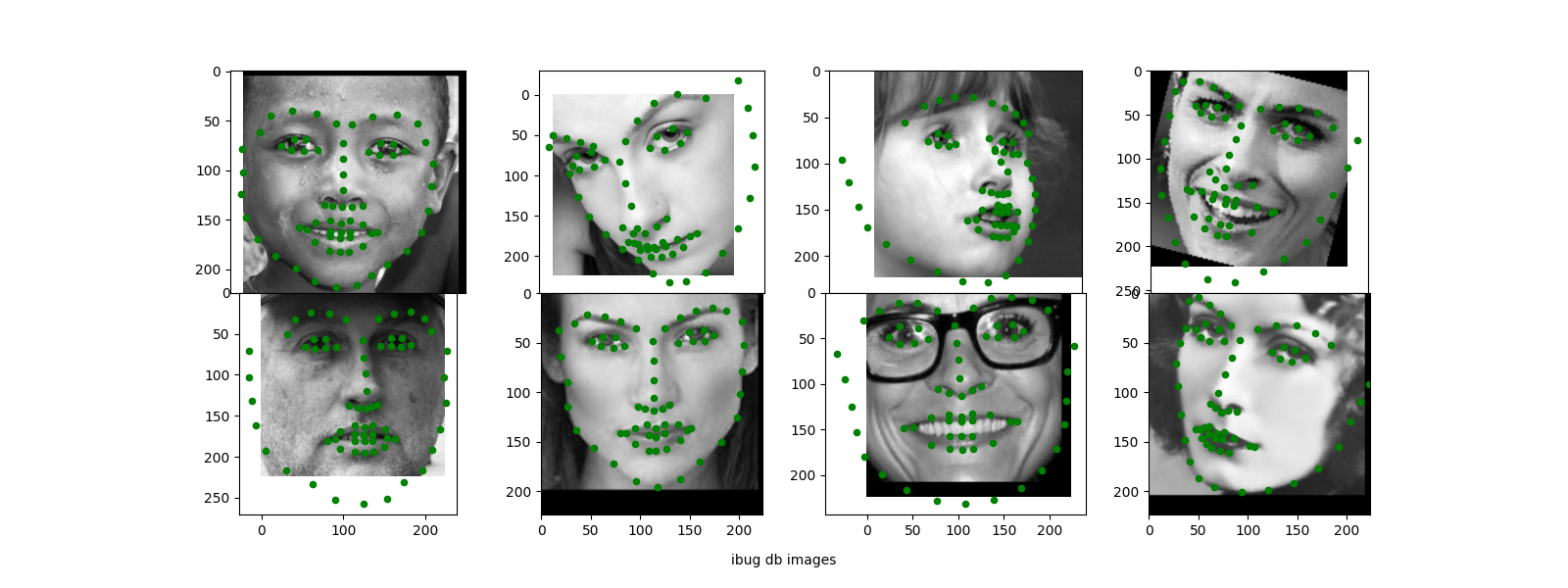
For the first part, we use the IMM Face Database to detect nose keypoints. Images are shifted to [-.5, .5] range and resized to 80x60. The last 8 x 6 = 48 images are held out the test set.
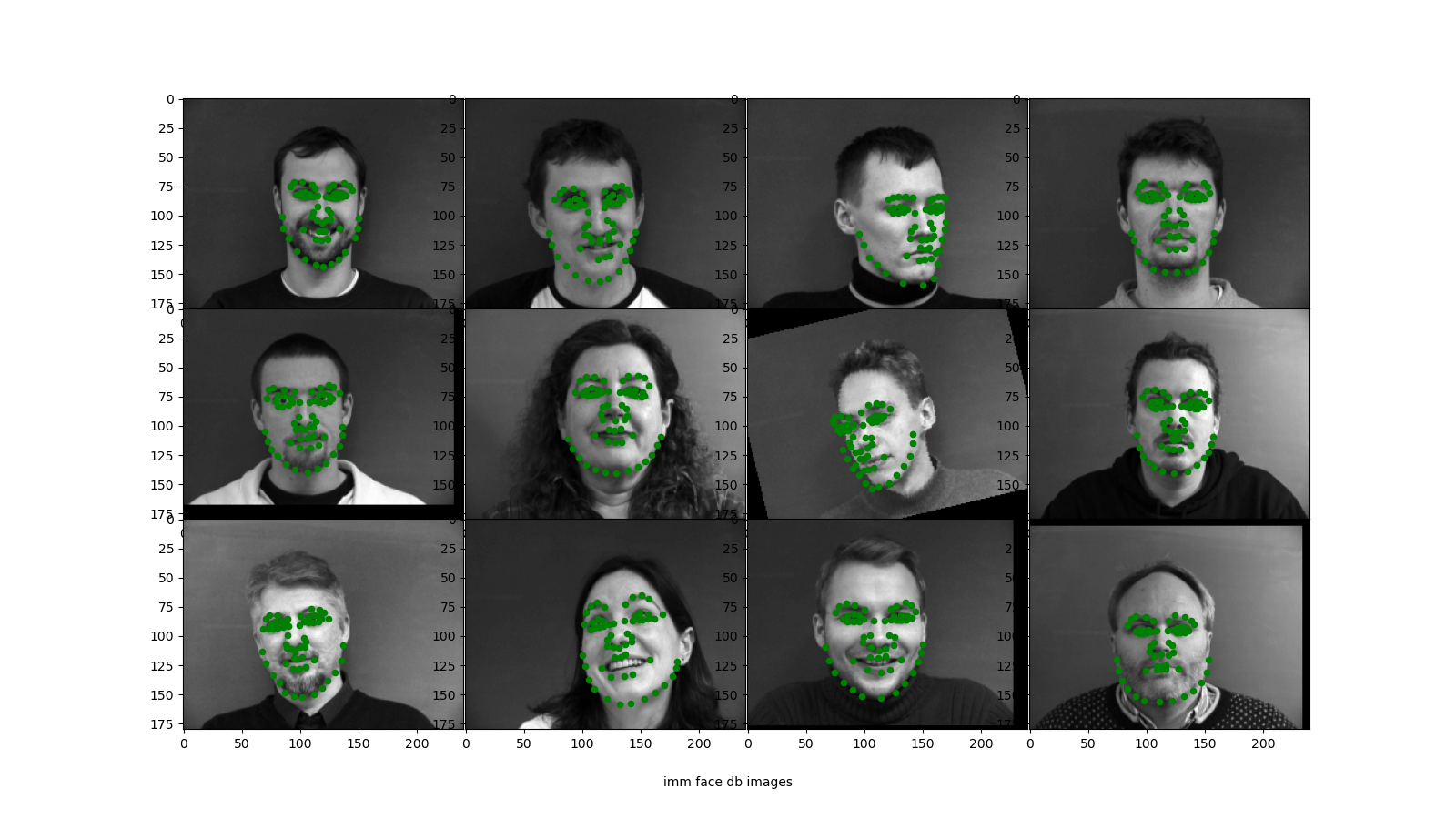
Below is a sample of faces with ground truth nose keypoints from the database.
We then train our convolutional neural networks. For hyperparameters, I tried varying both the learning rate [1e-3, 1e-4, 1e-6] and number of layers [3, 4].
Here is a comparison of the losses for training and testing.
