Project 5: Facial Keypoint Detection with Neural Networks
COMPSCI 194-26: Computational Photography & Computer Vision (Fall 2021)
Alina Dan
Overview
In this project, I looked into how to utilize neural networks to automatically detect facial keypoints. In particular, this focuses on how deep convolutional neural networks (CNNs) work with this detection.
Part 1: Nose Tip Detection
Data Processing
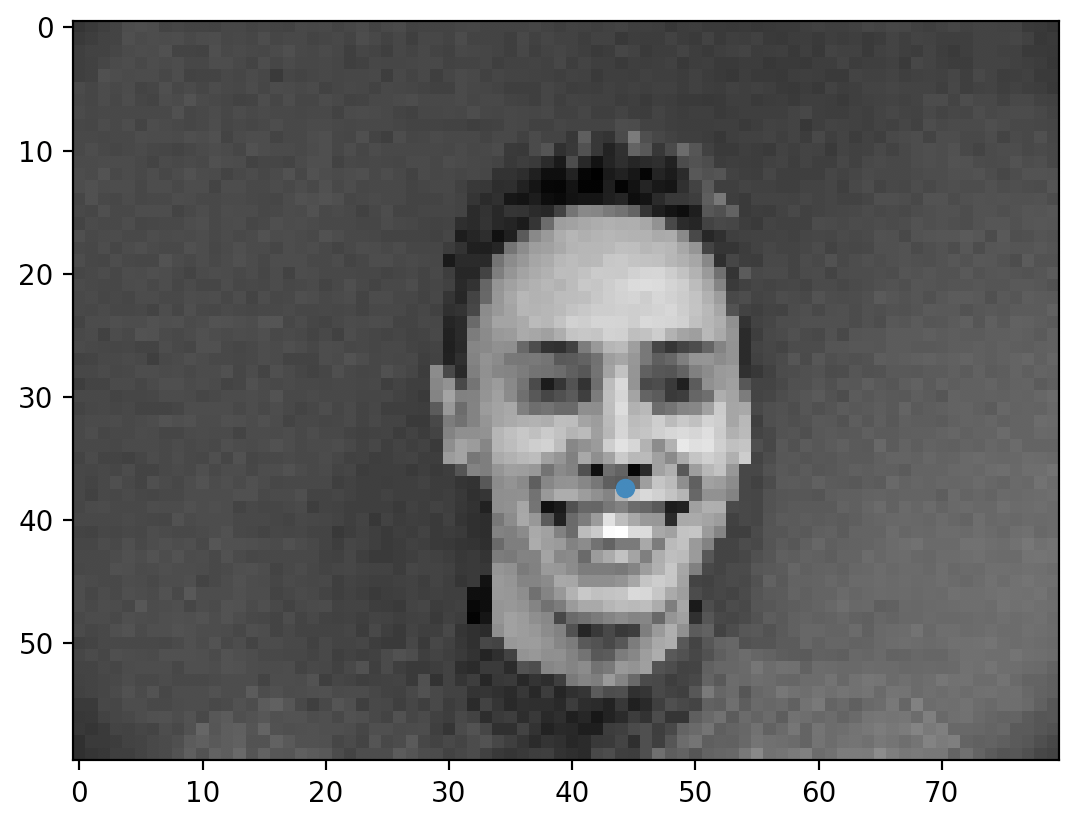
To accommodate the data from the IMM Face Database, I wrote my own Dataloader that read in images and their corresponding keypoints. This loader first converted the image into grayscale then normalized the data into float values between -.5 and .5. Following that, it resized the images into size 80x60. Here are a few images from the dataset along with it corresponding nose keypoint:

|
|

|

|
Model
