194-26 Project 5 - Carolyn Duan
Part 1: Nose Tip Detection
The goal is to train a convolutional neural network to predict the nose key point coordinates of faces from the IMM database. To start, here are a couple ground-truth key points from my data loader (as per the spec, I used PIL to downsample the images to 80x60 pixels):

Here's the model I used, with a batch size of 64 and a learning rate of 1e-3:
CNN(
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(12, 20, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(20, 28, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(28, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=64, out_features=30, bias=True)
(fc2): Linear(in_features=30, out_features=2, bias=True)
)Train and Validation Loss
Here's the training and validation loss for this model:
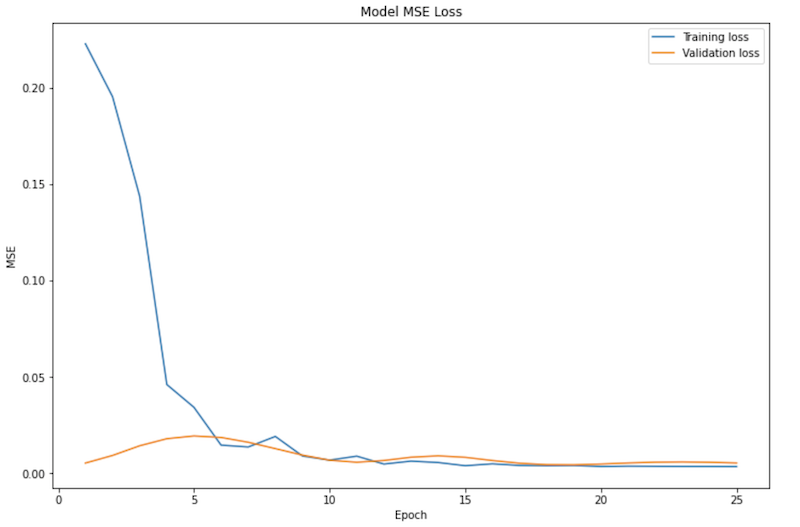
Here are my predictions for this model; they're not all that good:

Success/Failure cases
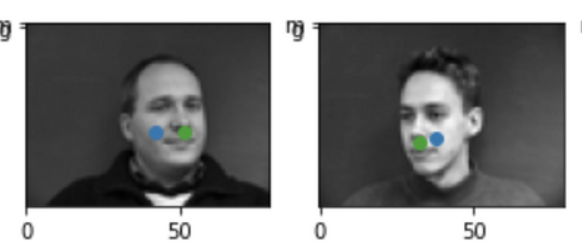
These are 2 images where the prediction worked well. My model works well with straight-on mug shots.

These are 2 images where the prediction was poor. My model doesn't work very well with faces that are turned to the side, presumably due to overfitting on a small dataset. The model trends towards choosing a cheek point, and I think it's because it tries to pick a point that's horizontally centered (due to all of the forward-facing pictures) and still has some contrast (which would be the smile lines on the cheek).