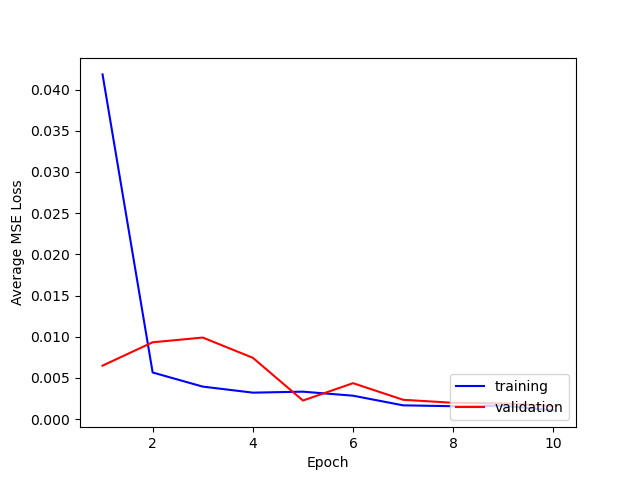
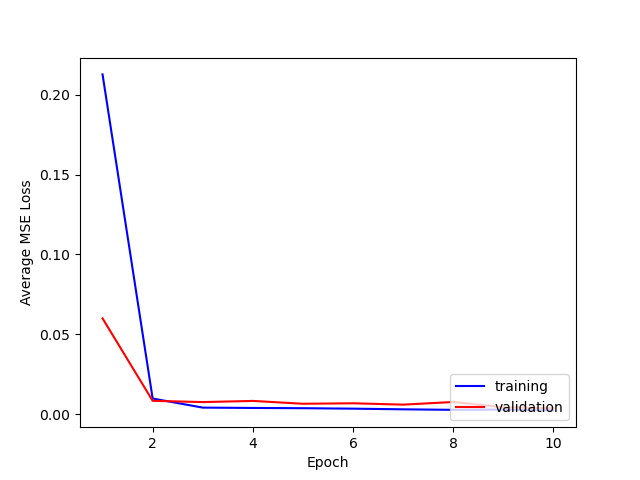
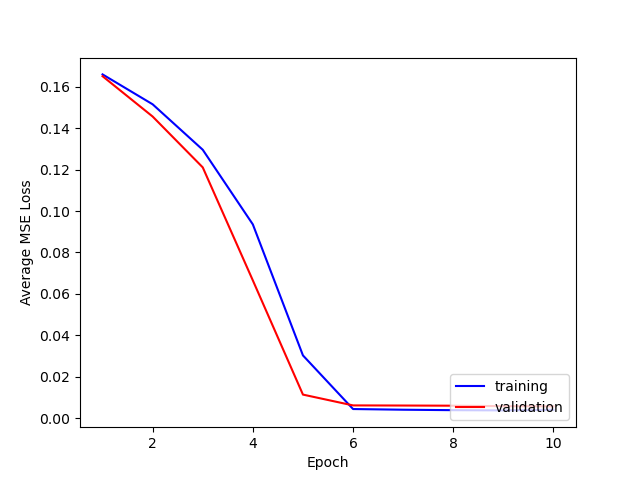
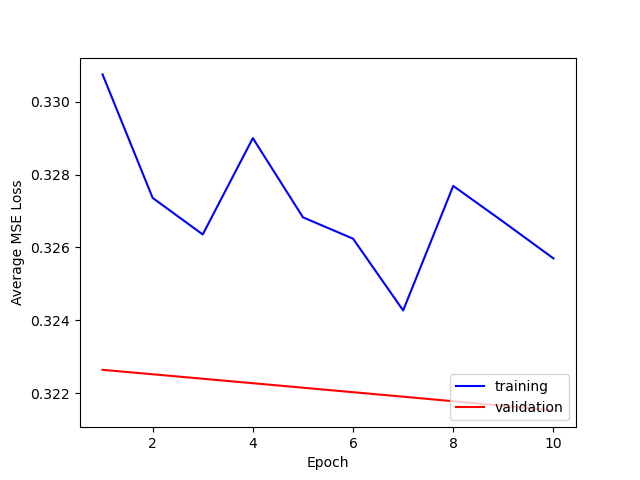
It seems that 1e-4 is the learning rate that works best, ensuring convergence and smooth decrease in both training and test loss.
Running the trained networks on the test data, I visualized the two worst ("incorrect") predictions and the two best ("correct") predictions to see how the network does. Ground truth points in green, predicted in red.
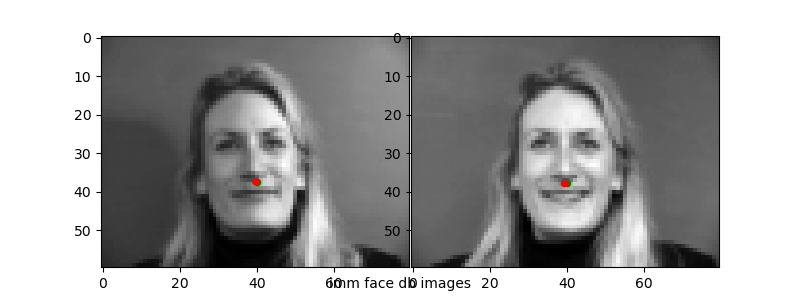