The architecture for the CNN I used is as follows:
| Layer
| Kernel Size
| Input / Output Size
|
| Conv2d - 1
| 3x3
| (1, 12)
|
| Conv2d - 2
| 3x3)
| (12, 12)
|
| Conv2d - 3
| 3x3
| (12, 32)
|
| Linear - 4
| -
| (2240, 1024)
|
| Linear - 5
| -
| (1024, 2)
|
Along with 2d Max Pooling and ReLU after every convolutional layer, the CNN used was running 25 epochs with mean squared error loss (MSE), Adam optimizer, and a learning rate of 1e-3. However, I did some hyperparameter tuning on the filter size and learning rate to see which model outperformed the others:
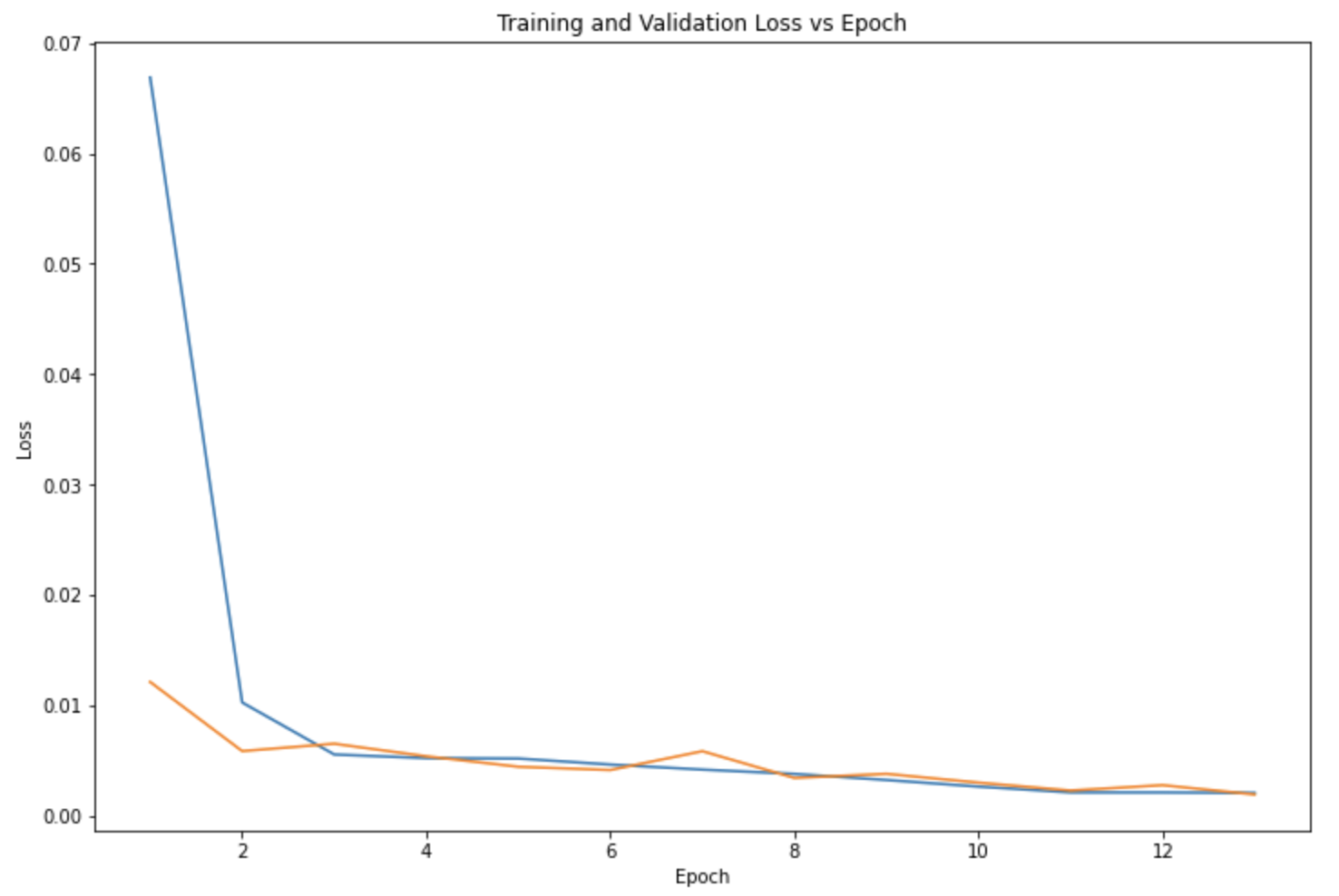 3x3 Kernel, 13 Epochs, 20 Batch Size, .001 Learning Rate
3x3 Kernel, 13 Epochs, 20 Batch Size, .001 Learning Rate
|
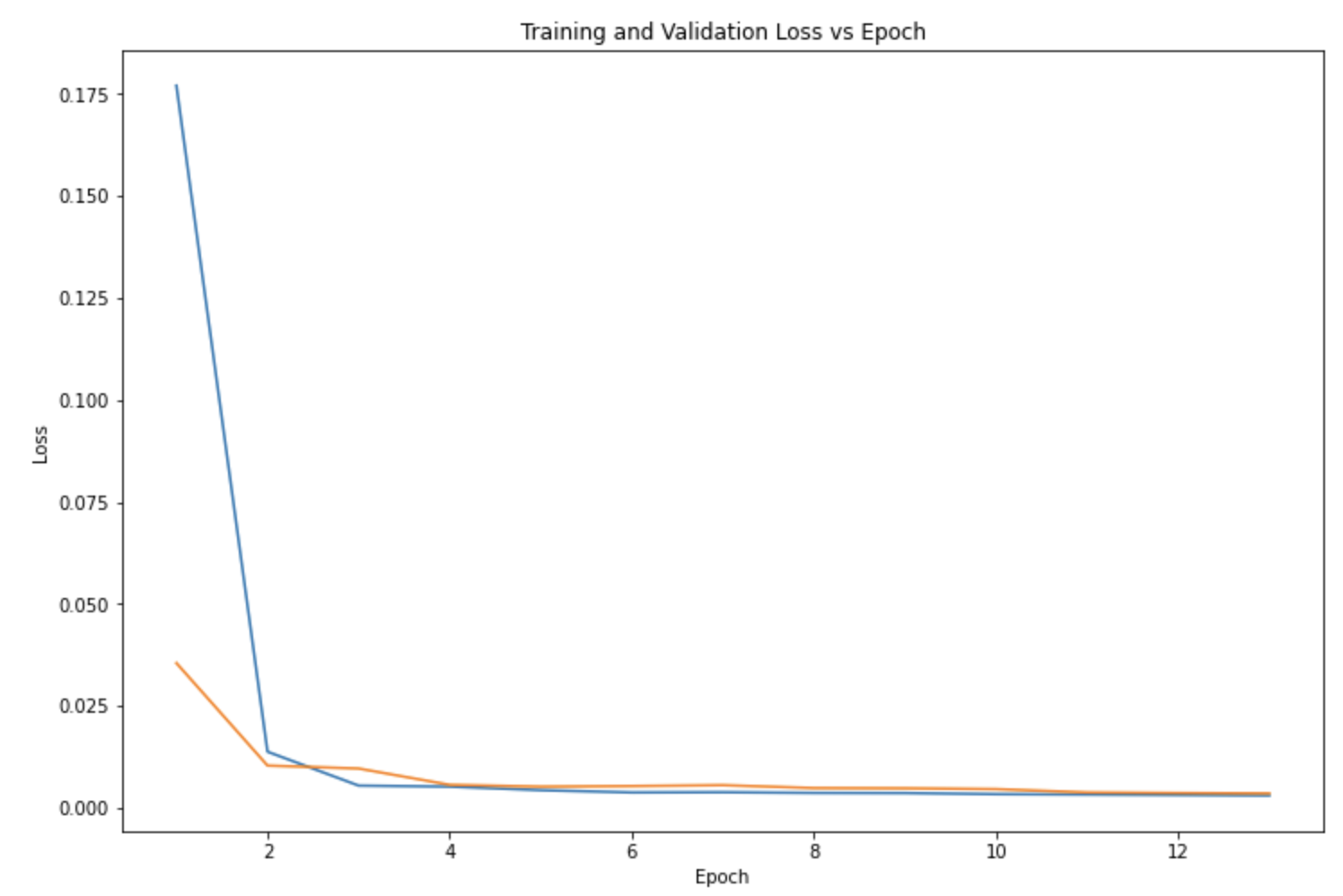 3x3 Kernel, 13 Epochs, 20 Batch Size, .0001 Learning Rate
3x3 Kernel, 13 Epochs, 20 Batch Size, .0001 Learning Rate
