Facial Keypoint Detection with Neural Networks
In this project, we will explore using Convolutional Neural Networks for the task of automating facial keypoint detection. In project 3, we were able to create some really cool face morphing by applying transformations on key facial features to warp between two individual faces. However, the process of manually selecting points made the application cumbersome and not fun to use. So, we will automate this detection of key facial points by training a CNN to predict these for us. There are lots of high quality datasets that contain annotated images of faces with key facial features. Our task here is to train the CNN to predict what these annotated points are given only the input image.
Nose Tip Detection
In order to begin this journey into automating facial keypoint detection, we start with the simple task of detecting the tip of the nose. Here are examples of what we will train a model to predict.
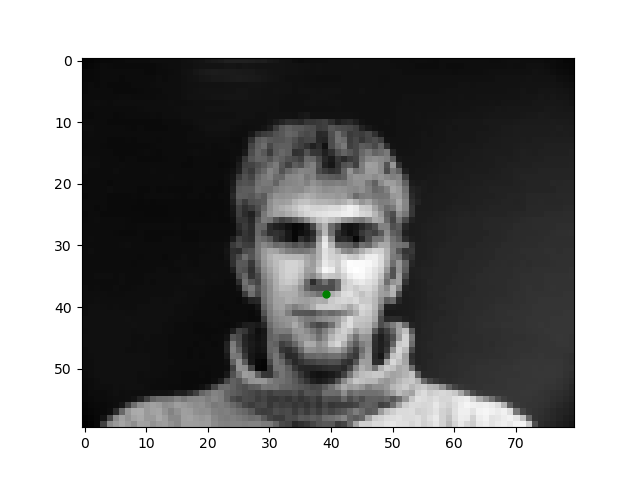
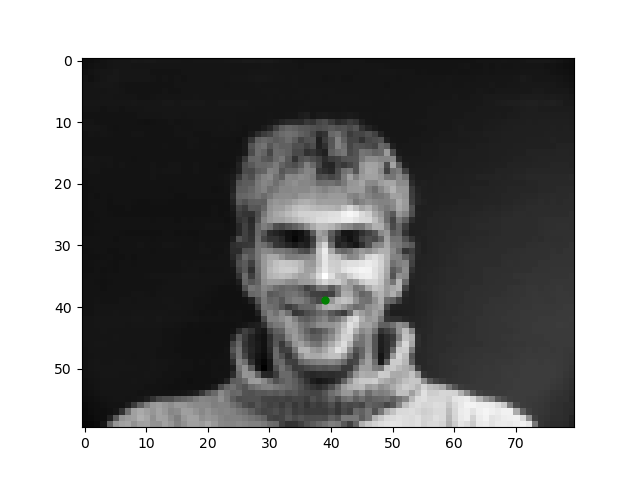
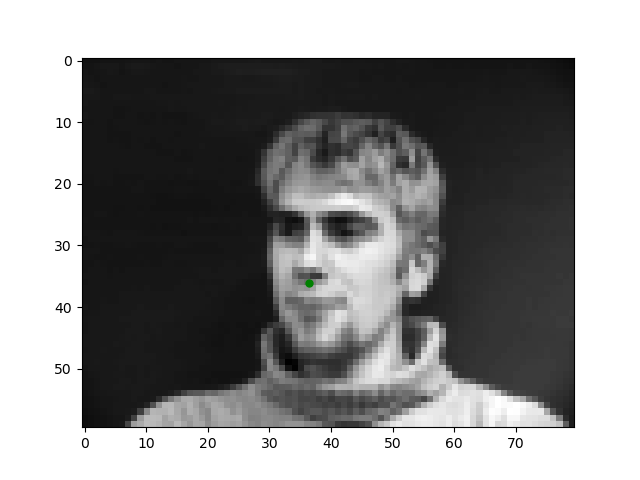
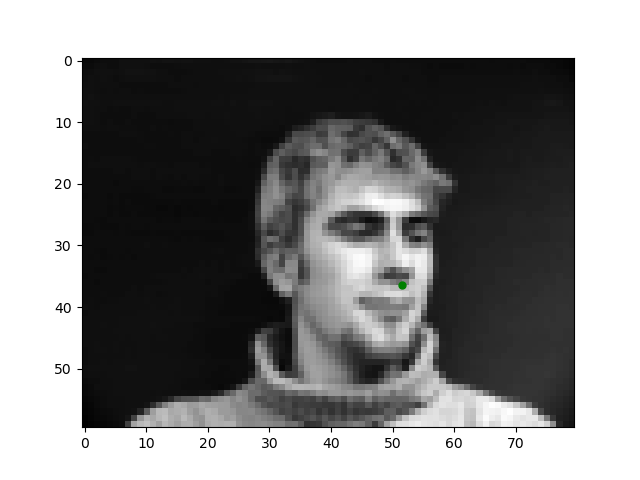
To solve this task, I trained a simple 4-layer CNN Model with 3 max-pooling layers and two feedforward layers all with ReLU activation. The model looks like as follows:
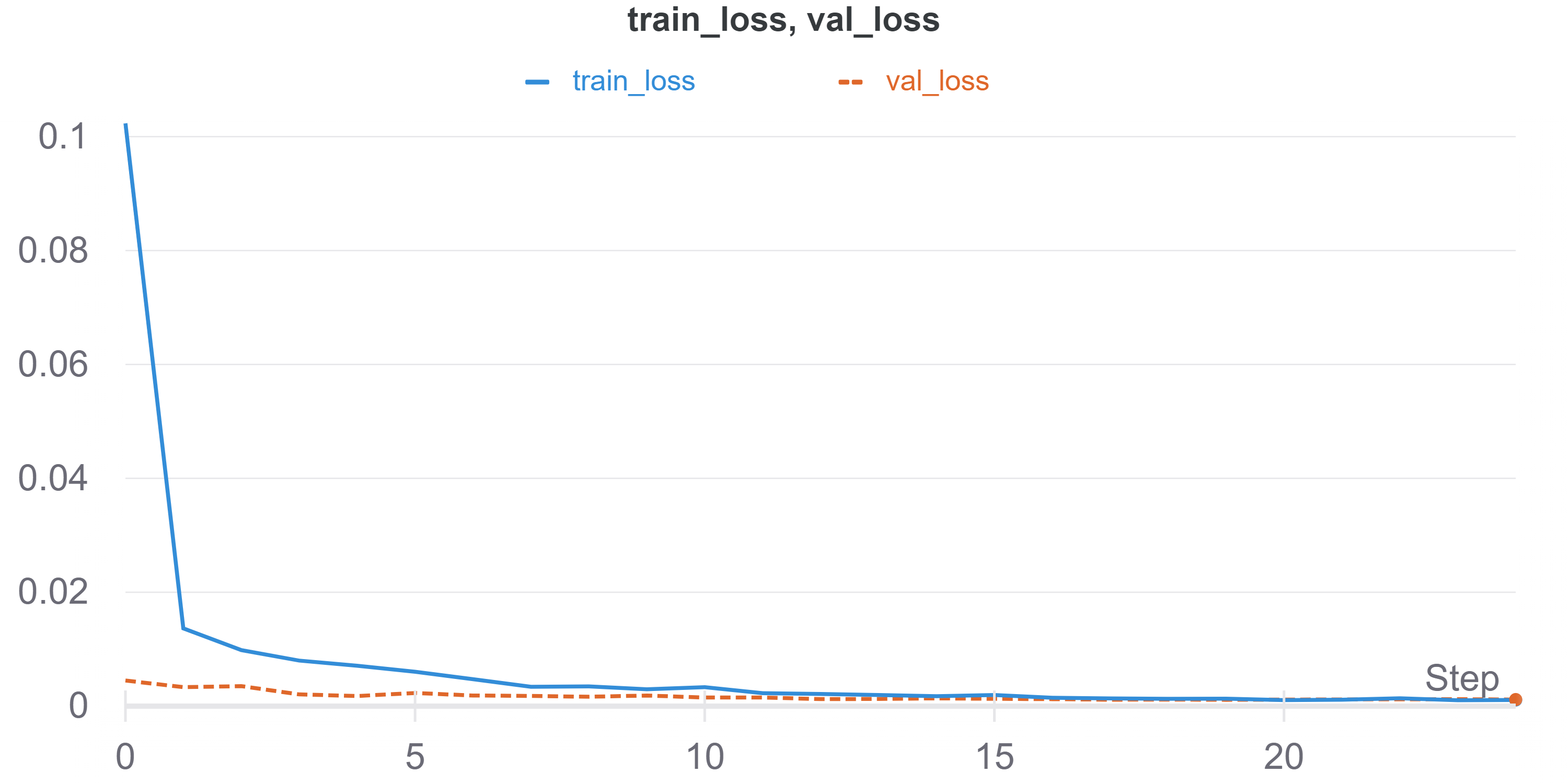
The model is trained for 25 epochs using a learning rate of 1e-4 and the Adam Optimizer on cpu with a batch size of 2. I got the following training and validation loss:
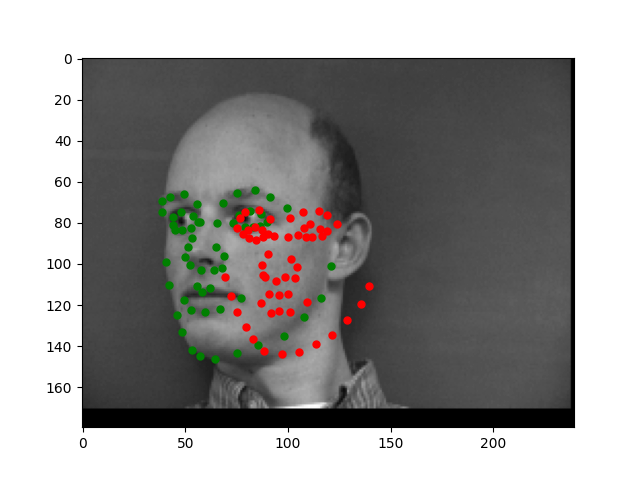
Let's take a look at some results where the model does well and poorly. The red is the model prediction and the green is the ground truth.