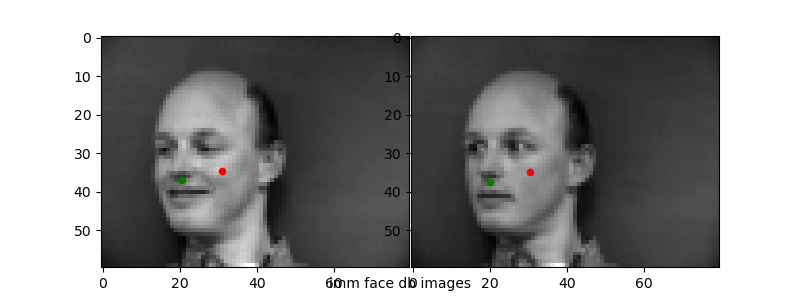
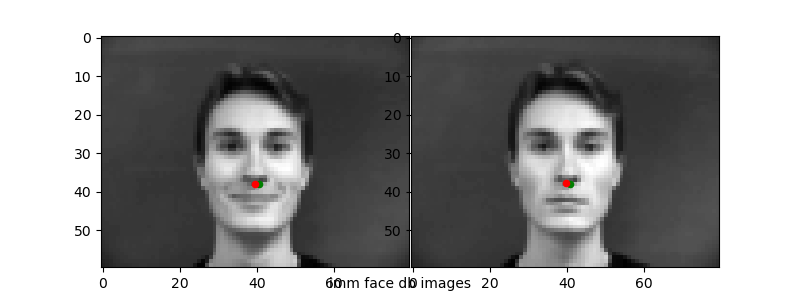


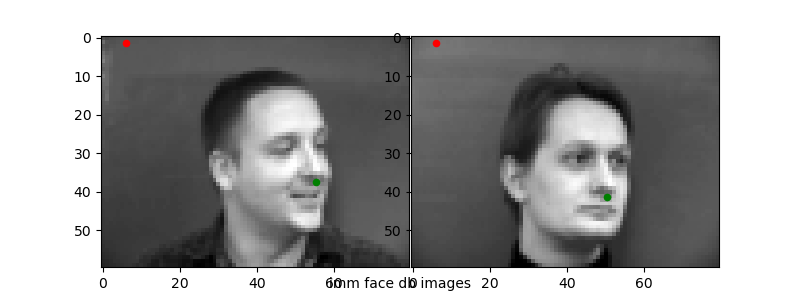


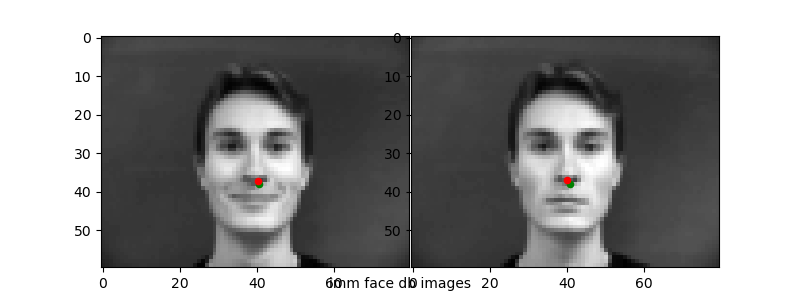

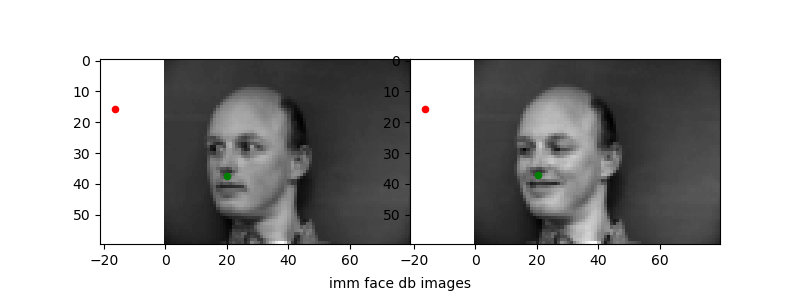
The 1e-6 learning rate simply does not work well as we have seen from the loss plots. For the other "bad" predictions, it seems like the network learns that the nose will usually be in some "center" range of the photo—from about [35, 45] for x and [30, 40] for y. When the nose position is deviated strongly from this (i.e.) the face is translated or turned at an angle, the network is unable to correspondingly change its prediction.
For this part, we want to predict the full set of 58 keypoints. This requires increasing the image size from 80 x 60 to 240 x 180. The dataset is also augmented through the following transforms: ColorJitter, RandomRotation (between -15 and 15 degrees), and translations (RandomAffine with translate between 5 and 10% of the images width).
Here are some sampled data (including augented sample).
For hyperparameters, I tried varying both the learning rate [1e-3, 1e-4] and number of layers [5, 6].