|
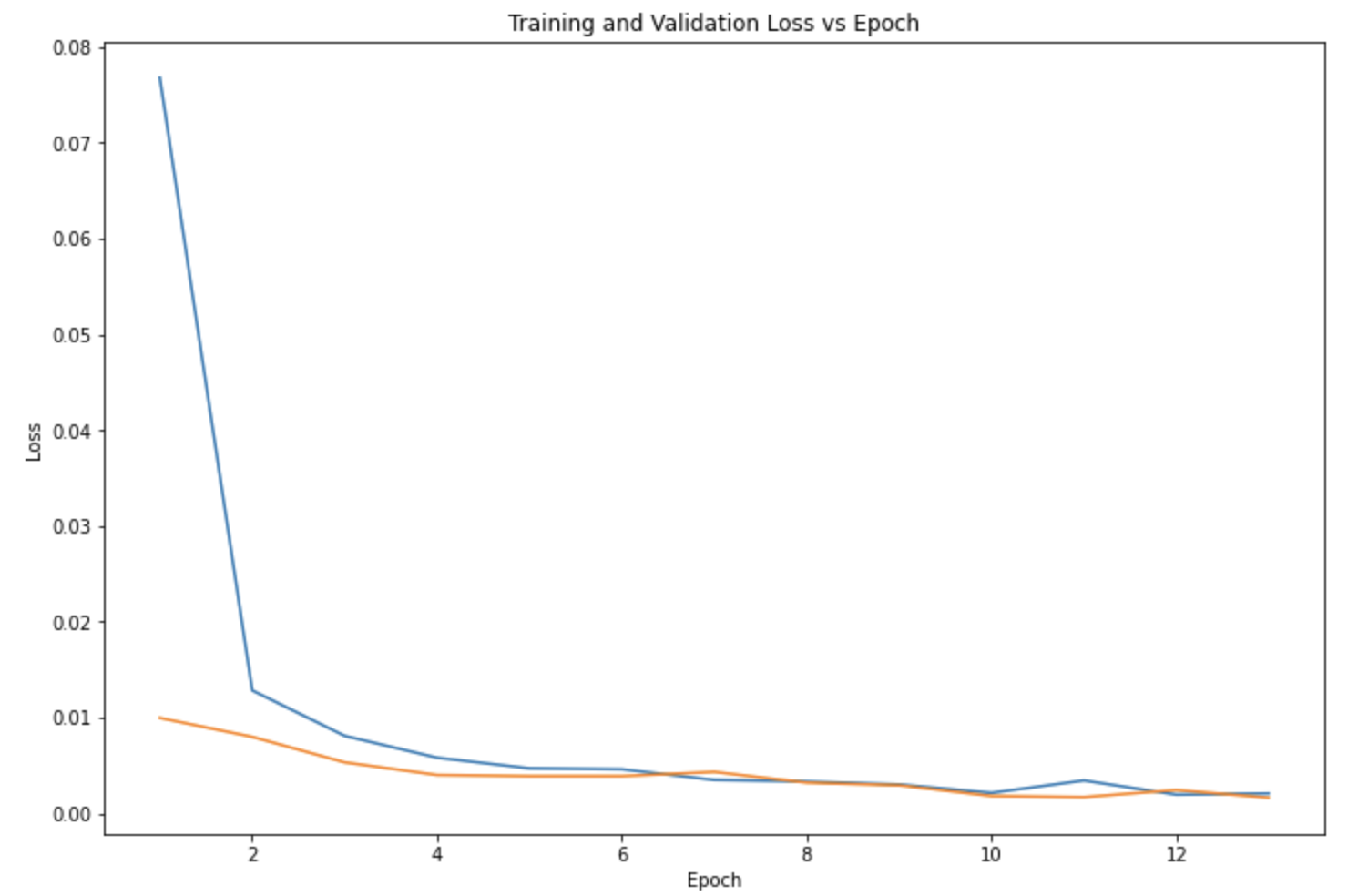 5x5 Kernel, 13 Epochs, 20 Batch Size, .001 Learning Rate
5x5 Kernel, 13 Epochs, 20 Batch Size, .001 Learning Rate
|
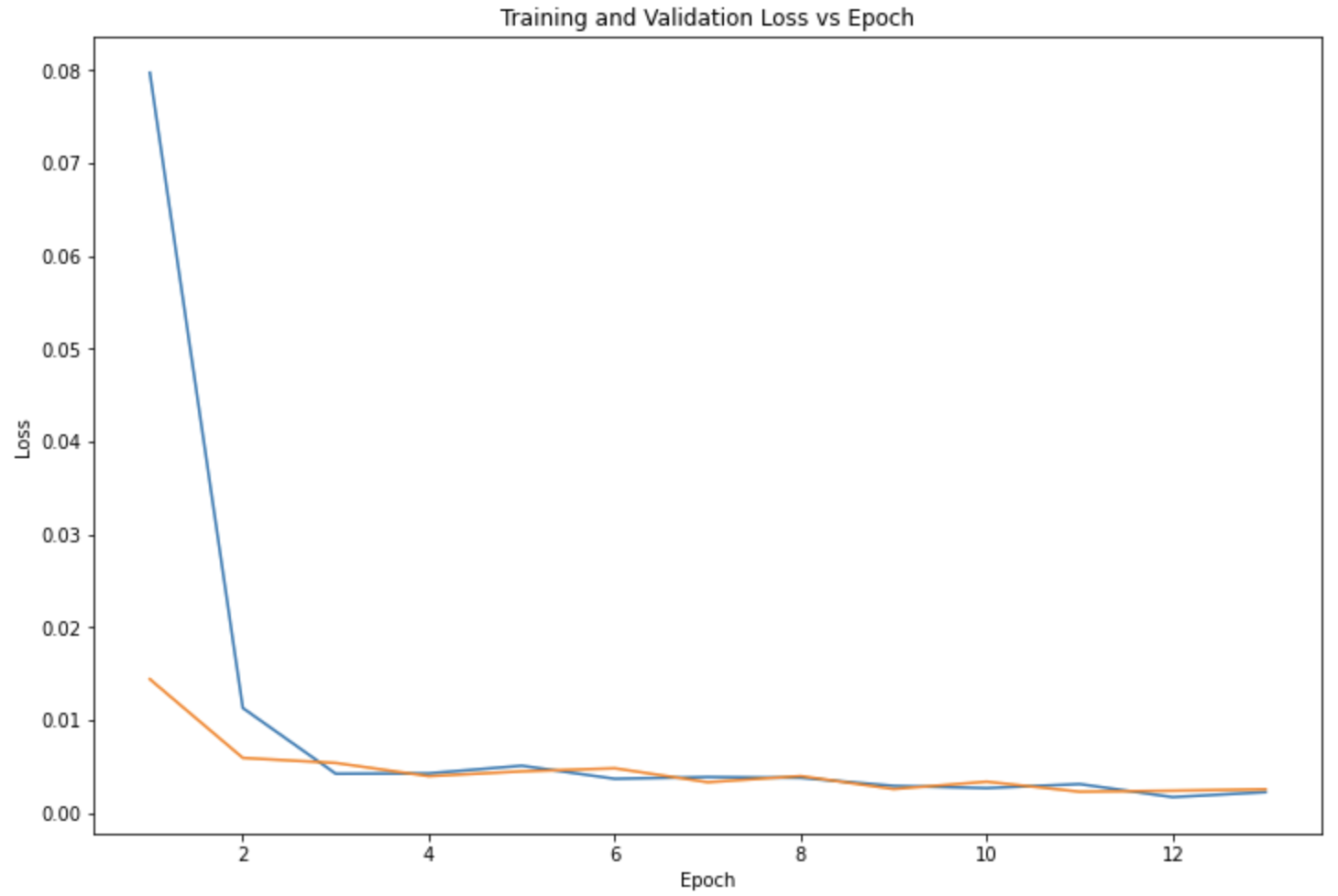 7x7 Kernel, 13 Epochs, 20 Batch Size, .001 Learning Rate
7x7 Kernel, 13 Epochs, 20 Batch Size, .001 Learning Rate
|
There are some differences in the performances of the models when testing different parameters such as the difference between the validation loss (orange) and training loss (blue). Ultimately, the parameters I chose to use was the 3x3 Kernel Size, 13 Epochs, 20 Batch Size, and .001 Learning Rate. Here are a few results that the model predicted for the nose keypoint (blue) in comparison to the ground truth nose location (red):
 Success 1
Success 1
|
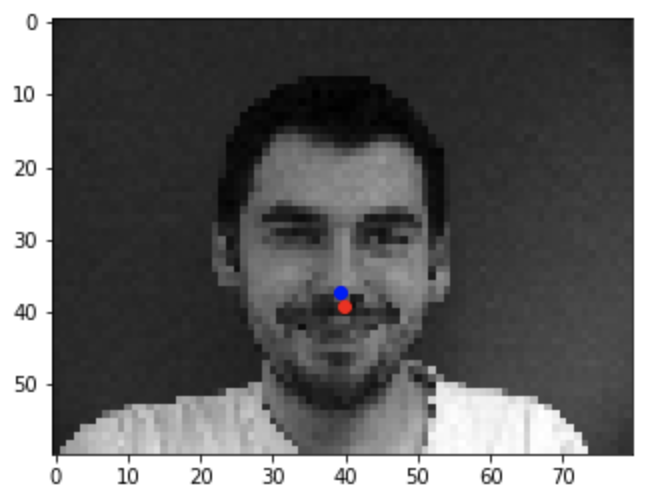 Success 2
Success 2
|
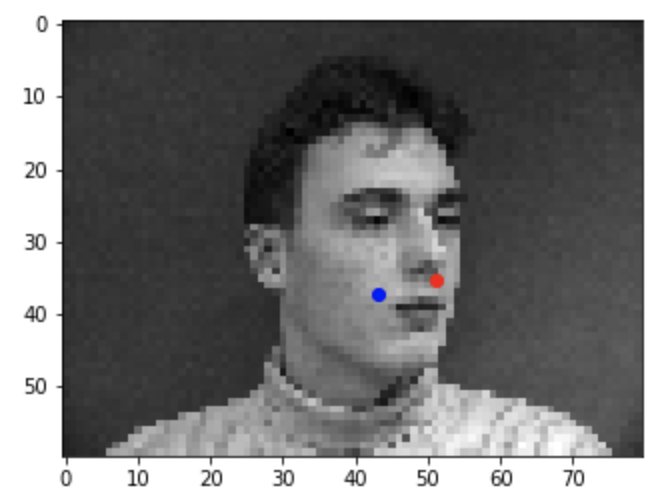 Failure 1