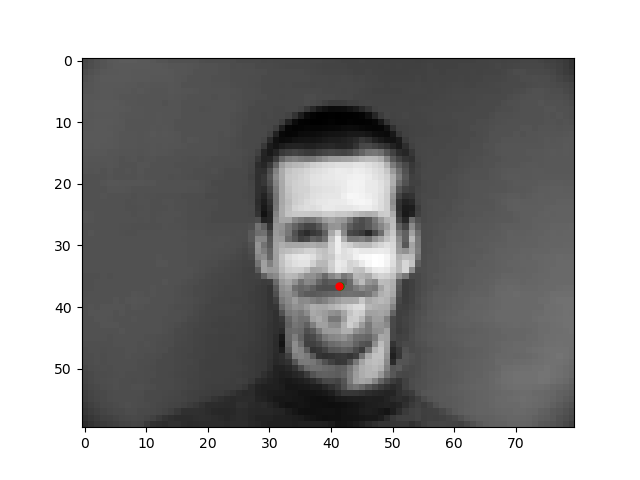
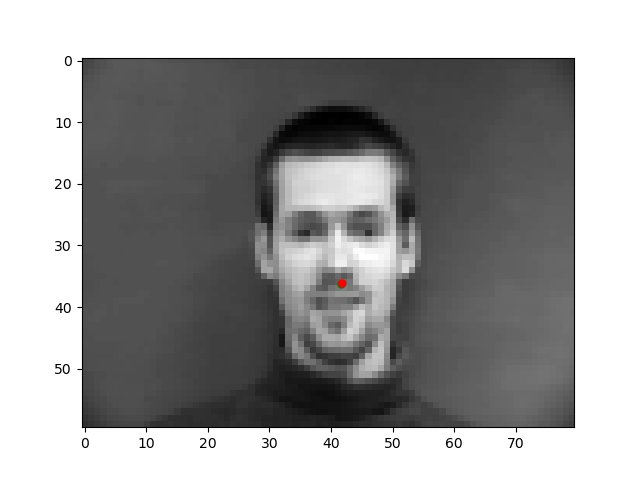
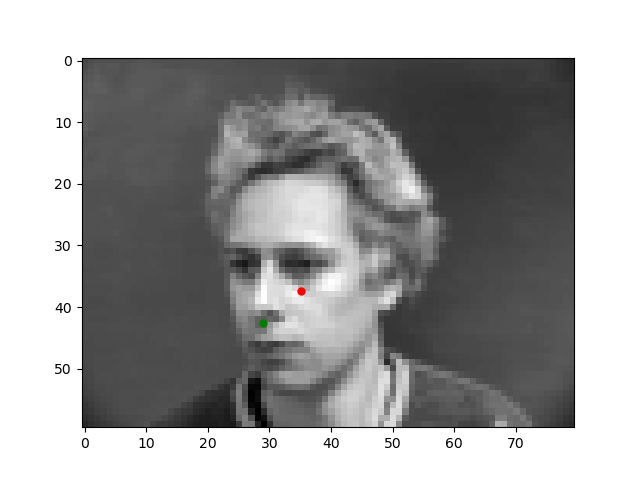
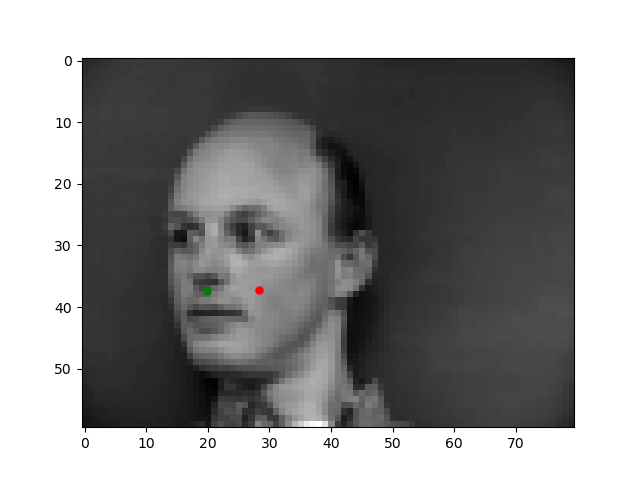
These are from the validation set so the model hasn't seen them before, yet, for these first two images, it is almost exact. However, the model is not perfect as seen from these later two images. The angel of the face might be too confusing for the model, which is why the prediction is so off.