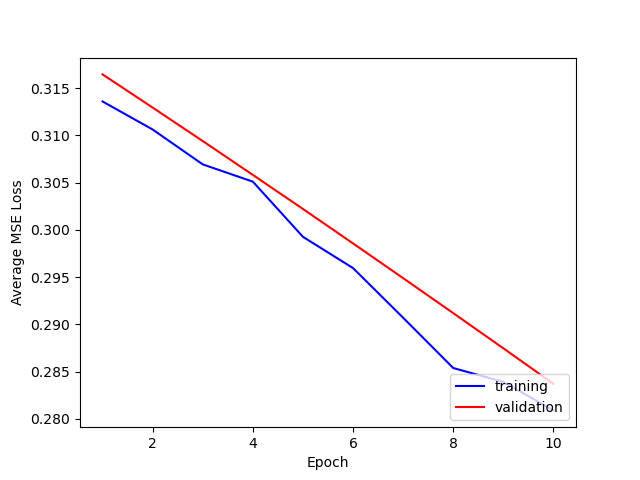
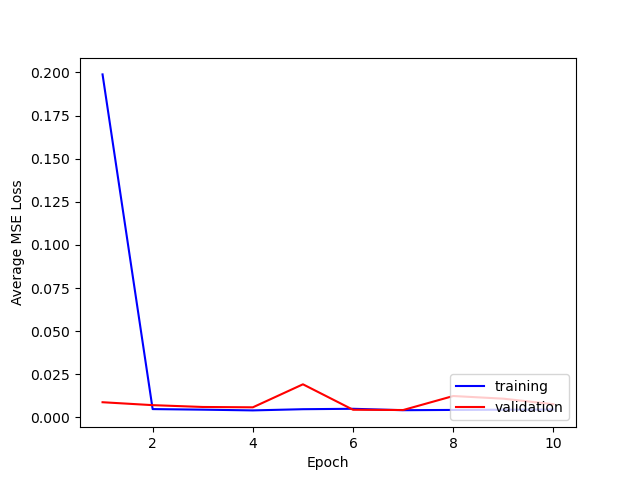
Here is a comparison of the losses for training and testing.
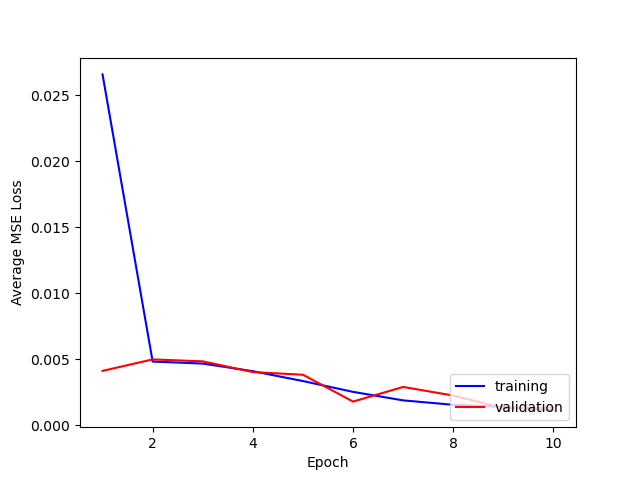
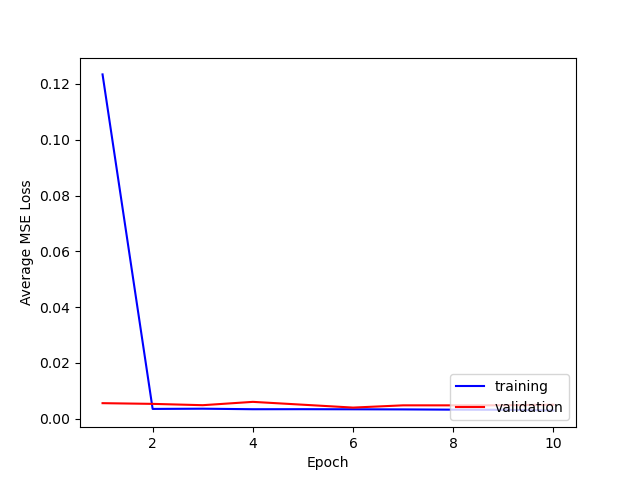
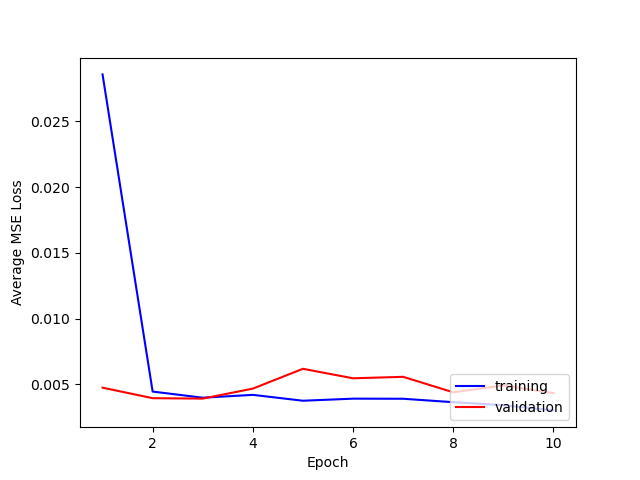
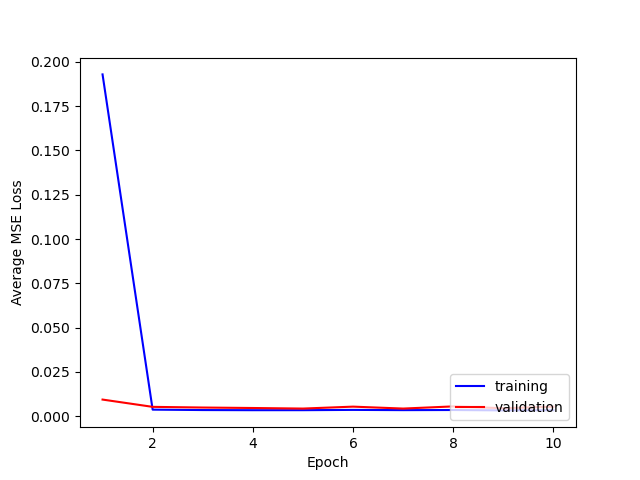
It seems that using 5 layers and 1e-4 is best. I think that adding more layers doesn't necessarily seem to help because the max pooling after each layer reduces the [h, w] of the output too much even if the # of channels increases, so the output size a the fully connected layer is not large enough.
Here are the "correct" and "incorrect" predictions for the test set.

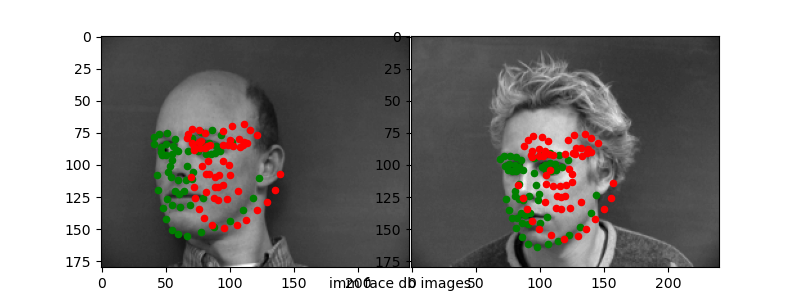
