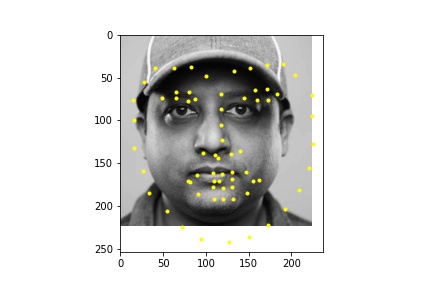
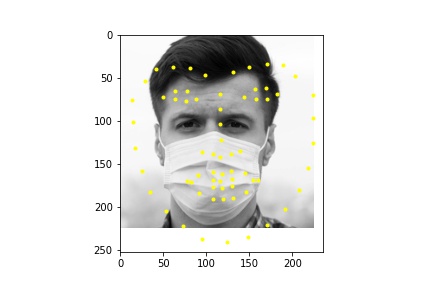
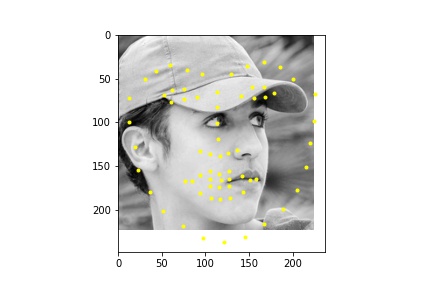
Part 1: Nose Tip Detection
First I generated a dataloader that takes in all the images and then outputs the nose coordinate as the associated label. Below are the sampled images from the data loader, visualized with ground-truth keypoints of the nose in red and other facial keypoints in blue.
Sampled image from dataloader visualized with ground-truth keypoints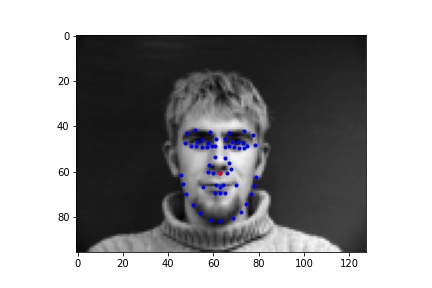
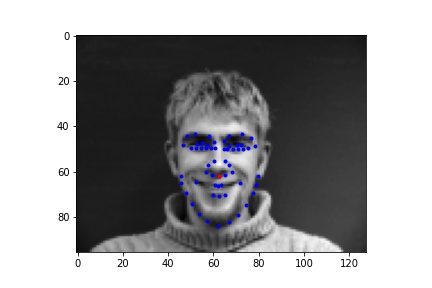
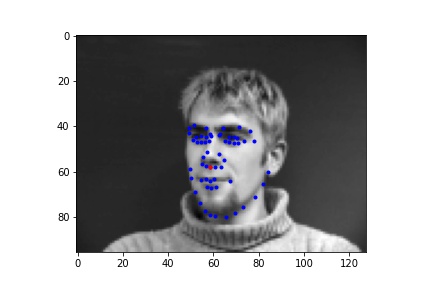
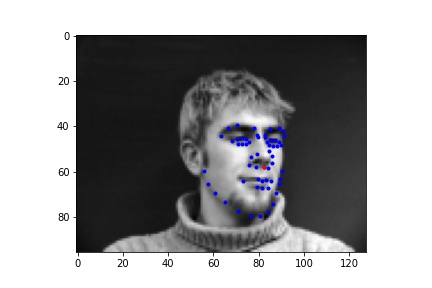
I created a net with 3 convolutional layers and 2 fully conencted layers, outputting 2 features in the end that are predictions of the coordinate of the nose keypoint, which could be compared against the ground-truth labels. I then trained it with a learning rate of 1e-3 for 15 epochs with a batch size of 16.