Failure 1
|
 Failure 2
Failure 2
|
Some nose keypoints were predicted really close to the actual keypoint (the first two) while other predictions weren't too great (the last two). As for why the model didn't predict some nose keypoints too accurately, it may be due to differences in color making it seem like other facial features were the nose or due to the orientation of the faces (for example, tilted or turned away from the camera).
Part 2: Full Facial Keypoints Detection
Data Processing
For this section of the project, rather than trying to predict just the nose keypoint, we want to predict 58 facial keypoints for an larger 160x120 image. With the dataset being pretty small, we have to incorporate some data augmentation to avoid overfitting. For every image in the training set, I assigned it a 50% chance of being randomly shifted by a max of 10 pixels in all four directions or being rotated by a max of 15 degrees clockwise or counterclockwise. This allows for the model to train on more diverse data and hopefully perform better on non-traditional images.
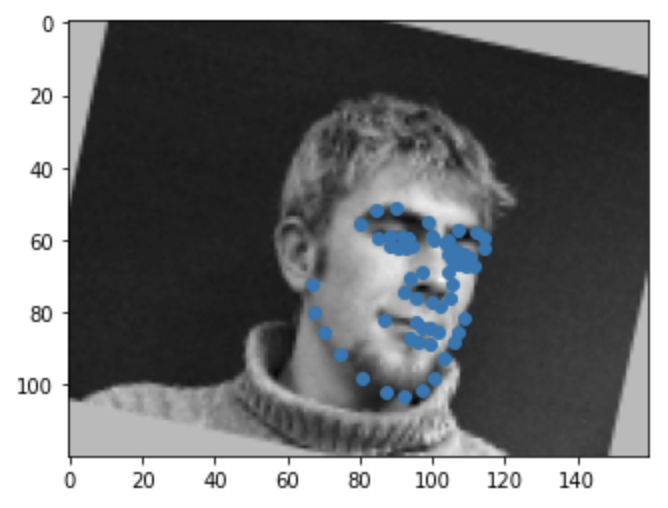
|

|

|
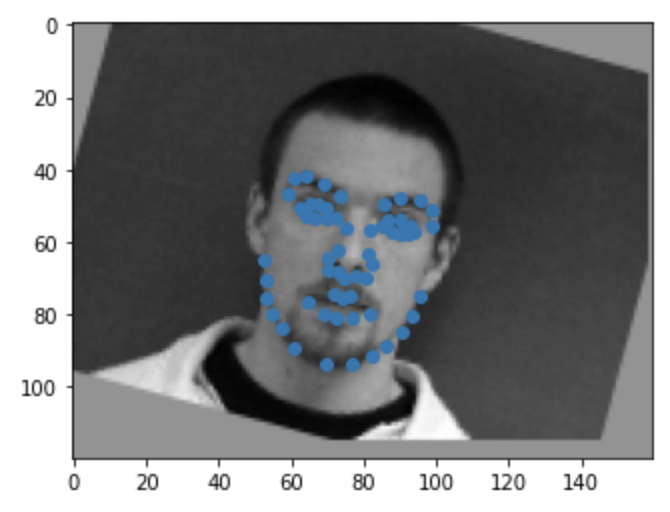
|
Model
The architecture for the CNN I used is as follows:
| Layer
| Kernel Size
| Input / Output Size
|
| Conv2d - 1
| 3x3
| (1, 12)
|
| Conv2d - 2
| 3x3)
| (12, 32)
|
| Conv2d - 3
| 3x3
| (32, 64)
|
| Conv2d - 4
| 3x3
| (64, 32)
|
| Conv2d - 5
| 3x3
| (32, 12)
|
| Linear - 4
| -
| (180, 150)
|
| Linear - 5
| -
| (150, 116)
|
Along with 2d Max Pooling and ReLU after every convolutional layer, the CNN used was running 40 epochs with a batch size of 5, mean squared error loss (MSE), Adam optimizer, and a learning rate of 1e-3.
