


The primary goal of this project is to explore how we can learn to annotate faces with keypoints, first just the nose and later 68 points across the entire face via neural networks. This project heavily involves the use of various neural network components, especially convolutional layers, which we use extensively to detect these keypoints.
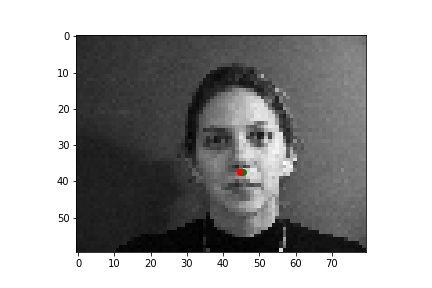
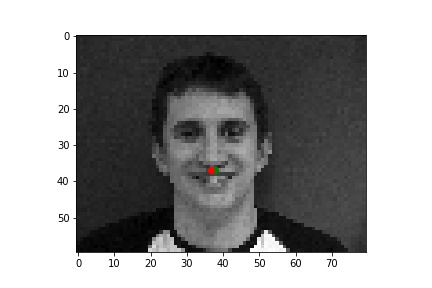
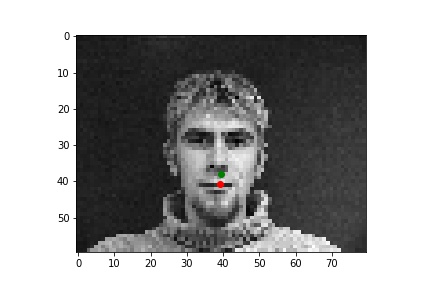
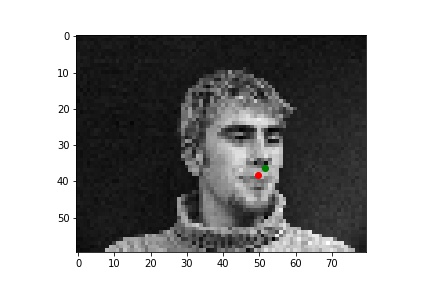
Although it is difficult for me to reason why the latter two faces result in relatively poor predicitons, one possible explanation could be the contrast values. The poor performing predictions were both on the same person, who has a noticable higher contrast than the other two individuals. This difference in lighting and thus pixel values could very easily have contributed to the difference in performance across the faces.
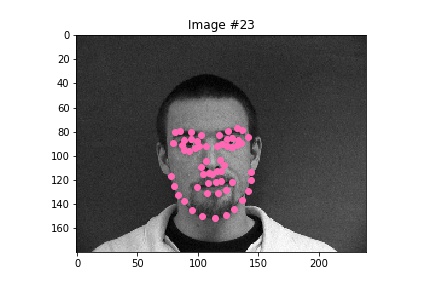
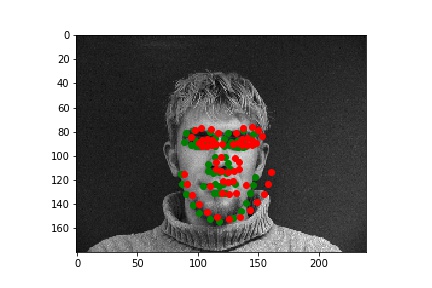
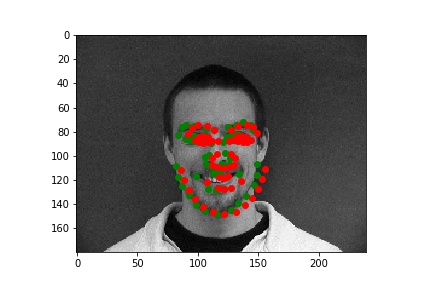
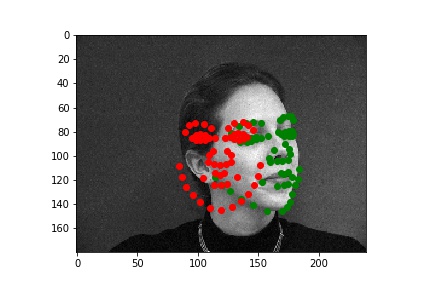
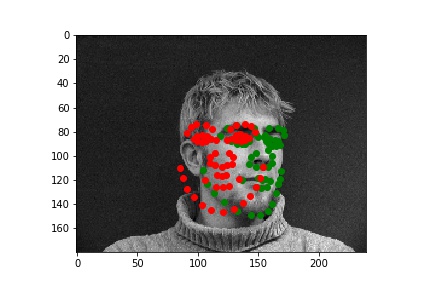
From these examples seen here, one obvious conclusion is that my model was not able to properly handle faces that are not in perfect alignment and proportion, which in this case resulted from faces looking to the side. I'm sure that this changed the perspective/geometry of the face, which must've affected the network's ability to detect features within the face and predict keypoints.
