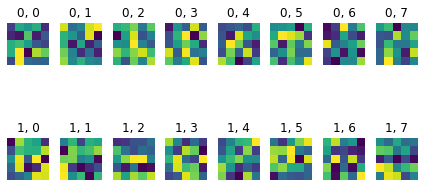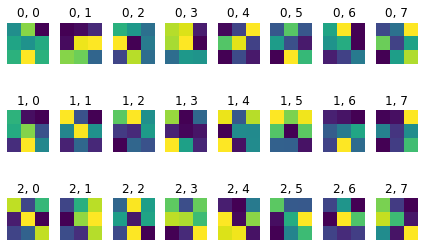Project 5 Facial Keypoint Detection with Neural Networks
2021 Fall CS 294-026 Xinwei Zhuang
Part 1: Nose Tip Detection
IMM Face Database is used for automatic nose tip detection. The dataset includes 240 facial images of 40 persons and each person has 6 facial images in different viewpoints. A preview of the used dataset is shown below.
Dataset for training
The first 32 persons are used as training set (total 32 x 6 = 192 images) and the images of the remaining 8 persons (index 33-40) (8 * 6 = 48 images) as the validation set.
Dataset after preprocessing
Then a convolutional neural network is constructed. The layer of the CNNs are:
convolutional layer
ReLu
max pooling
convolutional layer
ReLu
max pooling
convolutional layer
ReLu
max pooling
FC layer
ReLu
FC layer
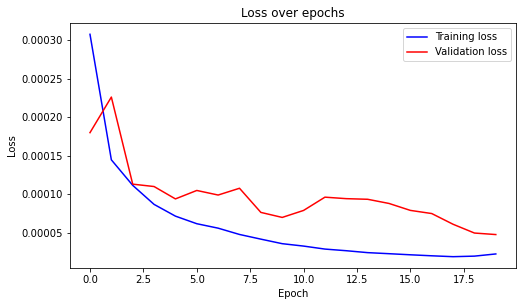
Training loss and validation loss is shown as below for kernel size = 5 with the previous layer setting.
Mean Squared Error
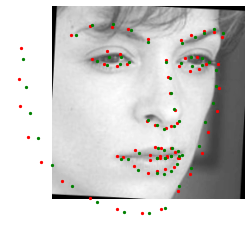
The trained nose tip recognition network on test images are shown below. The red dot is the ground truth, and the green dot is the predicted nose tip.
Success cases
Failure cases
The possible reason could be that my filter kernel size is not large enough to investigate the full picture. The failure cases are detecting tip along the line of the face, which might also be a 'tip', but not a nose tip.
Some noticed influence by hyperparameter:
Large learning rate will cause diverge
Increasing batch size will make CNN perform better
Padding doesn't actually change the performance
Enlarge the kernel size will cause a quicker convergence
Part 2: Full Facial Keypoints Detection
To scale up from nose tip detection to full facial keypoints detection, the input data is labeled by 58 points instead of 1 point. Then, because the dataset is small, image augmentation is performed. The implemented image augmentation including:
randomly changing the brightness in 50% percent
randomly rotating the face between -15 to 15 degrees
randomly shifting the face within 10% of the image size
Sampled loading data after preprocessing are shown below.
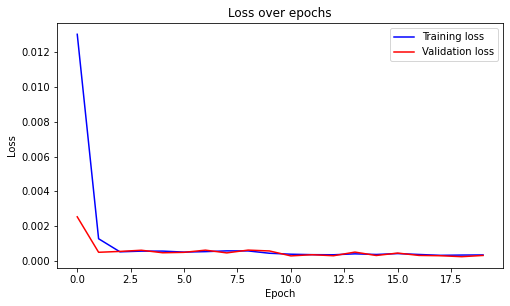
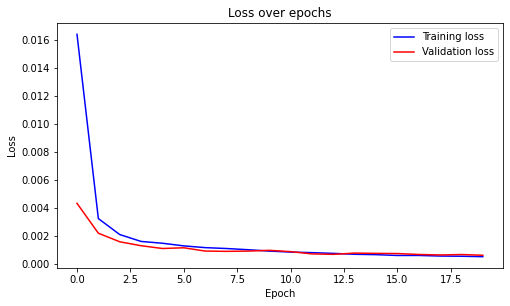
Training loss and validation loss is shown as below.