Lastly, let's see how this model does with various different hyperparameters. I experimented with the size of the hidden layer in the feedforward network and the learning rate to see how model performance changes. These are the results I got:
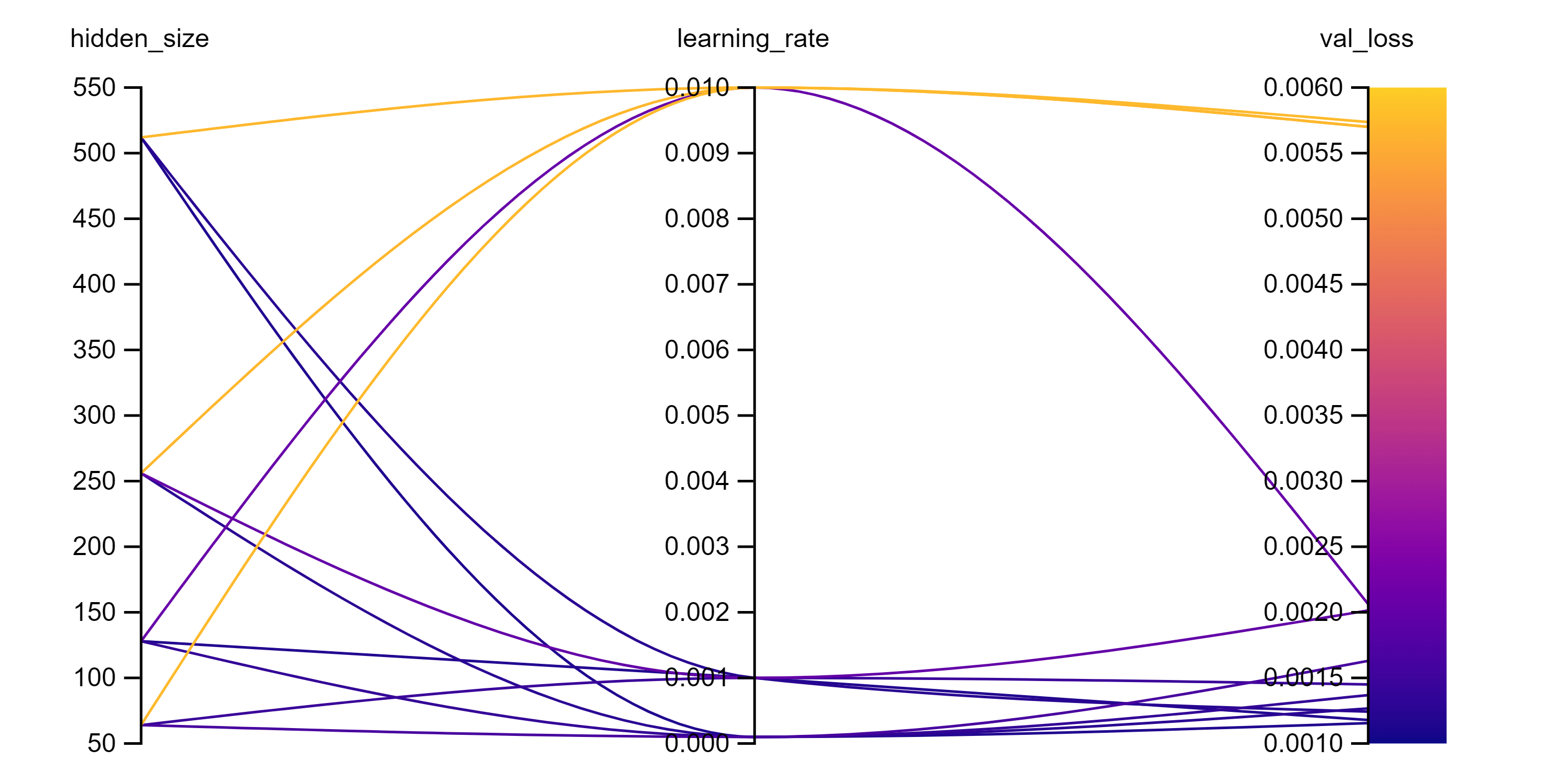
What we see here is that having a hidden size of 512 and a learning rate of 0.0001 produces the best validation loss. Overall, the major pattern is that using a high learning rate of 0.01 is bad unless you have a hidden size of 128, which was probably a result of luck. Generally, we are better off with keeping the learning rate low to improve model stability, which benefits the fact I used a small batch size of 2.
Full Facial Keypoints Detection
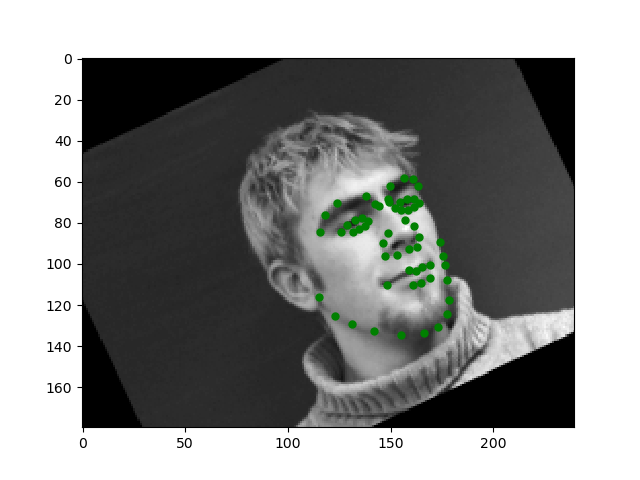
Now that we have designed a model capable of predicting the nose tip, let's scale it to learn how to predict a full set of facial keypoints. The model is more or less the same as in the previous part except it has more layers and channels to help it learn the various unique features relevant to the different keypoints. However, our dataset for this task is rather smaller for the difficulty. Training the model on just the given set of images won't be enough to help it learn how to robustly predict keypoints on images outside of this distribution of faces as it will likely overfit. To overcome this challenge, I implemented a data augmentation strategy that probabilistically change small parts of the image to prevent the model from being able to memorize the inputs. For data augmentation, I implemented function to randomly shift, rotate, and add noise to the image. This enables the training set to grow infinitly. Let's take a look at some samples of this augmented dataset.

