Project 5: Facial Keypoint Detection with Neural Networks
CS 194-26 Fall 2021
Bhuvan Basireddy
Nose Tip Detection
I divided the 240 images into 2 dataloaders: one for training and other for validation. I converted the images to grayscale and normalized the float values between -0.5 and 0.5.
Then, I resized the image into 80x60 size and transformed the keypoints accordingly and sent this into the CNN to get the predicted nose tip points.
Below are the images sampled from the dataloader with the ground truth keypoints:
Ground Truth Keypoints
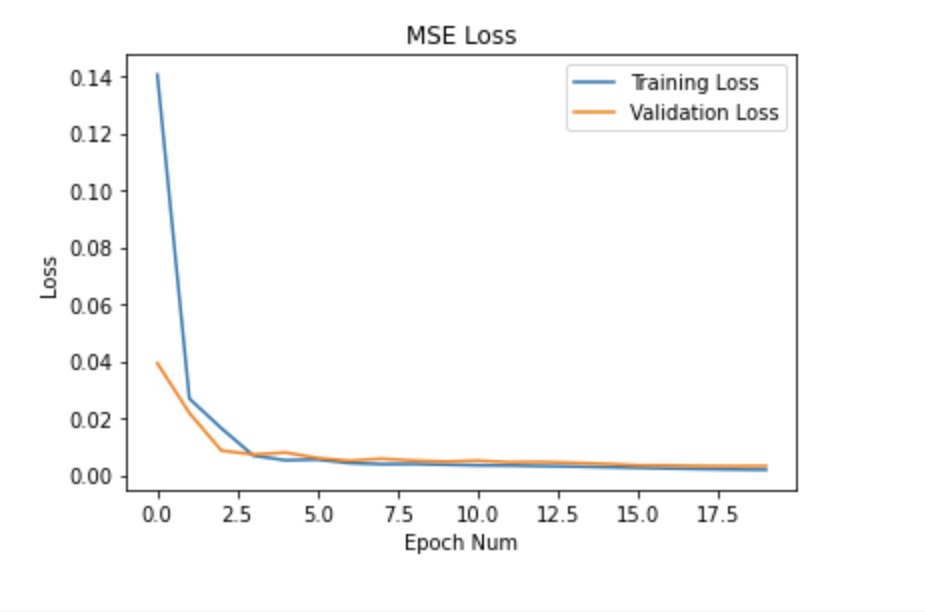
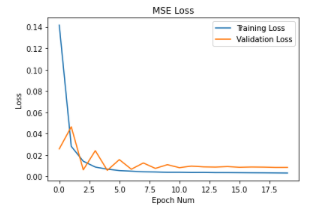
I trained this for 20 epochs with a learning rate of 1e-3 with a batch size of 32.
Here's the plot of the train and validation MSE loss:
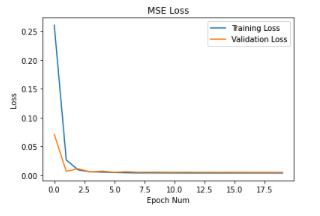
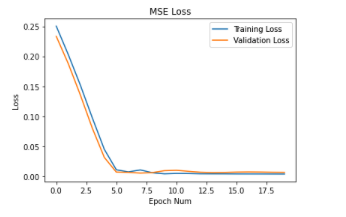
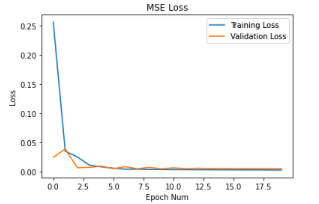
I varied the hyperparameters for learning rate, trying 1e-2, 1e-3, and 1e-4 and for
the filter size, trying 3x3, 5x5, and 7x7. I show the graphs of the losses below.
I used 1e-3 and 3x3 to be the best for the CNN since these were the most stable.
Learning Rate = 1e-2
Learning Rate = 1e-3
Learning Rate = 1e-4
Filter Size = 3x3
Filter Size = 5x5
Filter Size = 7x7
For the nose detection, a lot of points are correctly predicted, but some of the points aren't predicted well.
This is probably due to different lighting, rotation of the image, different facial expressions, and other features,
so our CNN can't generalize well because of its small size.
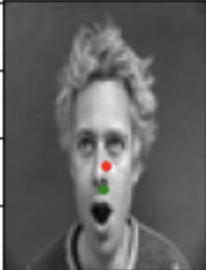
Here are some images showing the nose detection:
Good
Good
Bad
Bad
Full Facial Keypoints Detection
I do the same process as before, except with all the keypoints now. I resized the image to 240x180 size. I added
data augmentation, such as random rotation of -15 to 15 degrees, random translation by 5% of the image size, and random change of brightness and saturation by 10%.