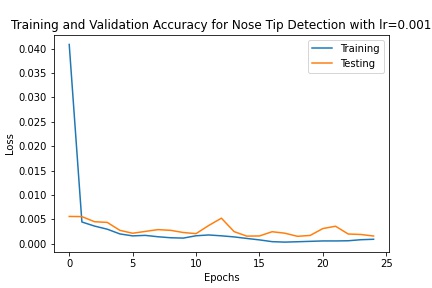
Predictions
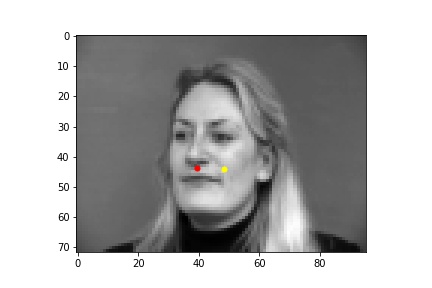
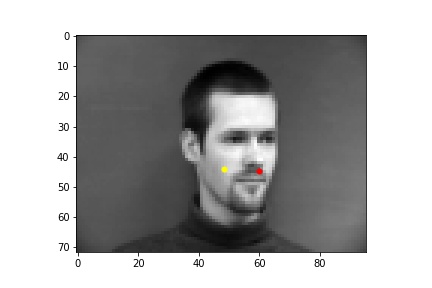
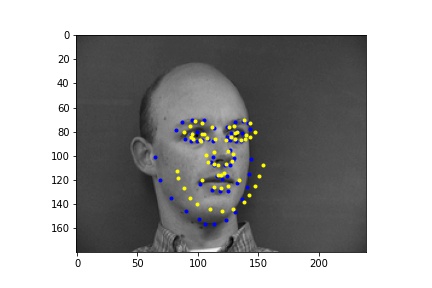
Below are images of some of the predictions from the model. The predictions are in yellow while the ground truth points are in red. We can see that the model performs best on poses where the subject is facing forward (first row), while it falls short when the subject's head is turned (second row). This may be because it is harder to determine the extent that the subject is turned away, and also the data tends to average near the center so the data is skewed closer to the center. The validation loss converged to around 0.0015, but there is still some overfitting as the training loss was smaller than 0.001, which is likely due to there not being enough data.
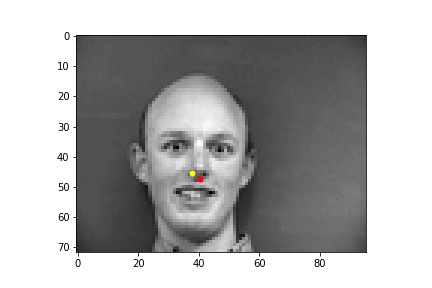
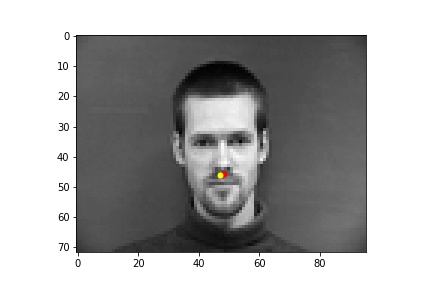
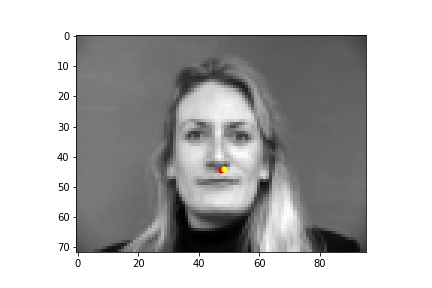
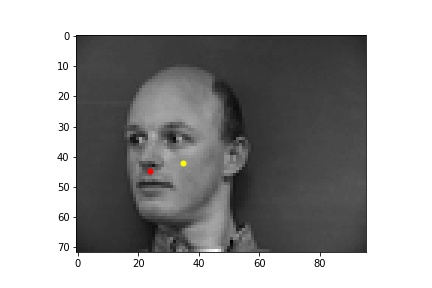
One parameter that I tried changing was the learning rate. Instead of 1e-3 as the learning rate, I set the learning rate to be 1e-4. This resulted in training loss that was initially higher than with 1e-3 and it ultimately converged to a higher value than with a learning rate of 1e-3, as the loss was around 0.0027.
Training results withlearning rate = 1e-4 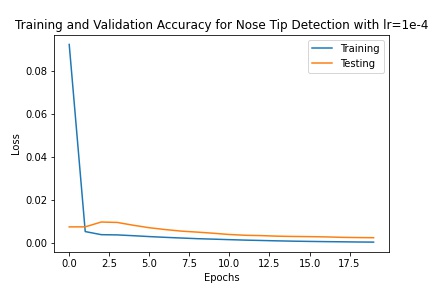
Another parameter I tried changing was the number of channels. I tried changing it so that 20 channels were added at each convolution. It began with less training loss, but yielded similar results in the end and ultimately converged to a similar validation loss.