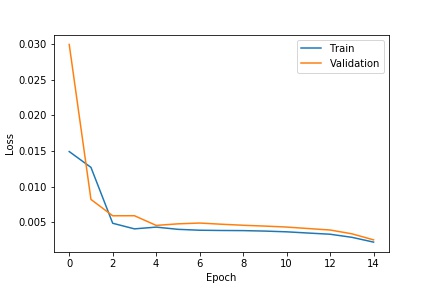
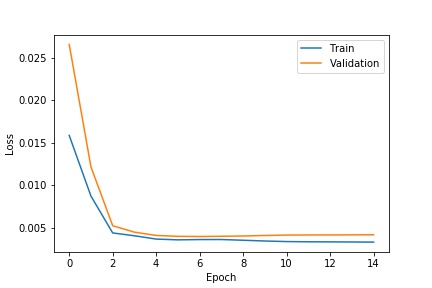
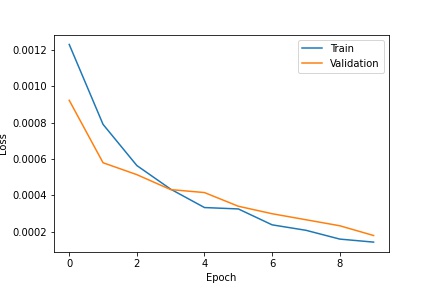
the model that I used for this task was the provided RESNET18 model, with the first convolutional layer changed to take in a 1 dimensional input since the image is now in black and white instead of color (with 3 channels), and the last fully connected layer to output a 136 dimensional vector to represent the 68 coordinate pair outputs for the detected facial keypoints. With all model parameters kept the same as the default, I chose to train over 10 epochs with a batch size of 16 and a learning rate of 0.001.
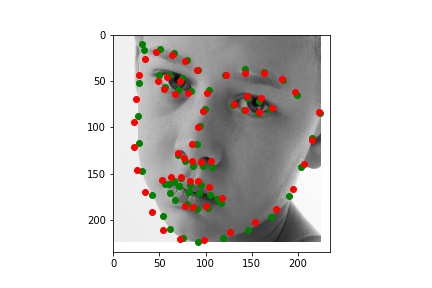
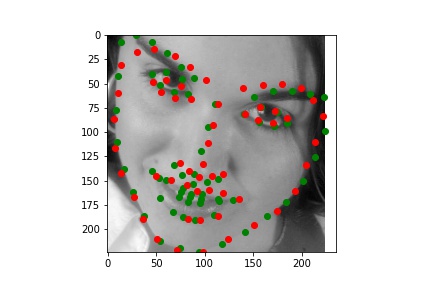
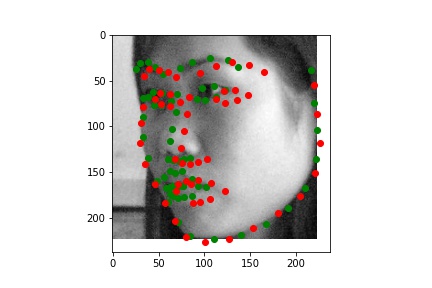
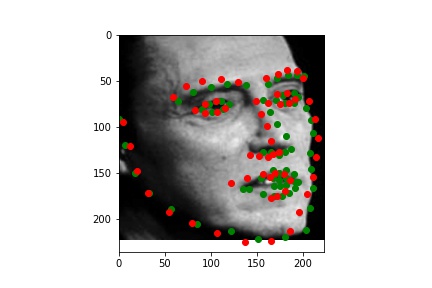



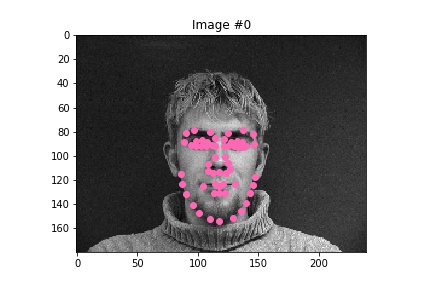
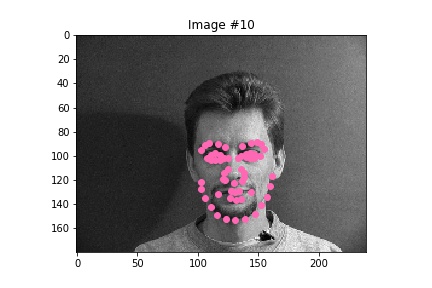
After exploring results across many images from the training dataset, it seems that the model performs relatively well on most images, as represented by images 1, 2, and 4. However, there are some images, such as image 3 here, that have poorly predicted keypoints that could be explained by the lighting effects. Looking at image 3, due to the nature of the pose half of the subject's face is in shadow, which could be the cause of the slightly misplaced keypoint predictions.