Below are the images sampled from the dataloader with the ground truth keypoints:
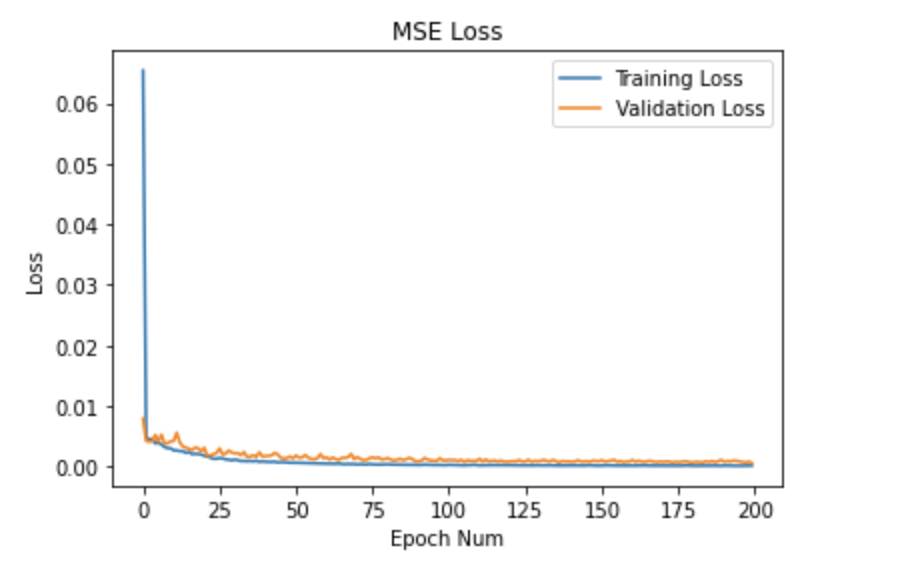
I ran the model for 200 epochs with a learning rate of 1e-4 and a batch size of 1.
Below is the architecture for my model:
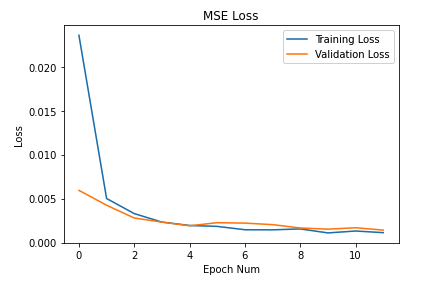
Here's the plot of the train and validation MSE loss:
Many images had the keypoints predicted fairly well, but some images didn't very good predictions.
This is probably due to our model being so small that it can't generalize well to all the transformations, such
as rotations, color jitter, and facial expressions.
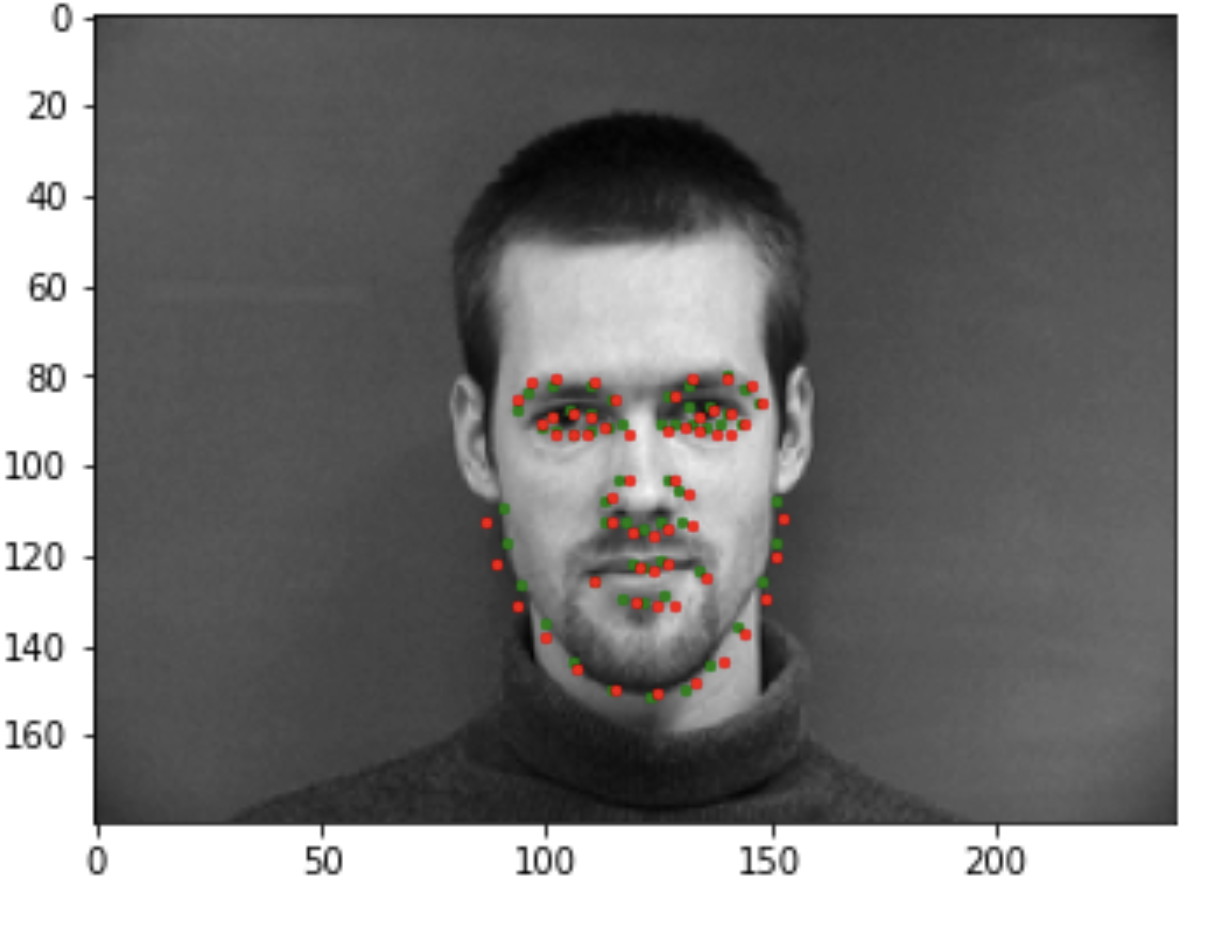
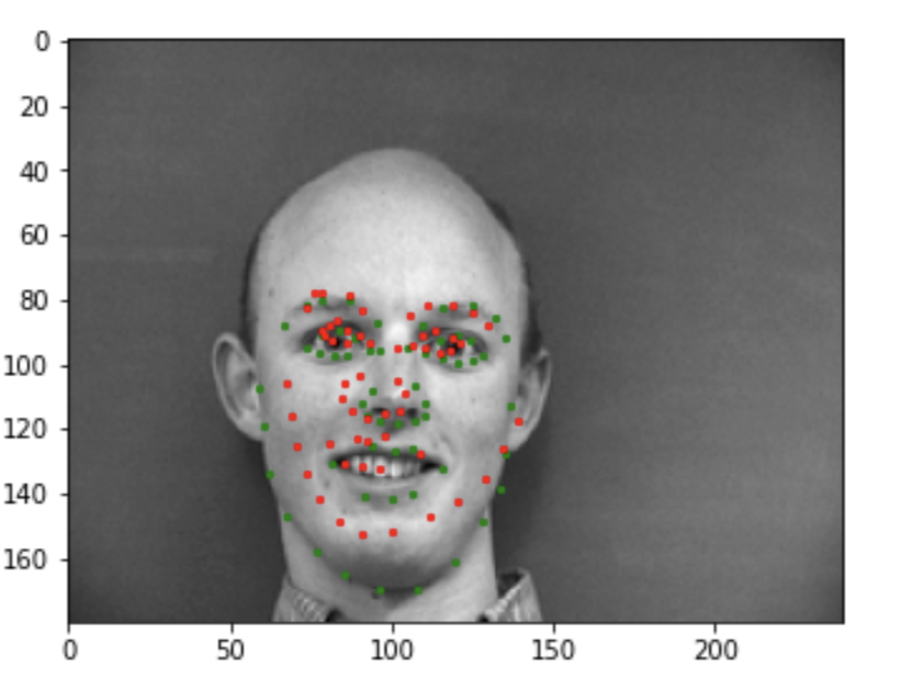
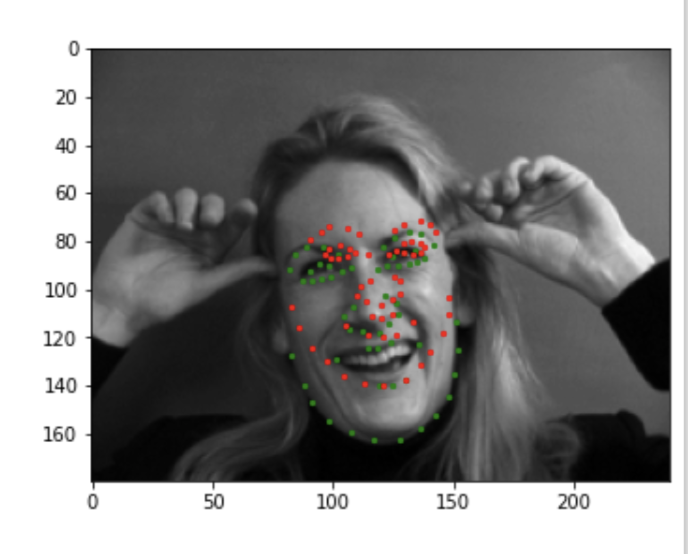