Training results with more channels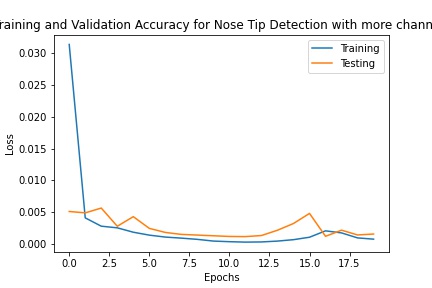
Part 2: Full Facial Keypoints Detection
I applied data augmentation randomly to the images in the dataset. I applied a combination of the following modifications:
- Rotations, at angle choices of
{-15, -5, 0, 5, 15}, chosen with a uniform probability - Color jitters for brightness and contrast
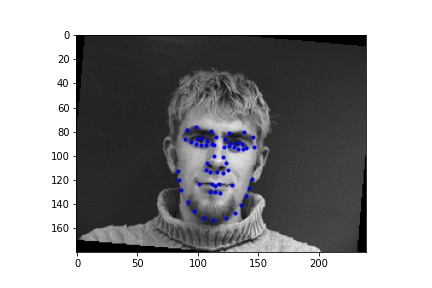
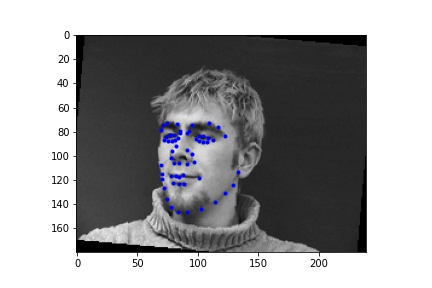
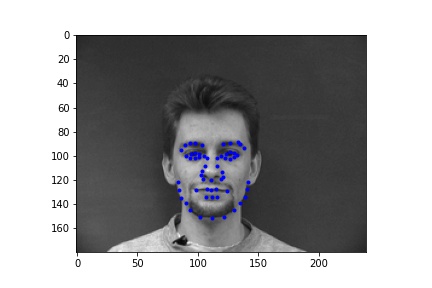
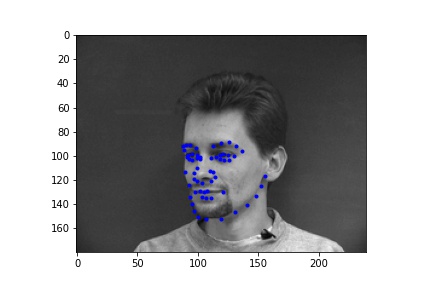

For training I used a learning rate of 1e-3 with 15 epochs.
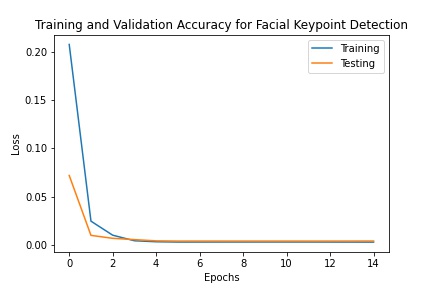
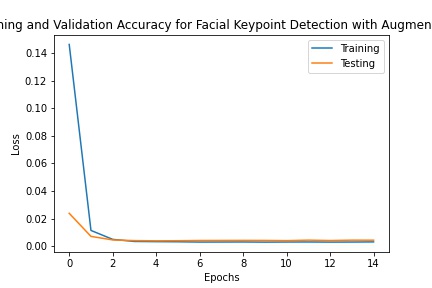
As seen in the figures above, while the two behave similarly at the beginning of training, augmentation helps get the training loss even lower than without augmentation since the model is less susceptible to overfitting.
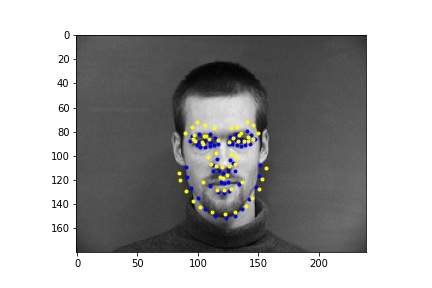
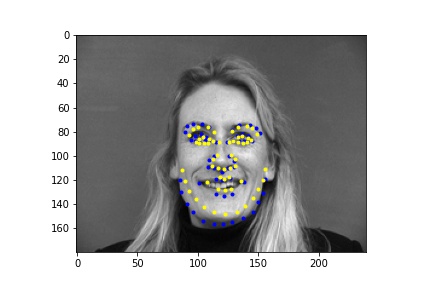
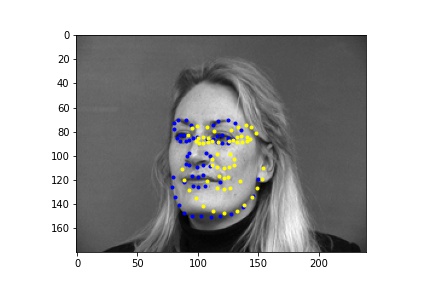
In the first 2 images the network detects the facial keypoints fairly well (predictions in yellow, ground truth in blue) In the second row of images the network falls short. Again like in part 1, the network struggles more with when the subject is turned. I think that the reasons for the facial keypoint predictions behaving like this is the same reason as the nose point, where a lot of the data averages out in the middle so the network tends to favor that.
