Overview
In this project, I trained convolutional neual networks to learn to find keypoints on a person's face. The first neural network was train to find just the tip of a person's nose. The second neural network was trained to find 58 keypoints on a person's face. Finally, the last neual network was trained to find keypoints on a larger dataset.
Nose Tip Detection
I first created a dataloader with the images and the point for the nose tip. I reshaped the images to 80x60 and made the image grayscale and normalized to between -0.5 and 0.5. Finally, after setting up the dataset, I created a CNN with three layers of a convolutional layer followed by a ReLU layer followed by a max pool layer. Afterwards there are there are two fully connected layers with a max pool in between them. I used mean-squared loss with a 0.0001 learning rate for 20 epochs.
I had three conv2d layers, all with 3x3 kernels. The first layer went from 1 channel to 32 channels. The second layer went from 32 channels to 12 channels. Finally, the last layer went from 12 channels to 32 channels. For fully connected layers, the first went from 1280 to 300 and the second went from 300 to 2. The 2 values are the coordinates for the nose.
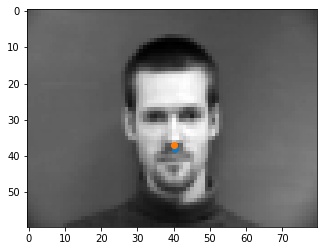
Below are some correct points shown from the dataloader.
|
|
|

|
|
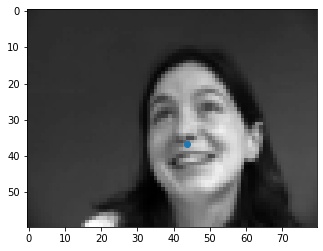
|
Shown below is the training/validation log loss curve. This is a log loss curve to enlarge it to see the trends. Because this is learning only one point, the error is more volatile since it tries to adjust for all different orientations; however, overall, the trend is curving downward for both curves.
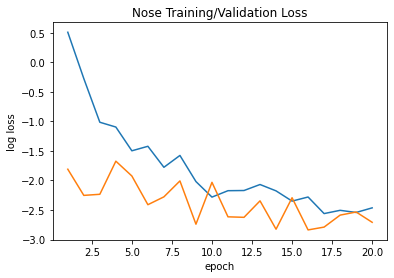
|
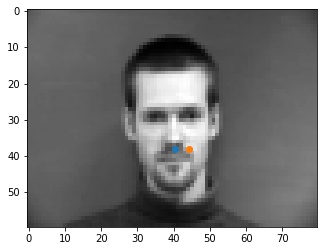
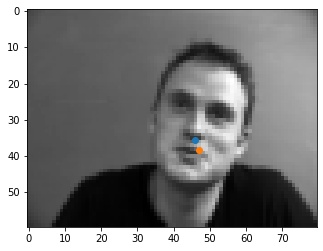
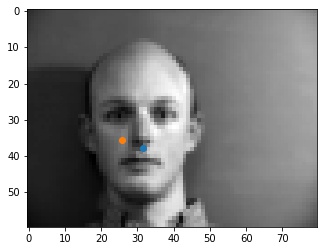
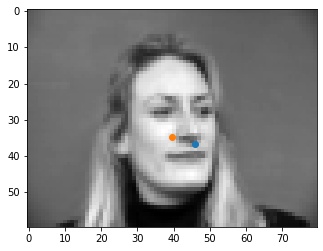
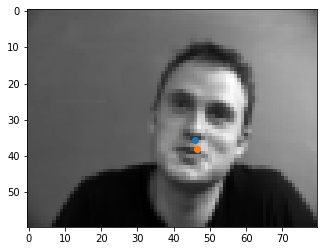
Shown below are some results from the model. The good points are spot on with the tip of the nose. I think that some of the errors may be originating from the fact that at the tip of the nose, the color goes sharply from light to dark, so the model may be looking for points similar to that, like on the mustache or the lips that are somewhere close to the tip of the nose, as seen in the incorrect outputs.
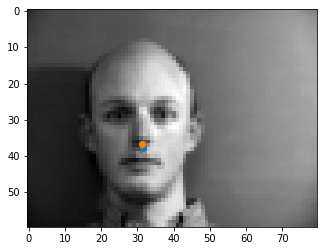
|
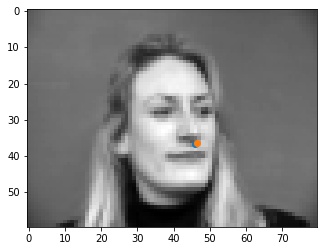
|
|
|
To see what happens when we change the hyperparameters, I tried training the model with a learning rate of 0.0001 instead of 0.001, and changed the filter kernels to be 5x5 instead of 3x3. Below we see the results for the same images as above. We can see that by lowering the learning rate, some of the points that were good before have not been fully learned yet. Additionally with a larger kernel filter size, we may have better learned the surroundings of the nose, including the mustache, from the first bad nose from the previous part.
|
|
|
|
Full Facial Keypoints Detection
For this part, the setup for the dataloader and the neural network are the same, except that we are trying to learn all of the facial features, instead of just the nose point. We set up the layers and the dataloader the same way, except now we have more layers in the dataloader. Additionally, everytime we get a picture, they are randomly shifted by a value between -10 and 10 and randomly rotated a random degree between -15 and 15.
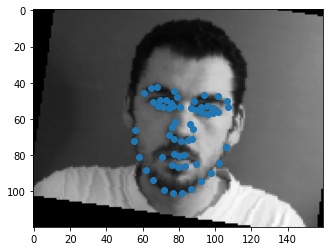
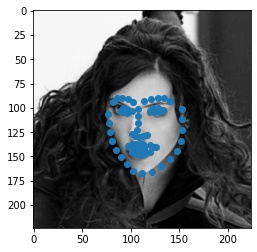
Shown below are some samples from the dataloader.