Here are some images showing the keypoints detection:
Good
Good
Bad
Bad
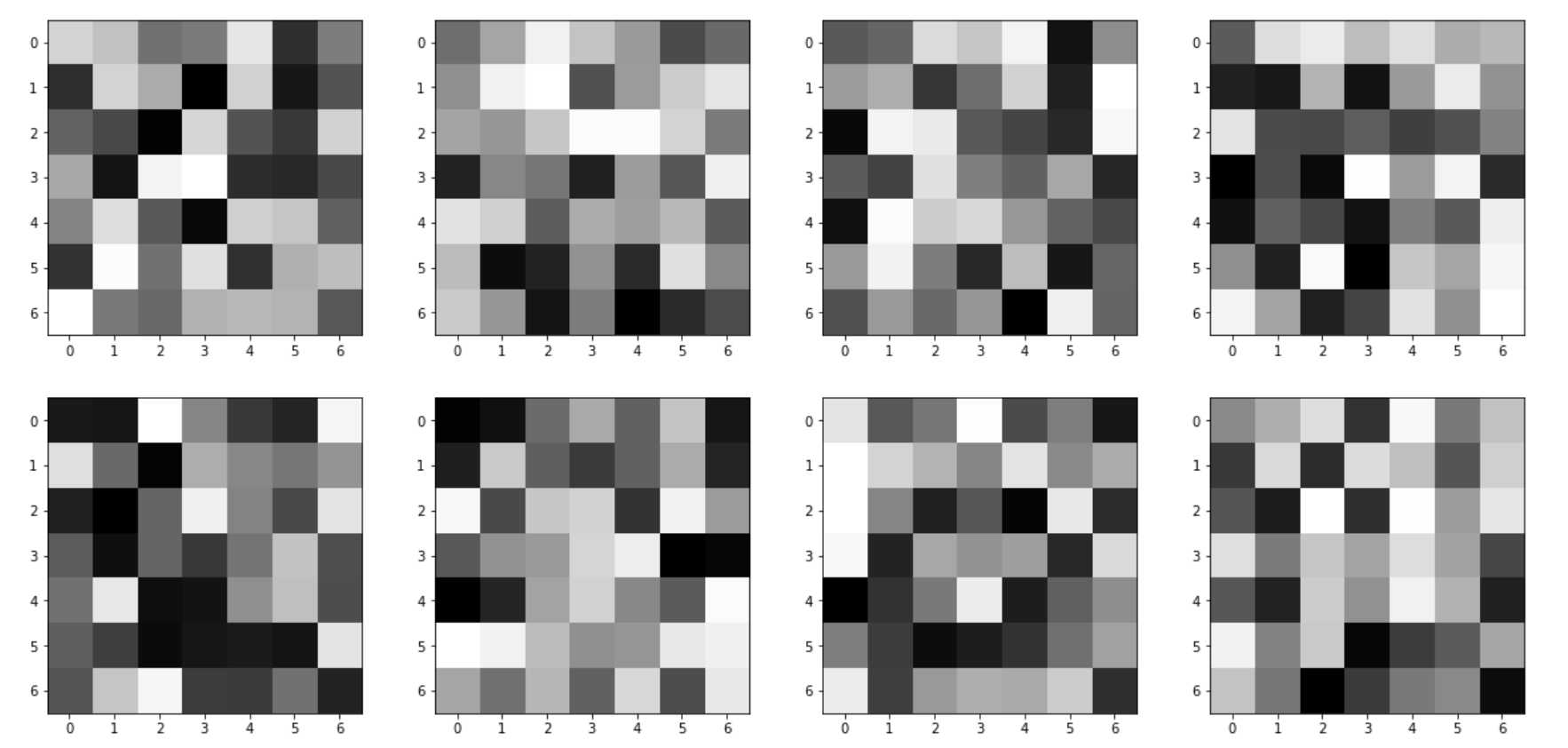
Here are the filters of the first conv layer visualized:
Train with Larger Dataset
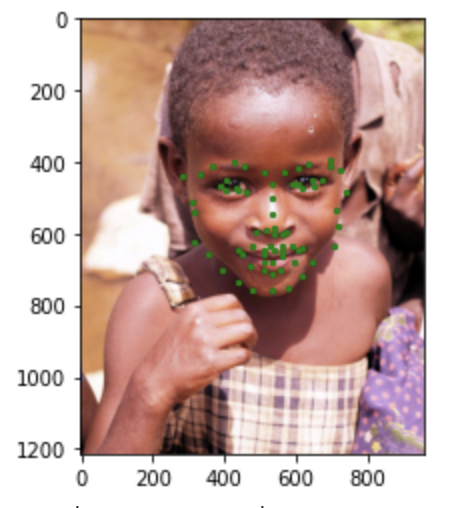
The mean absolute error that I got on Kaggle is 14.11930
I trained the model for 12 epochs with a learning rate of 1e-3 and a batch size of 64.