For this task, I train a slightly bigger version of the CNN model I described previously now with 5 conv layers and 4 maxpool layers with the same final hidden layer structure also with ReLU activation. The overall model looks like as follows:
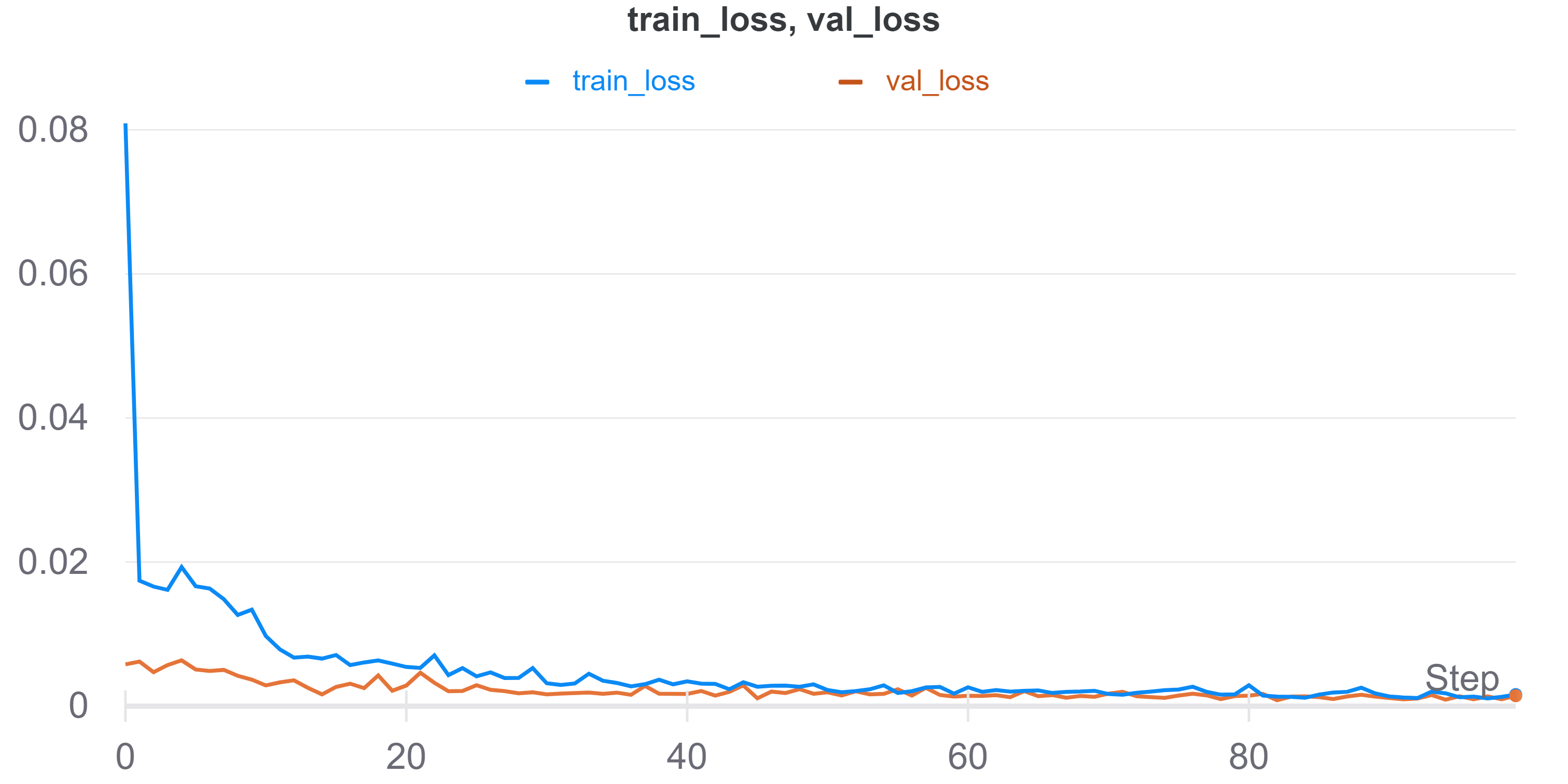
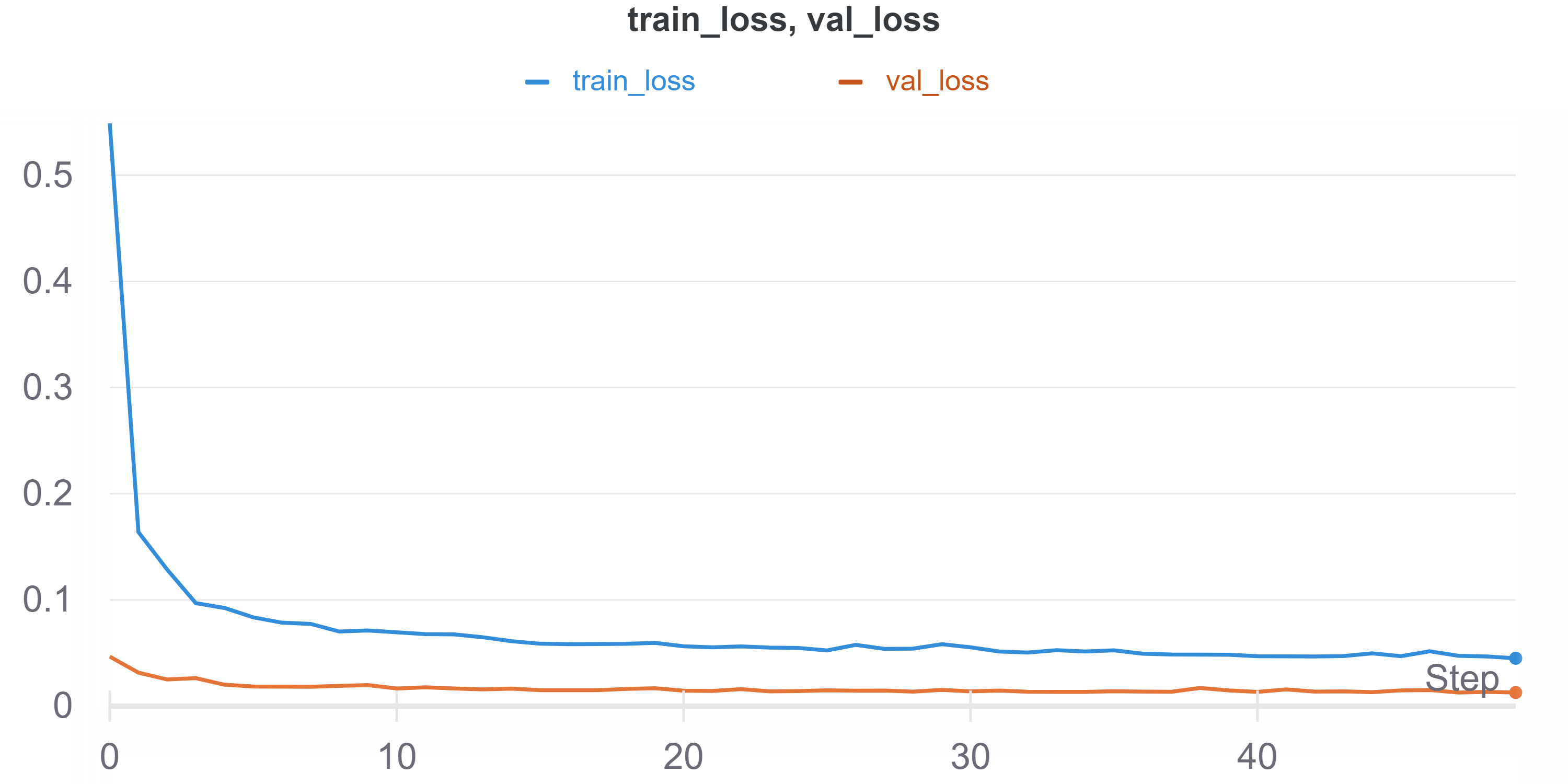
I trained this model for 100 epochs with a learning rate of 1e-3 using the Adam Optimizer