Hyperparameter tuning
Tuning number of convolution layers
I tested reducing the number of convolution layers from 4 to 3. This was my updated model:
CNN(
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(12, 20, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(20, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=64, out_features=30, bias=True)
(fc2): Linear(in_features=30, out_features=2, bias=True)
)And this was the updated training/validation loss graph:
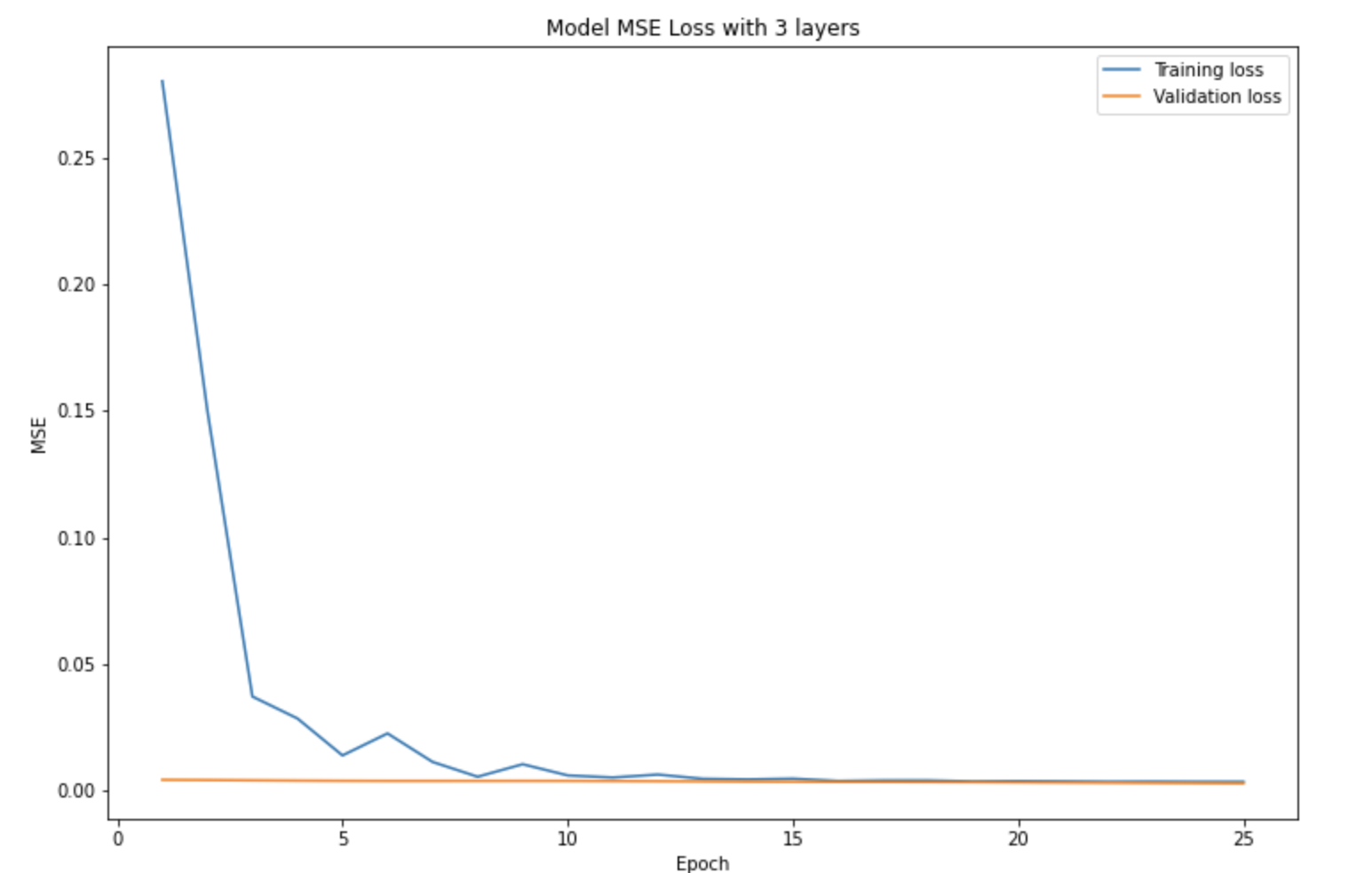
It didn't seem to really have an effect on either the quality of predictions or the MSE loss, which I thought was pretty surprising.