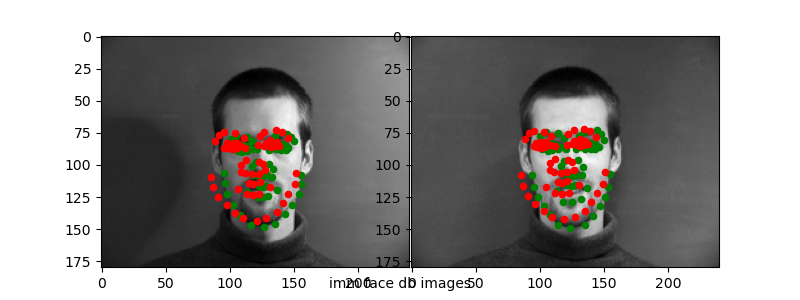
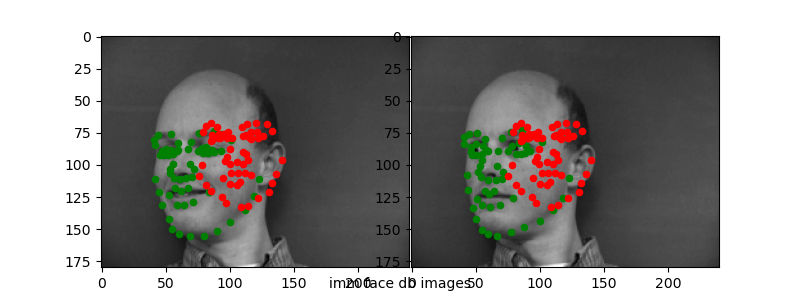
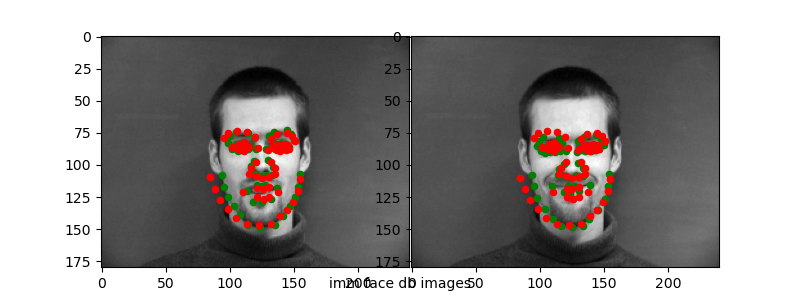
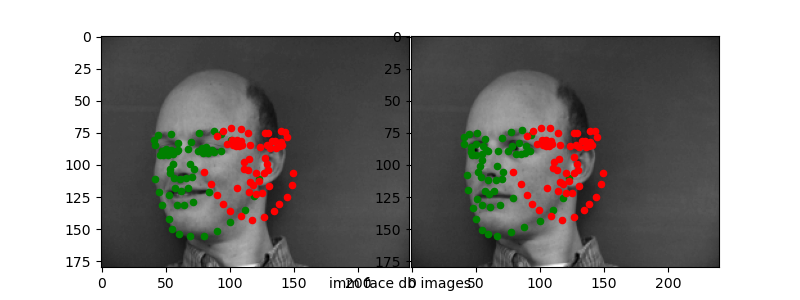
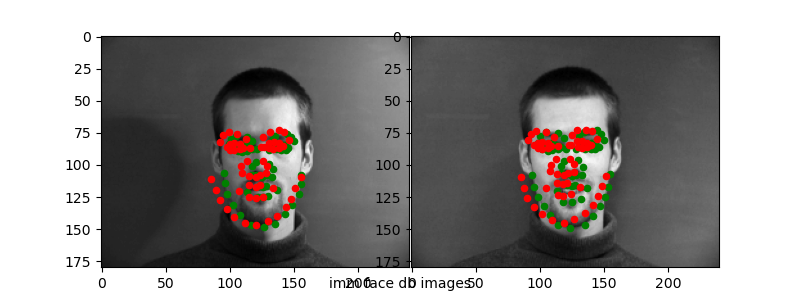
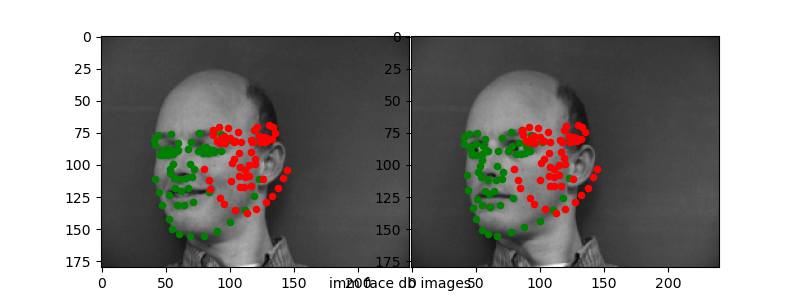
Again, it seems like the CNN is able to capture "slight" variances in the keypoint detection
but not major changes of the angle of the head. I computed my loss between the keypoints as
ratios between [0, 1], but seeing this issue makes me think may be I should have scaled those
values by the height and width before computing loss so as to penalize larger distances between
predicted keypoints and ground truth more.
I visualized some of the learned filters at each layer of the "best" (1e-4, 5 layer) network.

It seems what is learned in the filters especially the 3x3 ones is not super comprehensible (do not have obvious meanings) which makes me think that I should have used bigger filter sizes for the network architectures.
In this part, we train a network on the ibug face in the wild dataset. Images are cropped to the face bounding boxes and then resized to [224, 224].
For the network I used the architecture of resnet18 with 2 small changes, which is that the input channel to the first layer is grayscale (1) instead of RGB (2) and the output of the fully connecetd layer is 136 (for the keypoints).
The batch_size is 256 and LR is 1e-3.