Mean Squared Error
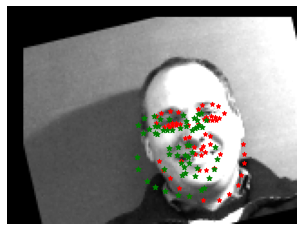
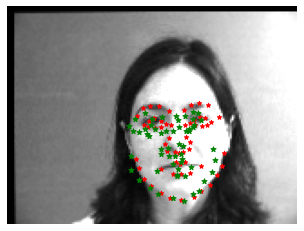
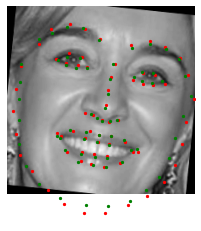
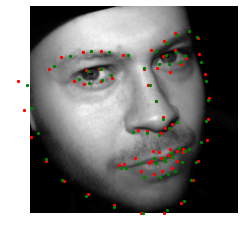
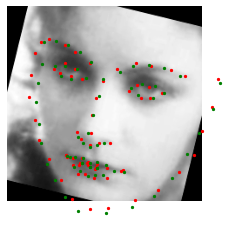
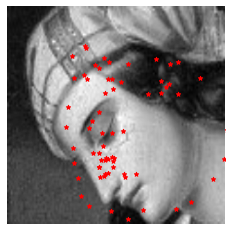
The trained nose tip recognition network on test images are shown below. The red dot is the ground truth, and the green dot is the predicted feature face. I also augmented test data, so even the success cases is not super attached to the ground truth, but not too bad. It can recognize rotation and shifting.
Success cases
Failure cases
The failure case, however, is a bit messy. Some observations: image with large rotation doesn't work well, the profile photo cannot be recognized, and there is some rotation even the photo doesn't seem to be rotated. Also it can be overfitting to small data size.
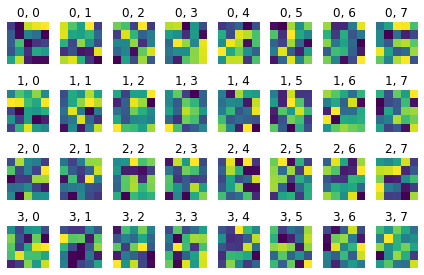
Learnt feature visualisation
The first index is , and the second index is
kernel 1
kernel 2
kernel 3
kernel 4
kernel 5
kernel 6
Part 3: Train With Larger Dataset
Sampled loading data after preprocessing are shown below.
Dataset after preprocessing
ResNet-18 is used. Detailed architecture see below.
Training loss and validation loss is shown as below.
Mean Squared Error
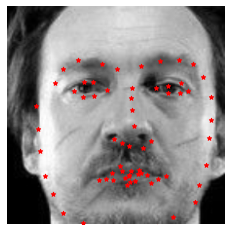
Predictions on test data.
Selected predictions on Kaggle
The mean absolute error for Kaggle is 8.36320.
Selected predictions on own selected photo
The performance is plausible. It performs better when the input image is a front face. But when it's obstructed by hair, or it's not a front face, or it's not a human face (probably shouldn't try the doge one since we don't have dog data), it performs not so good.
Bells & Whistles
Heat map regression
Sampled loading data after preprocessing are shown below.
Dataset after preprocessing
Pixel-wise fully convolutional (FC) network is used, and the face feature extraction becomes a pixelwise classification problem. Detailed architecture see below.
What I've learnt
The training takes much longer time than I think, and many unexpected error happens. Will do it early.
Batch size is highly relavent for training speed. But the training process converges much quickly than I thouhgt (only within 10 epoch).
Reference
Dataset
IMM Face Database:
https://web.archive.org/web/20210305094647/http://www2.imm.dtu.dk/~aam/datasets/datasets.html