|

|

|

|
|

|
There are 5 layers overall, all with 3x3 kernels. The first layer goes from 1 channel to 32 channels, and the rest go from 32 channels to 32 channels. The two fully connected layers go from input of 4032 to output of 2000 and input of 2000 to output of 116, which is reshaped to be a 58x2 matrix to get all 58 points. I added a max pool after the first 3 conv2d layers and after the first fully connected layer. Additionally, I traied with a learning rate of 0.001 and a batch size of 1 for 35 epochs.
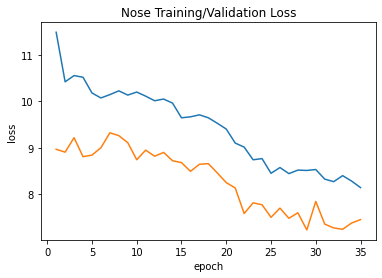
Shown below is the training/validation log loss curve. This is a log loss curve to enlarge it to see the trends.
|
Shown below are some outputs from the model. For the first failure case, I think it fails because the man's mouth is open. The output looks like the model treats that open mouth as a chin, so the orange guess has the chin at the bottom of the mouth. For the second error case, I think this face is thinner and longer than the average face, so the chin is wider, and the mouth is under the actual mouth because this face is probably a large deviation from the average face.
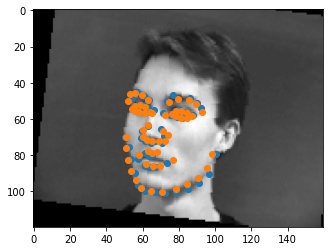
|

|

|
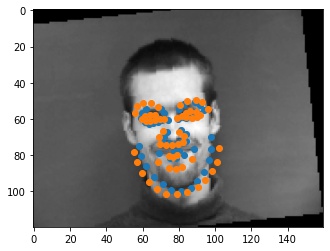
|
The filters for the first layer are shown below. We see for some of the filters, like filters 8, 9, 10, 11, and 12, they look like edge detectors. Additionally, some of the earlier ones look like they are detecting slanted lines.
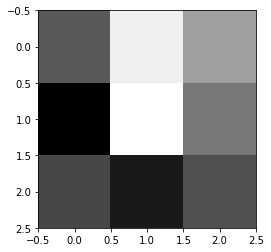
|
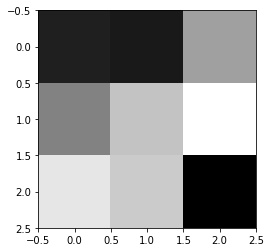
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Train with Larger Dataset
My mean absolute error is 12.69890. My name in the competition is Eric Zhu.
To load the data, I increased the bounding boxes slightly by 100 on each side to make sure that all of the keypoints could fit in the cropped image for more of the datapoints. If not all of the keypoints fit, I just threw out that datapoint. I ended up with 5862 training points. After checking the bounding boxes, I cropped it and changed the size to 224x224. I also augmented the data by shifting and rotating the images.
I used a predefined Resnet18 Model, except I changed out the first layer to have an input channel of 1, and the last layer to have an output channel of 136. I trained this model with a learning rate of 0.001 and a batch size of 1 for 5 epochs.
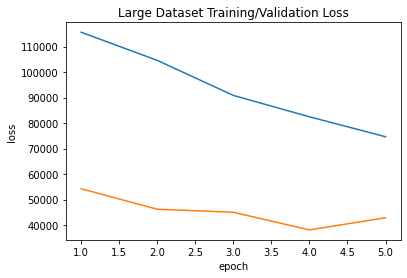
Here is the training/validation loss graph.
|
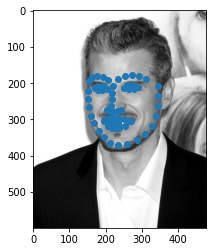
Below, we see some of the keypoints predictions made from my model.

|

|

|
|
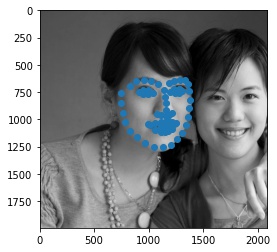
|
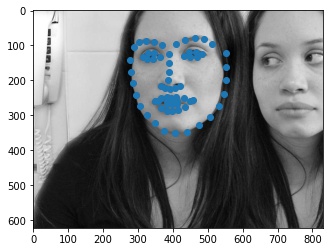
|
Here are three examples of other faces. One of them is my friend Jesse, and the other two are an actor, Robert Downey Jr., and and actress, Scarlett Johansson. For Jesse the model worked very well. The model misaligned Robert's nose and mouth, but the shape of the face is correct. For Scarlett, only parts of the side of her face are misaligned because of how sharp her jawline is. Overall, the model did very well on all three pictures.

|
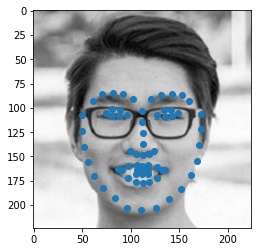
|

|
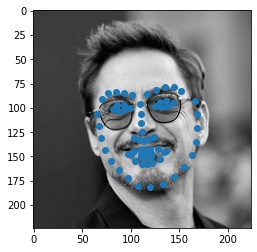
|

|
|