Below are a few of the learned filters from the first convolutional layer.
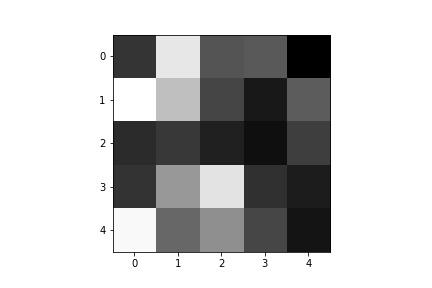
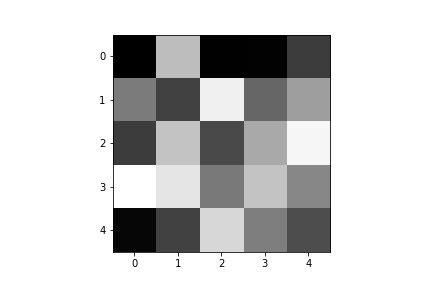

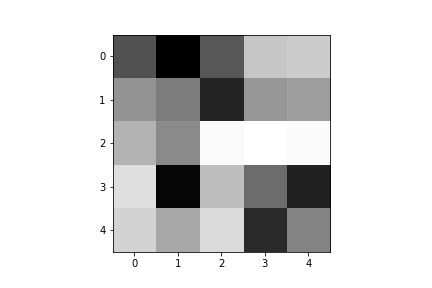
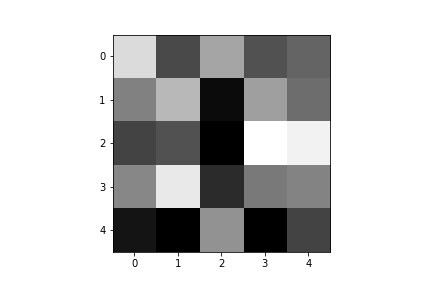
Part 3: Train with Larger Dataset
For the dataloader, I processed the images differently than in the previous parts by cropping the images according to their associated bounding boxes and rescaled them to be 224 x 224. I also made sure to update the annotated facial keypoints for the training data and applied augmentation like in part 2, only instead of rotation I did a translation between -10 and 10 for the x and y coordinates, simply because it gave me better outputs than rotation. Like in part 2, I also performed color jitter. Below are some of the rescaled and cropped images with their updated keypoints.

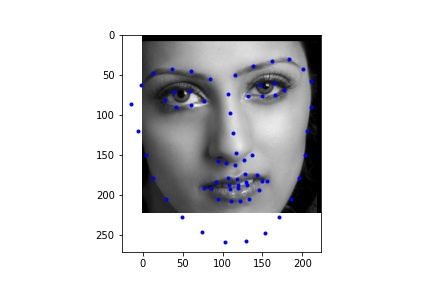
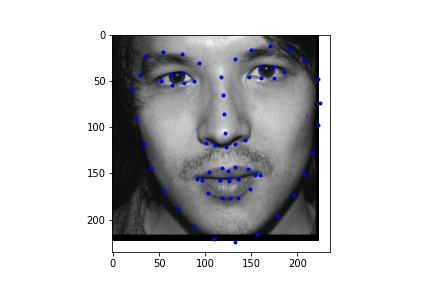
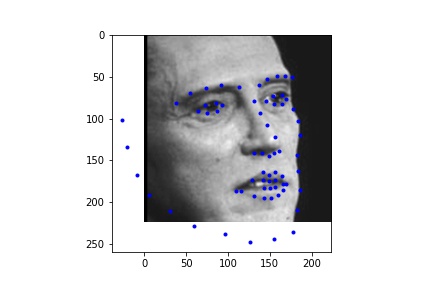
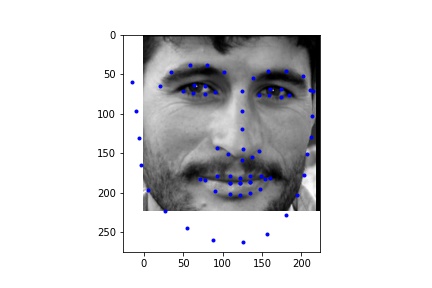
I used the ResNet18 model, adapting it such that it takes in a grayscale image (changed the input channel of the first convolutional layer to 1) and then outputted 68 keypoints (68 * 2 values).