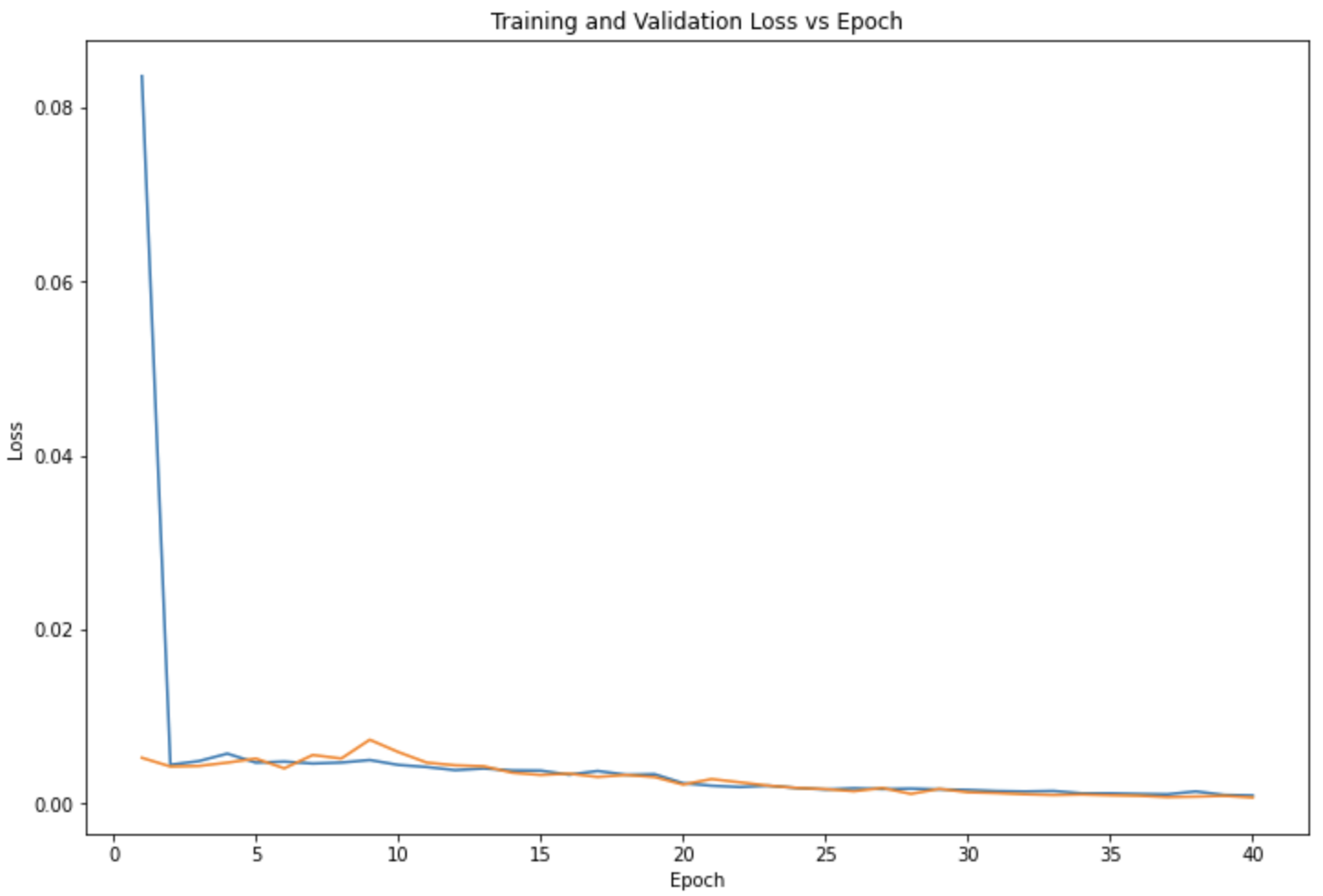 3x3 Kernel, 40 Epochs, 5 Batch Size, .001 Learning Rate
3x3 Kernel, 40 Epochs, 5 Batch Size, .001 Learning Rate
|
Here are some examples of predicted keypoints from the training (blue) and the real keypoints (red):
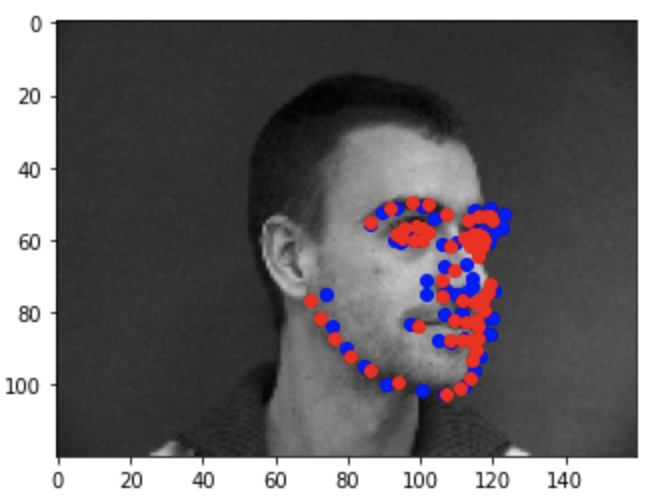 Success 1
Success 1
|
 Success 2
Success 2
|
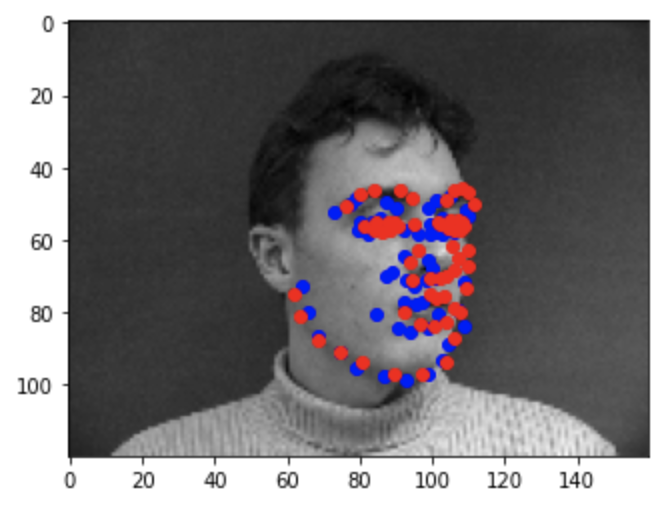 Success 3
Success 3
|
 Failure 1
Failure 1
|