Tuning learning rate
I tested increasing the learning rate from 1e-3 to 1e-2. Here's the resulting training/validation loss graph:
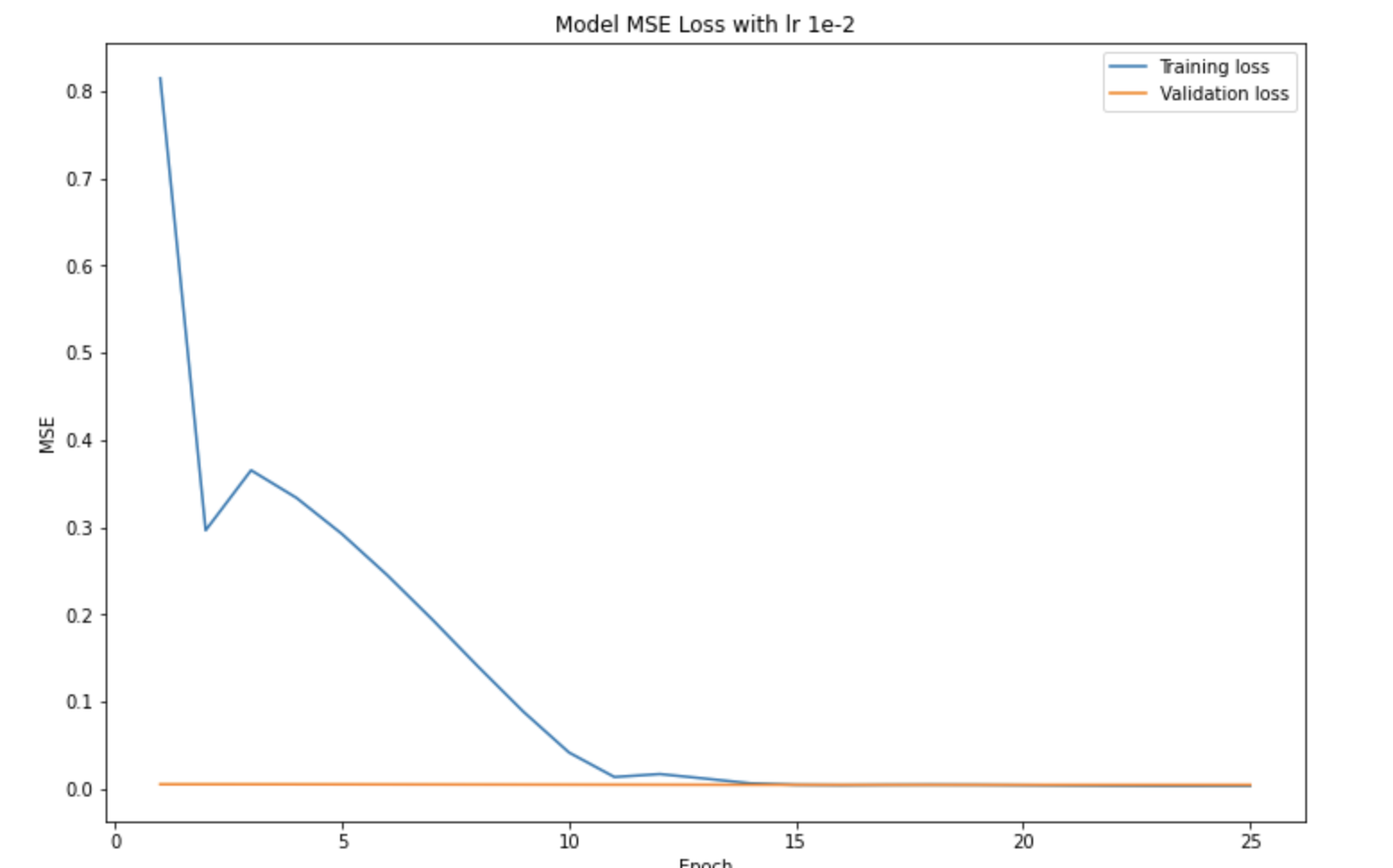
With a bigger learning rate, you'd expect the MSE to oscillate since you take bigger steps in both directions. That's kind of reflected here, but not really to the scale that I was expecting (probably because I only graphed MSE per epoch and not within each epoch). In the end, it still converged fine, and didn't really seem to affect the model's predictions.
Part 2: Full Face Key points Detection
For part 2, we want to predict all 58 key points of a face, not just the nose tip. Because the data set is small, we use data augmentation to prevent model overfitting. I added 3 augmentations for every picture: a saturation jitter, a random rotation of +- 15 degrees, and a random x/y shift of (+-24, +-18) pixels. Each picture is also rescaled to 240 x 180 pixels. Here's a couple sampled images from my data loader with their labeled ground-truth key points.

