

In this project, learn how to use Convolutional Neural Networks to detect facial keypoints without having to use clicking anymore.
First, we created a dataloader that loads the images in grayscale, with pizel values from 0 to 255, normalzes the float values in range -0.5 to 0.5, and resized the images to 80x60. Below are some images sampled from my dataloader with the ground-truth keypoints, and just the nose ground-truth keypoints to pass into the CNN.




I then created a CNN to train the on batched of these images. The architecture of my network is in the below image. To train, I used a batch size of 4, learning rate of 0.001, and ran the model with MSE Loss and Adam Optimizer for 25 epochs.

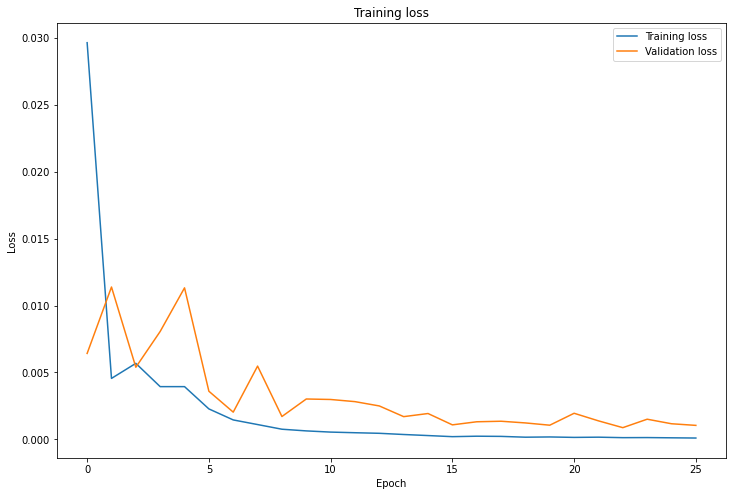
Here are some images where the network detects the nose properly:


Here are some images where the network detects the nose incorrectly:


Explaination: It is possible that the hair on the man in the second set of images confuses the model to not recognize it as hair but rather recognize the hair as part of the face, resulting in the predicted nose point to be higher than the ground-truth. This reflects the skew in the dataset when it comes to skin color.
Below are the changes from Part 1:
Below are some images with ground-truth keypoints sampled from the new dataloader:




Below is my FullFaceCNN architecture:

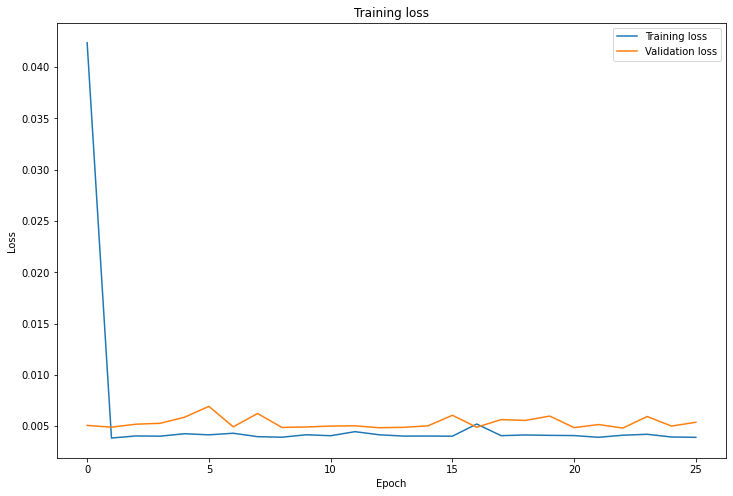
Again, I trained for 25 epochs with a batch size of 4 and learning rate of 0.001
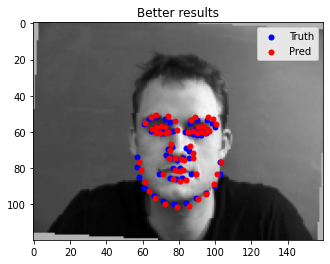
Here are some images where the network detects the face keypoints properly:

Here are some images where the network detects the face keypoints incorrectly:
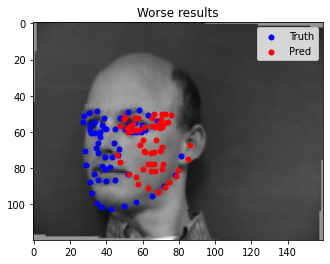