and a batch size of 2 on an NVIDIA Titan RTX. Here is the training and validation loss I got.
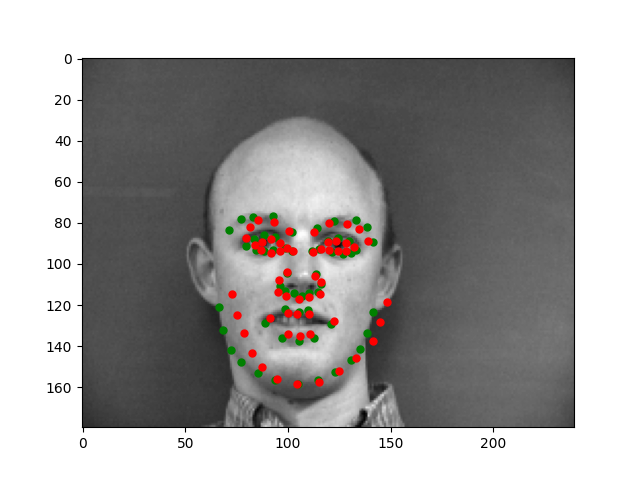
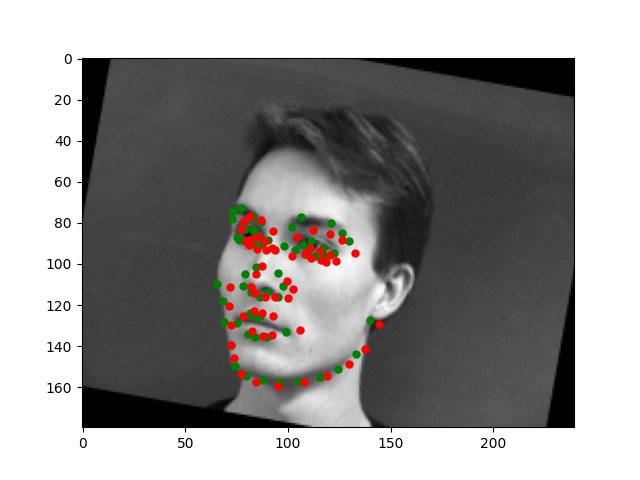
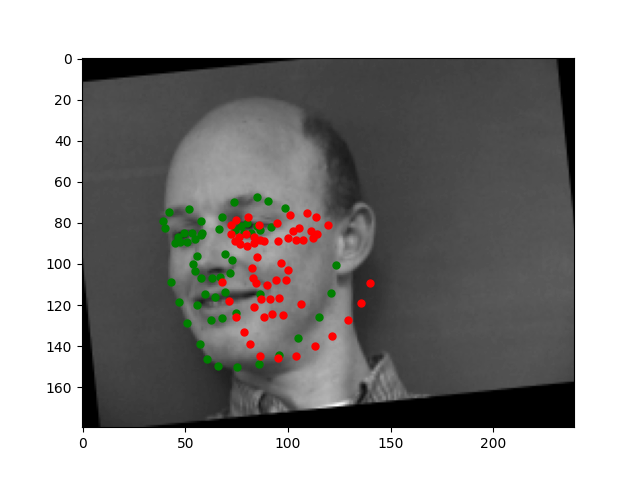
The model is still not great at predicting faces that are turned a lot. It has this tendency to predict points that are near the center of the image. However, overall, the model is doing pretty well.