Model Architecture
FullFaceCNN(
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(12, 20, kernel_size=(7, 7), stride=(1, 1))
(conv3): Conv2d(20, 30, kernel_size=(7, 7), stride=(1, 1))
(conv4): Conv2d(30, 40, kernel_size=(7, 7), stride=(1, 1))
(conv5): Conv2d(40, 50, kernel_size=(7, 7), stride=(1, 1))
(fc1): Linear(in_features=13650, out_features=1000, bias=True)
(fc2): Linear(in_features=1000, out_features=116, bias=True)
)
Learning rate: 1e-3
Architecture:
conv1, relu
conv2, relu
maxpool (stride 2)
conv3, relu
maxpool (stride 2)
conv4, relu
conv5, relu
maxpool (stride 2)
flatten
fc1
fc2Train and Validation Loss
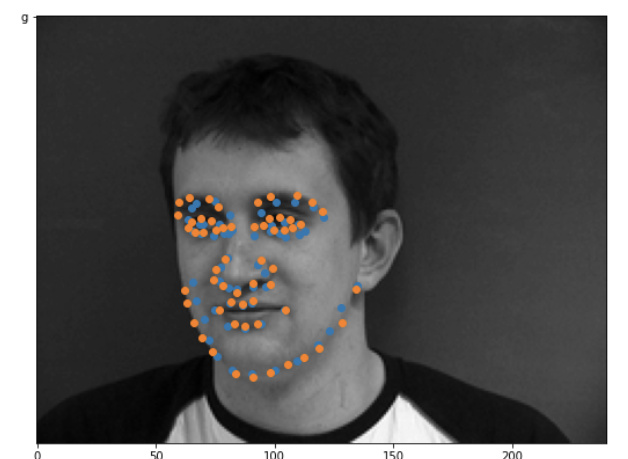
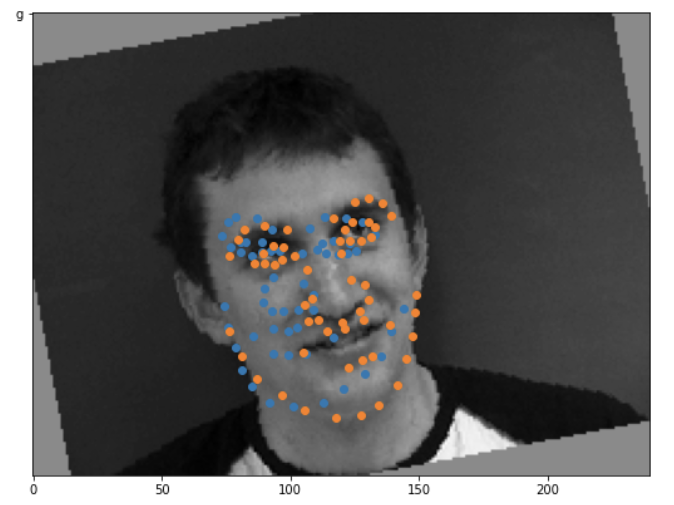
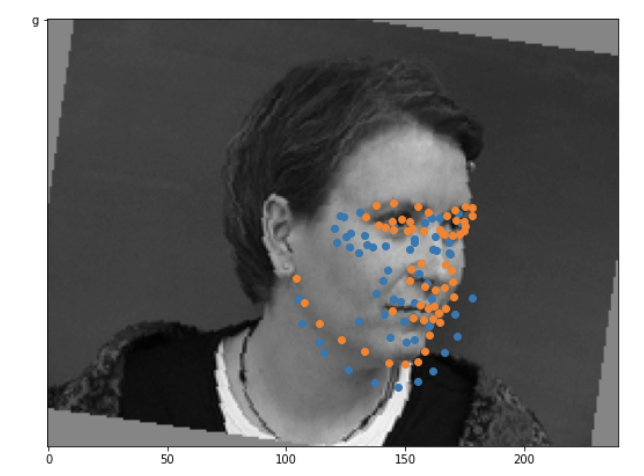
Success/Failure Cases
Orange is the truth, and blue is my prediction. The left two images are pretty (I'm surprised tbh) good predictions. The right two images aren't that good. I think it's because both of those pictures are rotated pretty strongly, and the rightmost image is a pretty extreme profile view of the face. The model only performs well on straight-on or only slightly tilted faces, probably due to overfitting on those particular faces even with the data augmentation.

