


In this project, we designed and trained neural networks to detect facial keypoints in images of human subjects. Our networks increased in complexity and capability, from a simple shallow network to detect nose tips, to a larger network to detect all keypoints in small images, to a large network capable of detecting keypoints in varied real-world images.
Below are images from my DataLoader, annotated with the ground-truth nose tip keypoints used for training.
SmallNet( (conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1)) (conv3): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=560, out_features=100, bias=True) (fc2): Linear(in_features=100, out_features=2, bias=True) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) )
Learning rate: 1e-4
Batch size: 8
Loss: MSE
Epochs: 25
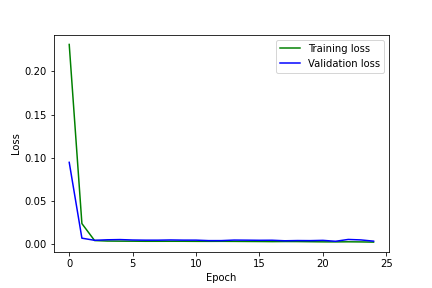 Mean squared error during training.
Mean squared error during training.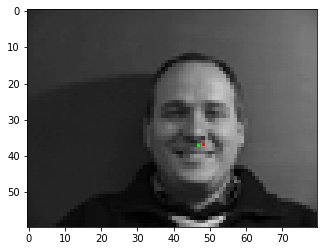 A very good prediction.
A very good prediction.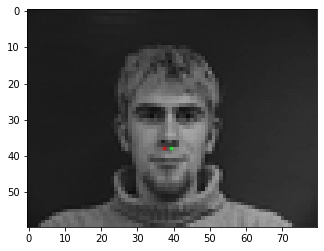 A quite good prediction.
A quite good prediction. Good, not great. I think this is just the convolution picking up on the wrong part of the below-nose shadow.
Good, not great. I think this is just the convolution picking up on the wrong part of the below-nose shadow.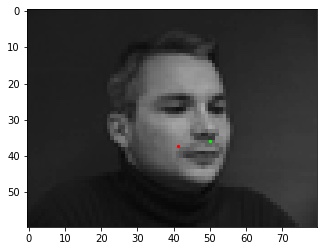 Terrible. The network doesn't do well with faces turned to the side, since there aren't many in the training set.
Terrible. The network doesn't do well with faces turned to the side, since there aren't many in the training set.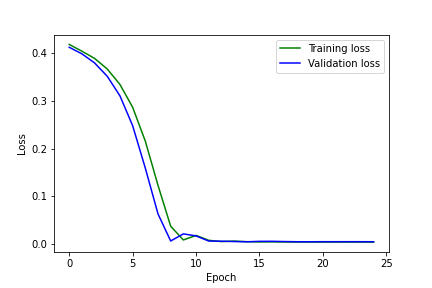 Varying parameters: increasing the batch size to 32 (from 8) leads to a clear case of overfitting.
Varying parameters: increasing the batch size to 32 (from 8) leads to a clear case of overfitting.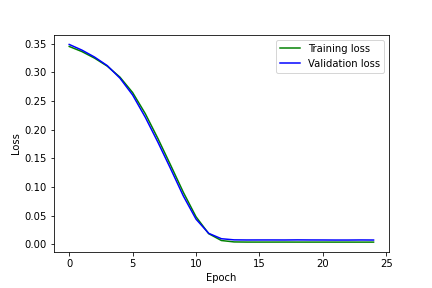 Varying parameters: decreasing the learning rate to 1e-5 (from 1e-4) doesn't affect the final network's practical performance very much, but the MSE curve is somewhat smoother and looks more like you normally "want" a model's loss curve during training to look.
Varying parameters: decreasing the learning rate to 1e-5 (from 1e-4) doesn't affect the final network's practical performance very much, but the MSE curve is somewhat smoother and looks more like you normally "want" a model's loss curve during training to look.Below are more images from my DataLoader, annotated with the ground-truth facial keypoints used for training.