Let's peek into how the model is making these predictions by visualizing the filters it learned while training. These are the filters used in the first conv layer:
There is sadly not much to see from these visualizations, but it does work well :)
Train With Larger Dataset
For the last part of this project, I explored using a larger dataset to develop an even better model for this task. However, instead of training a model from scratch I instead finetuned a pretrained Resnet-18 model with some tweaks. I am pretty happy with my model's performance. In the Kaggle competition, I got a score 7.76365 placing me at 8th place at the time of this writing.
My model extends from the Resnet-18 model, however, I made a few modifications that would better suit the model to this task. First, I added a Conv layer at the beginning to process the grayscale images and convert them into 3 channel images. I also changed the final layer of Resnet to be a maxpool layer instead of average pool since it is more useful to discriminate between relevant and irrelevant points. I then added 2 feedforward layers similar to the ConvNets above to do the point regression. Lastly, I also added self-attention layers before layers 3 and 4 in the resnet model. My intent here was that the attention mechanism would help the model learn a particular structuring of the points around the face to make regression easier. It definitely added a performance boost.
I trained this model for 50 epochs with a batch size of 64 and a learning rate of 0.001. I also instead optimized the L1 loss instead of MSE, which helped improve performance. Here is the training and validation loss which shows the model does do well.
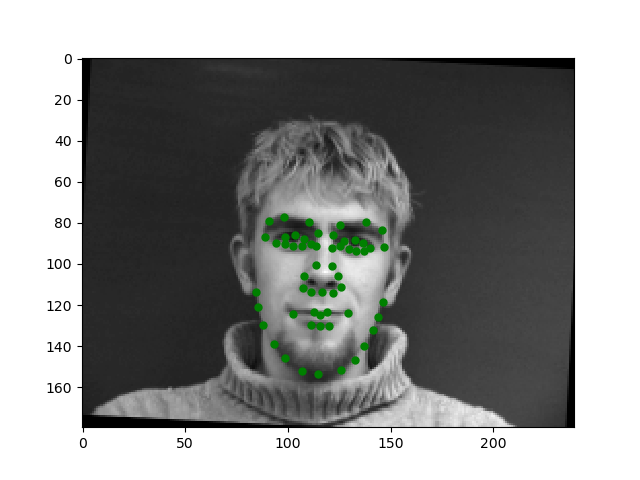
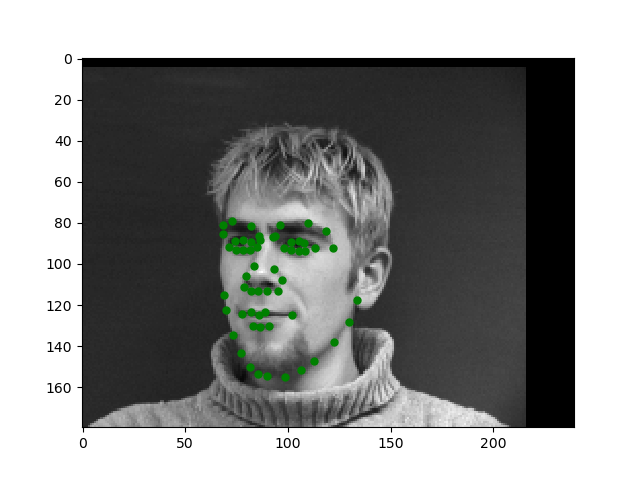
Let's look at some of the outputs on the test set. They look really good to me.