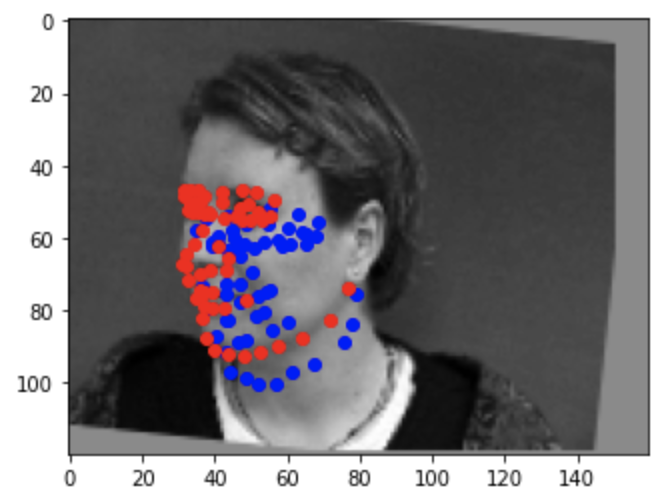 Failure 2
Failure 2
|
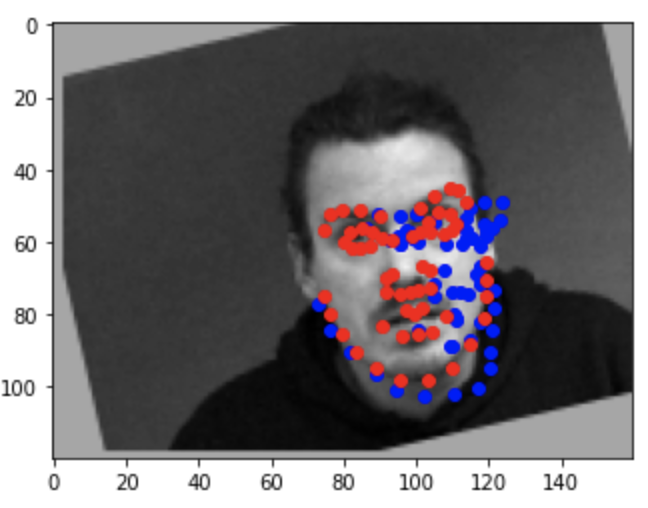 Failure 3
Failure 3
|
Some keypoints were predicted really close to the actual keypoints (the first three) while other predictions weren't too great (the last three). As for why the model didn't predict some keypoints too accurately, it may be due to the lack of diversity in the data set (i.e people looking to the side or people with different hair styles).