Filter Visualizations

Here are the filter visualizations for the first convolution layer (there are 12 filters for my first layer).
Part 3
In part 3, I used a standard CNN model (ResNet18) to train on a larger face dataset.
Model Architecture
Not really sure what I'm supposed to put here, since I just used the ResNet18 model and only changed the input channels of the first layer to 1, and the output of the last layer to 136. I used a 90-10 split for train and validation, and my train batch size was 66. My learning rate was still 1e-3. I'll copy the details of the ResNet18 model just for the sake of being comprehensive.
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
) (layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
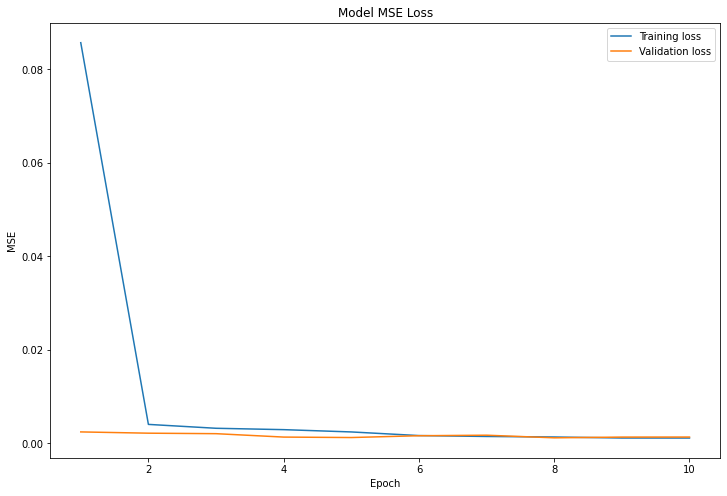
)Training and Validation Loss
I trained the model for 10 epochs. Below is the graph of both the training loss and validation loss per epoch.
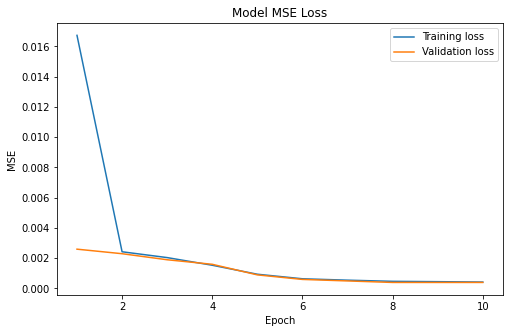
Prediction Results
Here are the results of my model on my test set. Green is the ground-truth key points, and red is the model's predictions. Pretttyy goood.

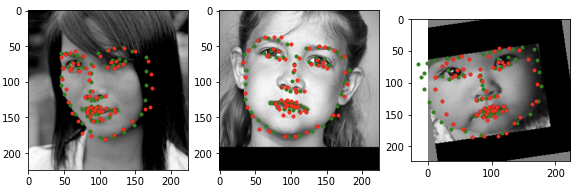
Predictions on my own photos
Here are the model's predictions on my own photos, all of me. It does a pretty good job on all 3 of them. What's interesting is it seems to consistently mis-predict the right edge of my face, which it also does on the test set above. I have some very slight dimples and I think the contrast of the dimple is what makes the model think that that's where my face edge is. On the photo with glasses, it also does a pretty poor job of predicting where the eyes are — probably again because of the contrast of the dark top rim of the glasses. On the left photo, it also completely misses my eyes and eyebrows, probably because my eyes are pretty closed in that picture.