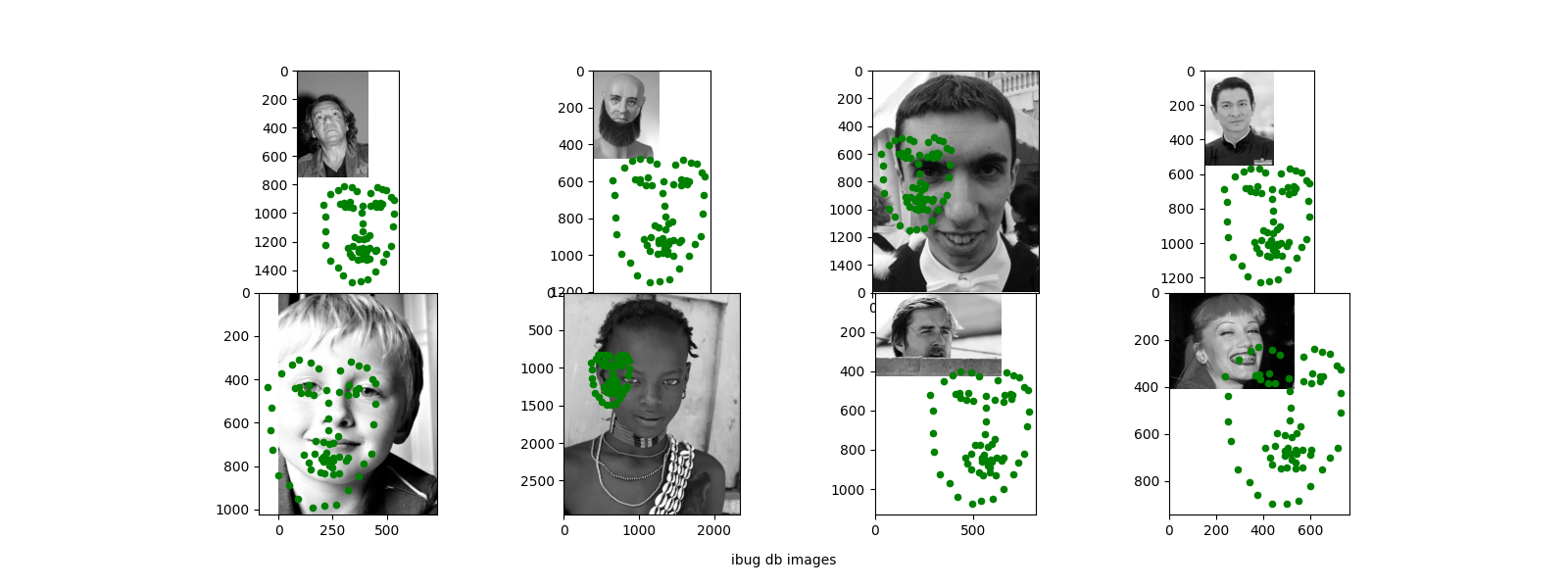
It seems there is a similar issue where the CNN learns to predict the same "face" and can only adapt to slight changes in position or scale.
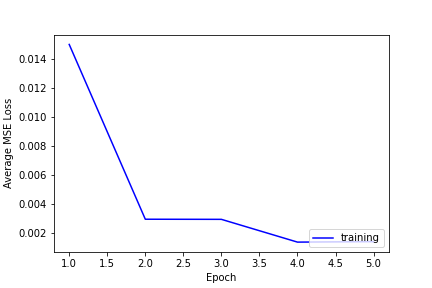
No validation loss in this case as the test set has no labels and I did not hold out any "fold" of the training data.
Results on data from my collection.
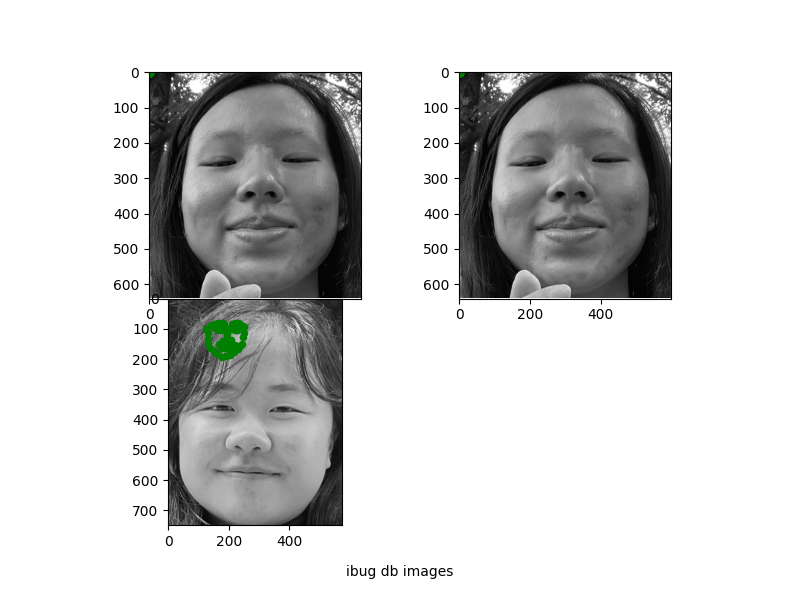
Clearly the network is not predicting correctly. I think there is some bug maybe with the coordinates or how loss is being computed?