Part 3: Train With Larger Dataset
Data Processing
This is similar to the previous part in that we are trying to predict keypoints for given images. However, in this section, we are working with the iBUG's Faces In-the-Wild Dataset which is a lot larger than the previous datasets. This new dataset has 6666 images with 68 corresponding keypoints each. For each image, we are given a bounding box to which we "crop" the image and then resize to a 224x224 image. I use the same transformations--rotation and shifting--as the previous section. Here are some examples from the dataloader after cropping to the bounding box and some transformations:
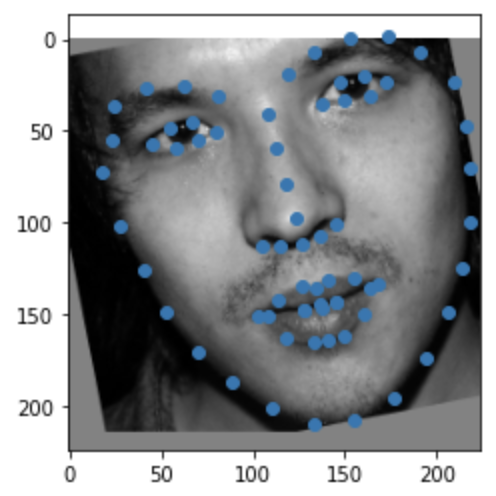
|
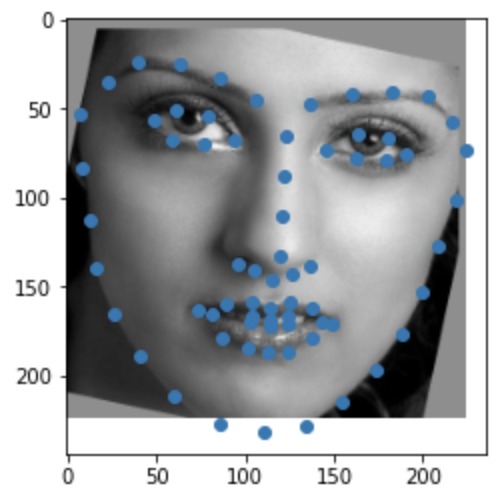
|
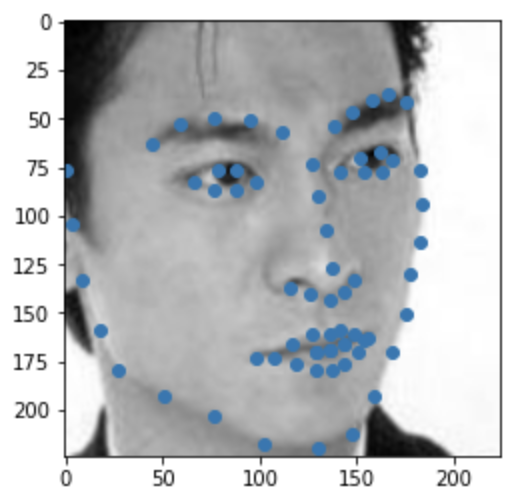
|
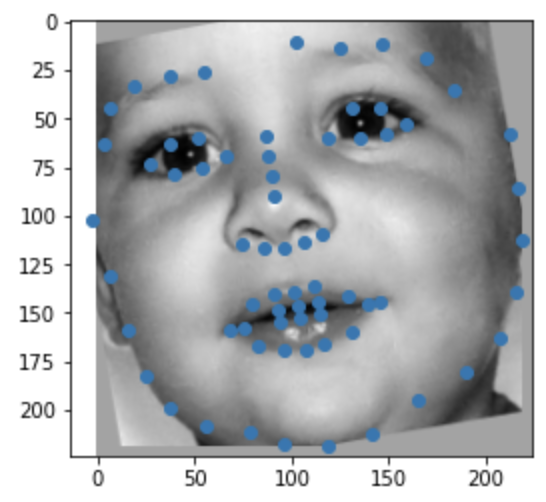
|
Model
The architecture for the CNN I used is ResNet18. I trained on 95% of the data and kept the remaining 5% for validation. Tto take into account grayscale images which has only one channel compared to the three that ResNet18 is configured to accept, I had to change the first layer of the network. In particular, I took the weights from ResNet18's first convolutional layer and averaged them together into one set of weights. Then, I used this as the new weights for the first convolutional layer of the network which takes in one channel. Following that, I changed the output of the network to be the number of coordinates per image (68 * 2) along with adding another linear layer.
| Layer
| Kernel Size
| Input / Output Size
|
| Conv2d - 1 (averaged weights)
| 7x7
| (1, 64)
|
| -
| ResNet18
| -
|
| Linear
| -
| (512, 256)
|
| Linear
| -
| (256, 136)
|
I configured ResNet18 to be running 10 epochs with a batch size of 32, mean squared error loss (MSE), Adam optimizer, and a learning rate of 1e-3.
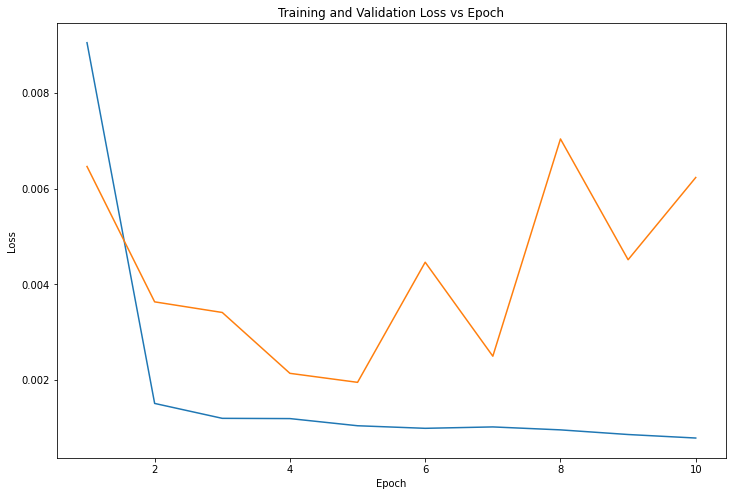 ResNet18
ResNet18
|
Here are some examples of predicted keypoints from the test set:
 Test 1
Test 1
|
 Test 2
Test 2
|
 Test 3
Test 3
|
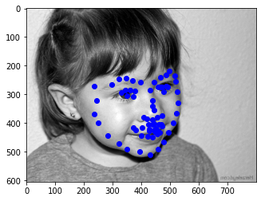 Test 4
Test 4
|
Here are some examples of predicted keypoints for the my own image collection:
 Rachel
Rachel
|
 Malleeka
Malleeka
|
 Winwin
Winwin
|
 Rachel
Rachel
|
 Malleeka
Malleeka
|
 Winwin
Winwin
|
The model didn't work too well in predicting keypoints because it looks like the model is overfitting on the custom pictures despite loss being low for the test dataset. These bad predictions may be due to features such as sunglasses and head tilts that wasn't really seen in training set.