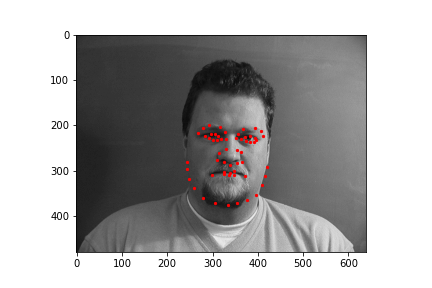
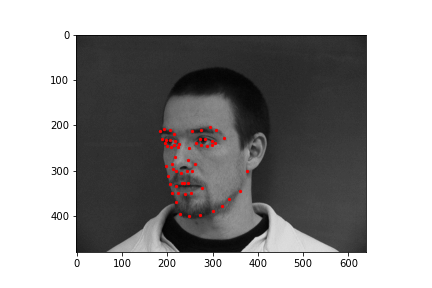
BigNet( (conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(16, 28, kernel_size=(3, 3), stride=(1, 1)) (conv3): Conv2d(28, 32, kernel_size=(3, 3), stride=(1, 1)) (conv4): Conv2d(32, 24, kernel_size=(3, 3), stride=(1, 1)) (conv5): Conv2d(24, 12, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=2448, out_features=580, bias=True) (fc2): Linear(in_features=580, out_features=116, bias=True) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) )
Data transformation: I randomly rotated between -10 and 10 degrees and translated by 10% of the total image size in every direction but down (because that often caused points to be cut off). I resized using PIL for smoother antialiasing.
Learning rate: 1e-3
Batch size: 4
Loss: MSE
Epochs: 12
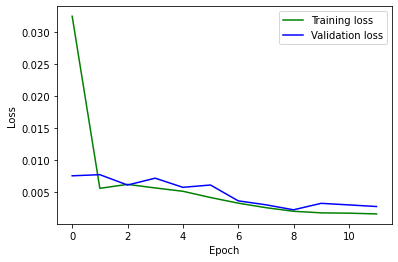 Mean squared error during training.
Mean squared error during training. A quite good prediction.
A quite good prediction. A fairly good prediction.
A fairly good prediction.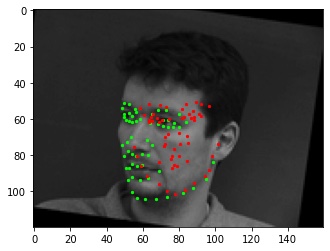 Bad. The network has a lot of trouble with faces turned to the side, even more than the nose detector does. The dataset contains few of them and it has trouble generalizing between forward-facing and side-facing faces.
Bad. The network has a lot of trouble with faces turned to the side, even more than the nose detector does. The dataset contains few of them and it has trouble generalizing between forward-facing and side-facing faces.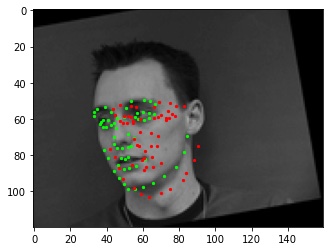 Similarly bad. I think this is a combination of the face being turned and the image rotated that's throwing it off.
Similarly bad. I think this is a combination of the face being turned and the image rotated that's throwing it off.
For this part, I worked in a Google Colab instance. I used PyTorch's ResNet18 model (not pretrained), modified so that the first convolutional layer takes only one input channel and the last linear layer outputs 68 * 2 = 136 x, y coordinates.
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
Data transformation: As above, I randomly rotated between -10 and 10 degrees and translated by 10% of the total image size in every direction but down. I resized using PIL for smoother antialiasing.
Learning rate: 1e-3
Batch size: 32
Loss: MSE
Epochs: 14
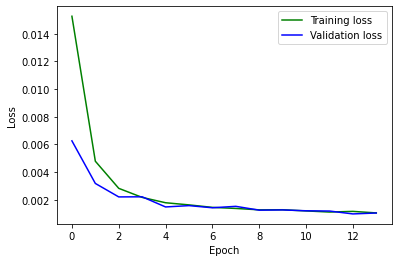 Mean squared error during training.
Mean squared error during training.As above, green is ground-truth, red is my predicted points.

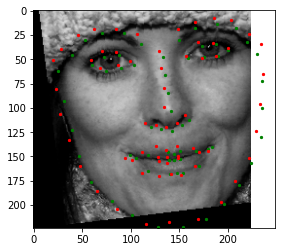
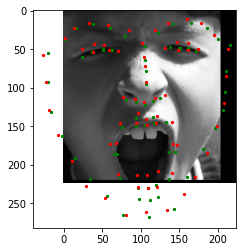
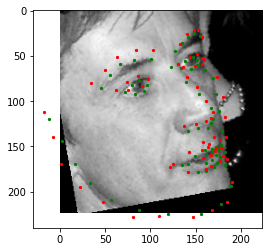


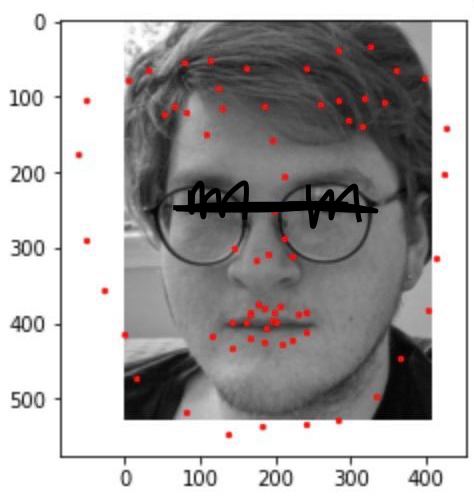 This image of my friend didn't work too well. It got the mouth pretty well and nose fine, but glasses threw it off. (Black marking is to protect identity.)
This image of my friend didn't work too well. It got the mouth pretty well and nose fine, but glasses threw it off. (Black marking is to protect identity.) This image of Mustafa Kemal Ataturk worked well, although it missed the left edge of his face, probably because of an unusual angle. (Fun fact - Ataturk had a lazy eye and preferred only to be pictured in profile for that reason!)
This image of Mustafa Kemal Ataturk worked well, although it missed the left edge of his face, probably because of an unusual angle. (Fun fact - Ataturk had a lazy eye and preferred only to be pictured in profile for that reason!) Also alright with facial keypoints, but bad with boundaries. I'm not entirely sure why. Perhaps low contrast.
Also alright with facial keypoints, but bad with boundaries. I'm not entirely sure why. Perhaps low contrast.