Model:
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
Due to time constraints and GPU access constraints, I was not able to train on the full dataset and instead trained on a subset of the dataset of 2048 images, which is still significantly larger than the dataset that I ran part 1 and 2 on, which only had 240 images.
Below is the training and validation loss across 10 epochs. Because of the high learning rate, the first epoch had high loss, which is why the graph has such a dramatic drop in the training loss.
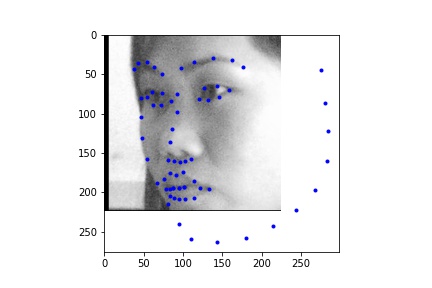
Learning rate = 0.06, Batch size = 16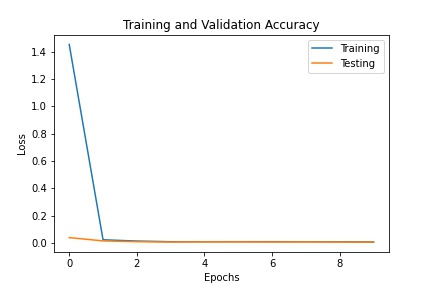
Outputs

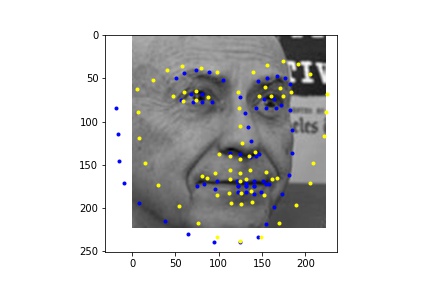
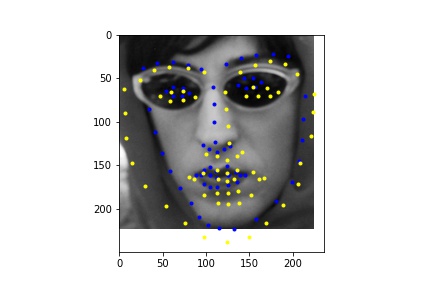
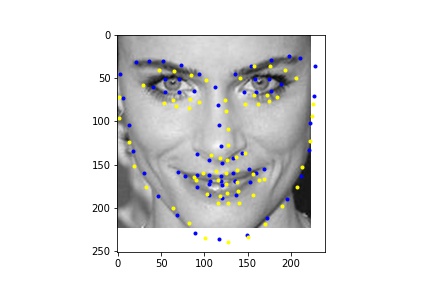
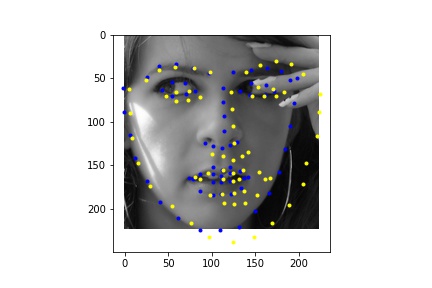
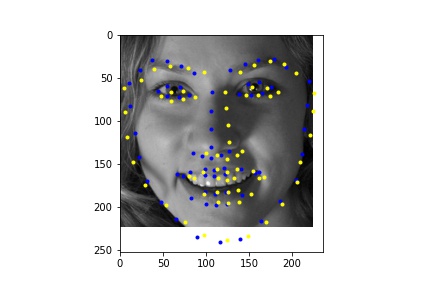
I ran the network on some additional photos from the internet. From these images we see that the network performs poorly on images that are cropped differently (less close) in the bounding box.