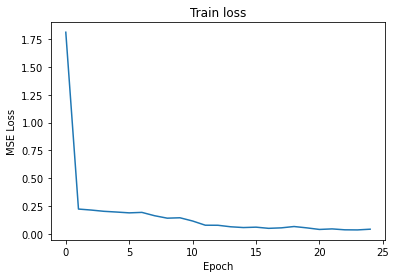
Training Loss Part1 per epoch for lr=0.001
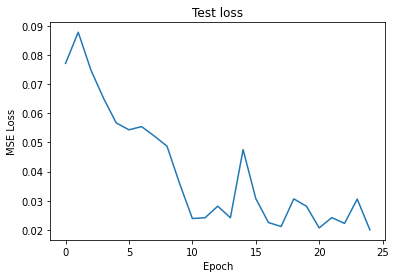
validation Loss Part1 per epoch for lr=0.001
We would first parse and get all the images and labels from the imm_face_db folder where we would then create a new Dataset that could give out the images and labels on the go. We would then pass this dataset on a DataLoader which we could iterate through. In the Dataset we could split the images into train and validation sets which could be divided into 192 training images and 48 images as the validation set.
We would then create the neural network with 3 convolutional layers each with a Relu Layer and a max_pool layer. We would then end the network with 2 fully connected layers giving out the output of the predicted labels.
After running the training set for 25 epochs and measuring the training and validation loss by the MSELoss with 0.001 learning rate, We would get the following training error graph and the validation error graph for the given epochs.
Training Loss Part1 per epoch for lr=0.001
validation Loss Part1 per epoch for lr=0.001
Plotting the ground-truth points as the green points and the predicted as the red points

We could observe that we were able to predict several images with correct prediction labels. Though there are still some images where the predicted labels are inaccurate. A possible reason for this is due to the small amount of data that we have. Where we only have 192 images to train and they are all with similar features which might cause more overfitting.
As we have only detected with only the nose tip of the images, we will now start to train and detect all 58 points of each image. In addition to that, we would apply more data augmentation to the image to add more data for the training. We could augment the images with random rotations of between -15 to 15 degrees and random translations of 10 pixels.
In doing this data augmentation, we would also need to update the labels to be consistent with the images.
We would then train these images on a neural network of 5 convolutional layers with a learning rate of 0.00075. Which in this case we would only apply a total of 3 max_pool layers on the 5 convolutional and ReLu layers and would have the final fully connected layer return an output channel of 58 * 2, which corresponds to the number of labels of each image
I got the following training and validation losses from a total of 75 epochs:
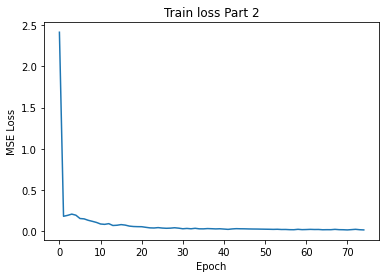
Training Loss Part2 per epoch for lr=0.00075
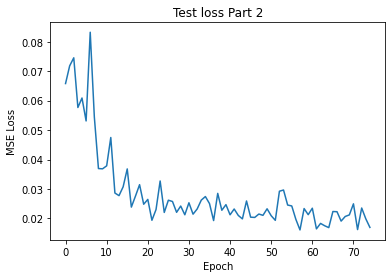
validation Loss Part2 per epoch for lr=0.00075
Plotting the ground-truth points as the green points and the predicted as the red points




We could observe that although we were able to accurately predict several images points, we still got inaccurate predictions on several other images. A possible reason for this is because there are still an insufficient amount of training data to accurately predict all images as we have only applied several data augmentation on the images.
For this part, we would then try to train from a larger dataset of a total of 6666 images with varying sizes and 68 annotated facial key points.
We would be using a resnet18 network from torchvision.models but changing the first convolutional layer to take in only a single channel as the image is a single channel image. We also need to change the final fully connected layer to have an output channel of 68*2 corresponding to the coordinates of the facial keypoints.
When processing the images from this large dataset, we would also apply cropping on the image by the given bounding box from the data and resize the images into 224x224 dimensions. When training these datasets we would also apply the data augmentation that we implemented on Part 2 such as rotations and translations.
As we arbitrarily split the dataset into 80:20 for the training and validation set respectively, we would then run the training with a batch size of 128 with a learning rate of 0.00075.
I got the following training and validation losses from a total of 10 epochs:
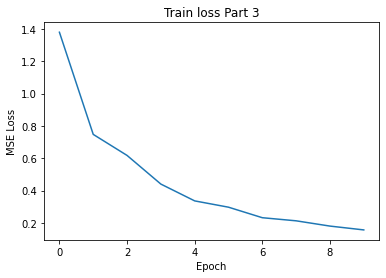
Training Loss Part3 per epoch for lr=0.00075
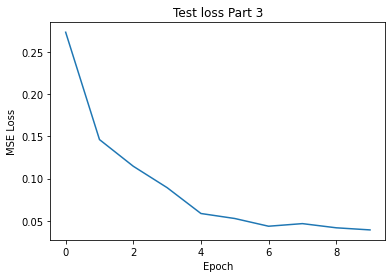
validation Loss Part3 per epoch for lr=0.00075
Plotting the ground-truth points as the green points and the predicted as the red points
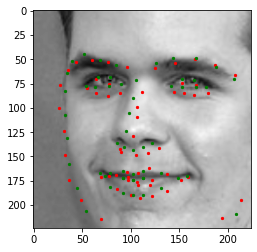



When we try to test the model to detect the labels_ibug_300W_test_parsed.xml dataset, and submit the result to kaggle we are able to get a decent score of 20.967
These are several results from predicting the test_parsed dataset


When we try to use this model to detect our own set of images, we get the following result