Explaination: It appears that the orientation of the face makes it harder for the model to predict the face keypoints. This is likely because the dataset has more images facing forward, so turned faces are harder for the model to detect keypoints.
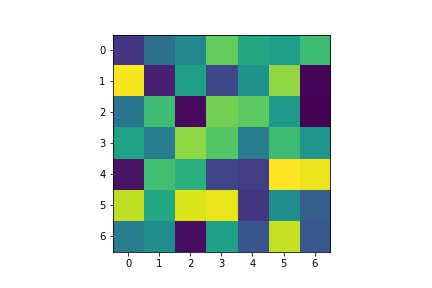
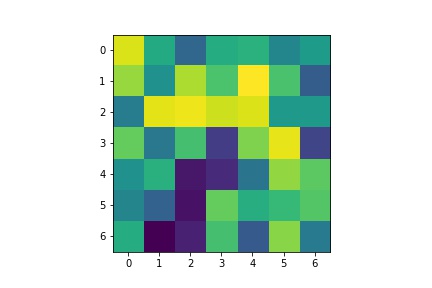
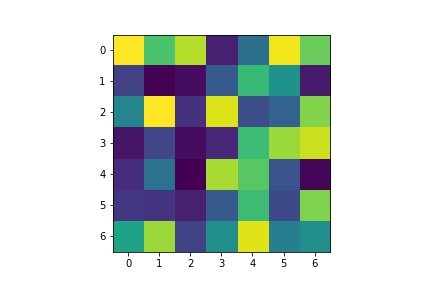
Below are the learned filters of my FullFaceCNN for the first Conv1 layer with 12 channels:
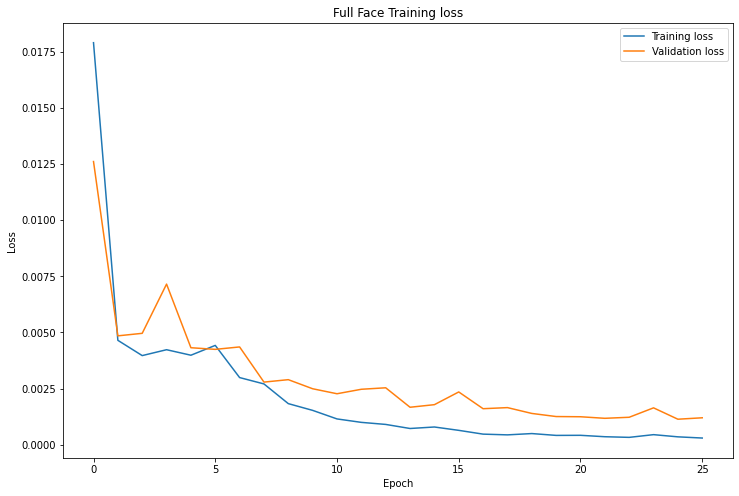
Below are the changes from Part 2:
Below are some images with ground-truth keypoints sampled from the new dataloader:




Below is the architecture of my model. I trained with batch size of 4, learning rate of 0.001 and trained for 20 epochs.



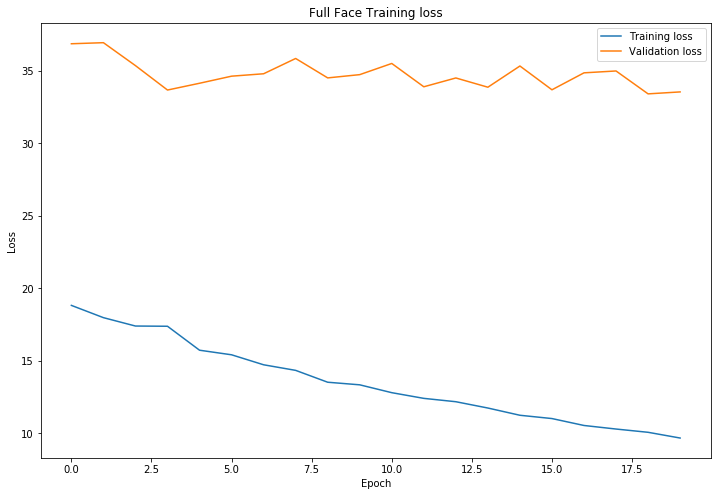
My Kaggle score is 7.95279. Below are the results of predictions on the test set submitted to Kaggle.



I also ran the model on some of my own images. When doing this, the biggest impact on quality of the results is the bounding box provided. With good bounding boxes, it resulted in better facial predictions. Larger bounding boxes resulted in worse predictions. Below are the resuls of good bounding boxes:








Below are the results of bad bounding boxes:






I used my model for my Project 3 to identify points to do the morph of images. Below are the original images:


Here are the facial points identified on these images:




Finally, here's the morphed gif