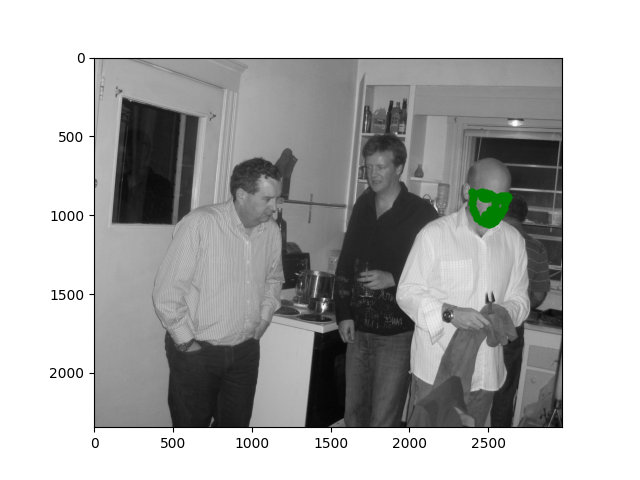
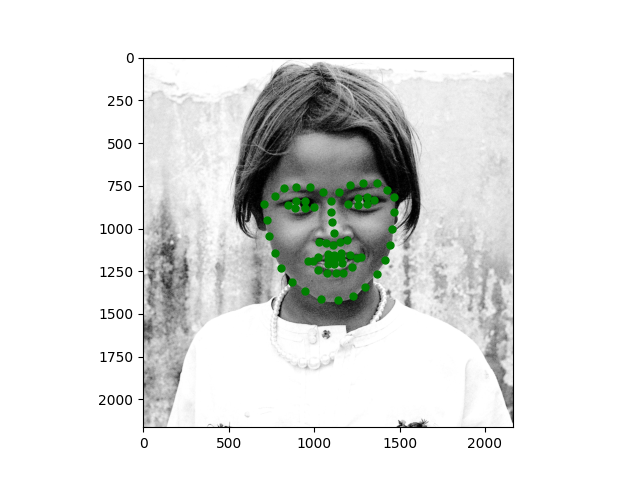
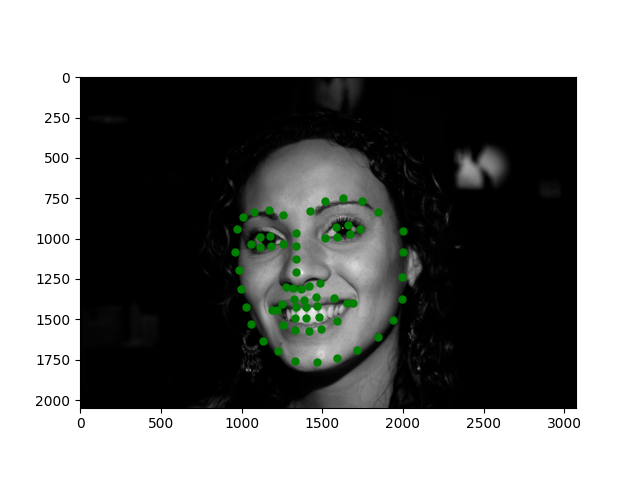

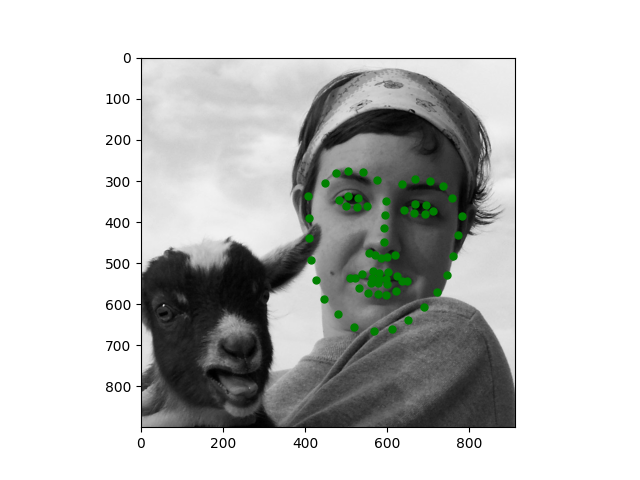
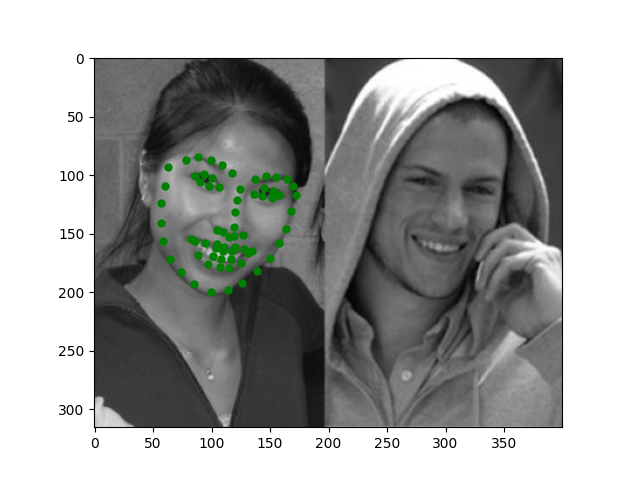
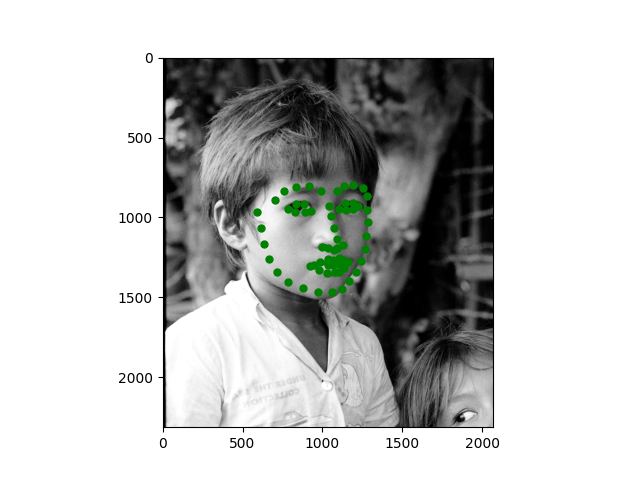
I also tested the model on some of my own images and it looks decent (even on the turned head)!


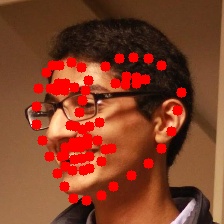
Auto Face Morphing
Now that we have a model that can automatically detect keypoints, we can use it for automatically morphing faces, check it out!

Morph