Below is the architecture for my model:
Here's the plot of the train and validation MSE loss:
Here are some images showing the keypoints detection on the testing set:
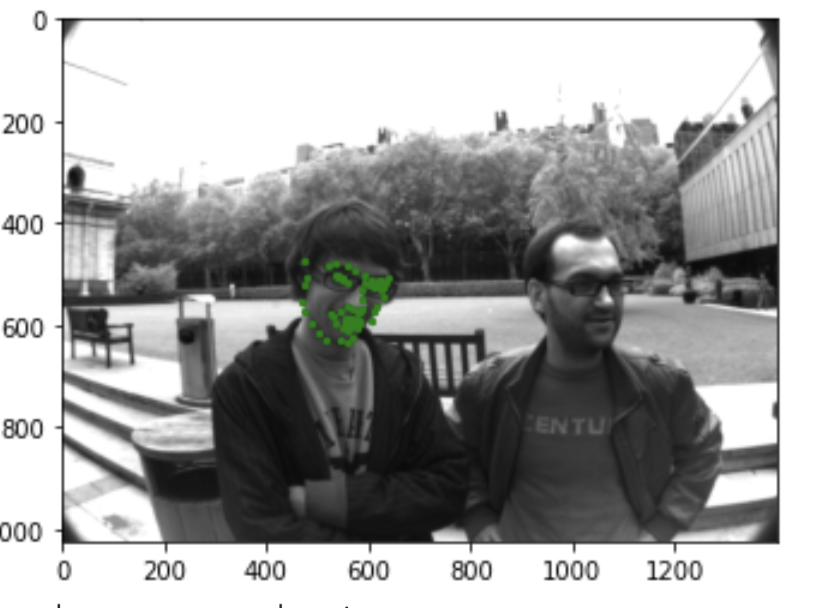
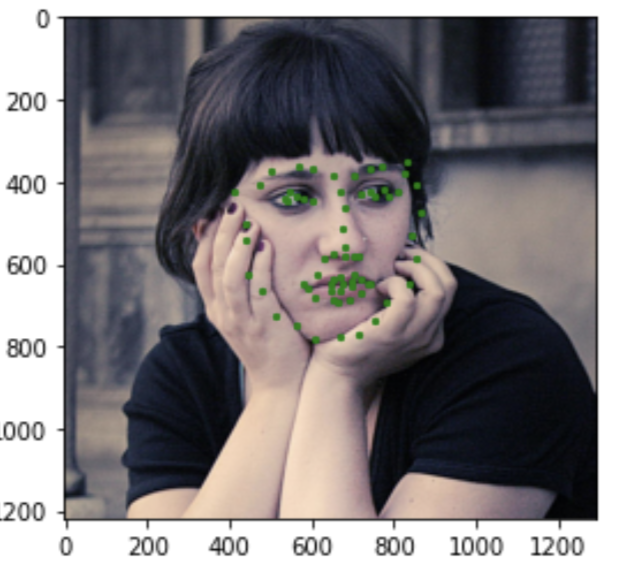
I tried the model on some random images I found. It does pretty well for the real people, giving fairly accurate keypoints.
On the cartoon image though, the model fails because Shaggy has very exaggerated features with his small face.
Here are some images from my collection with the keypoints:
B&W: Auto Face Morphing using ResNet
I used my ResNet on a group of images to automatically
get the keypoints for morphing between them. Here's the gif: