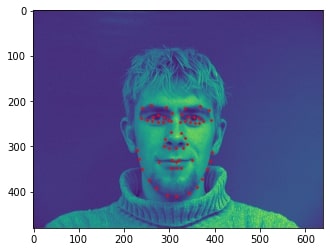
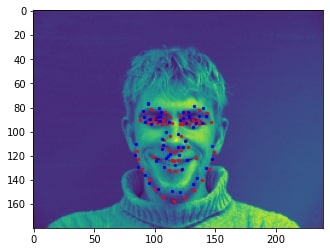
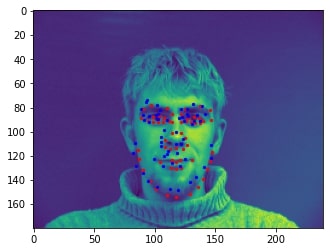
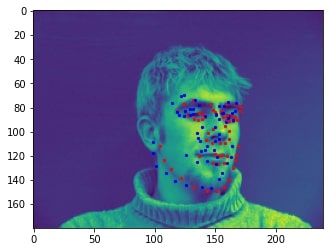
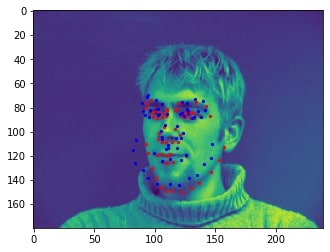
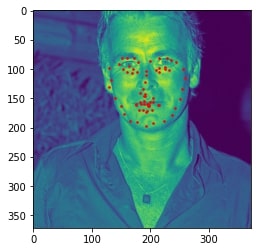
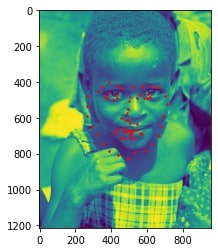
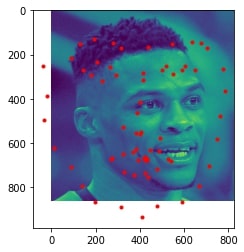
Sampled image from dataloader visualized with ground-truth keypoints:
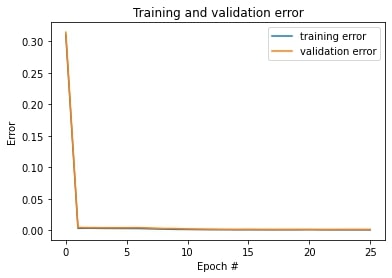
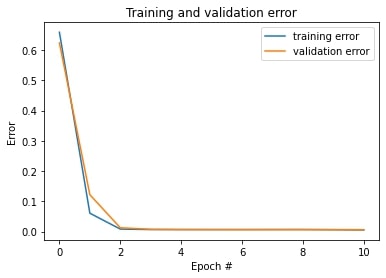
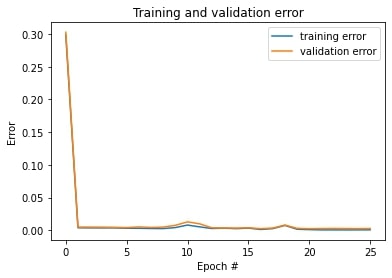
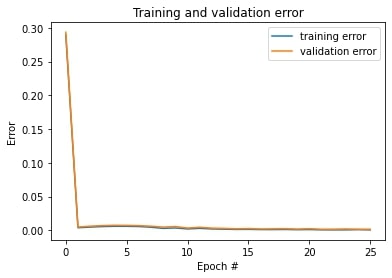
Plot the train and validation MSE loss during the training process:
On the left, the model has learning rate of 0.005 and different number of channels across convolutional layers.
On the right, the model has learning rate of 0.001 and same number of channels across convolutional layers.
They have similar performance.
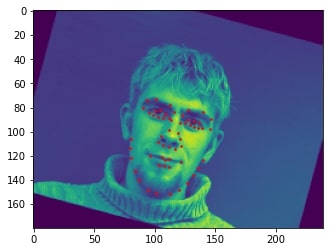
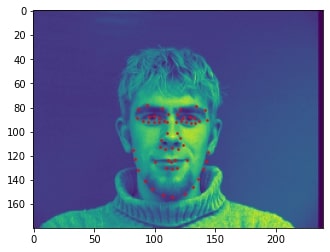
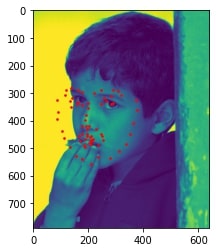
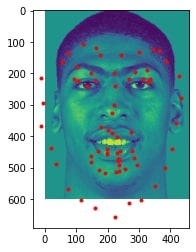
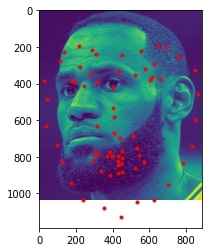
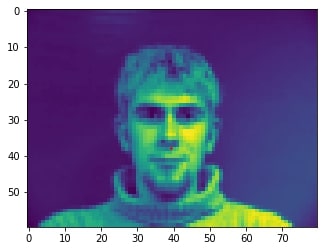
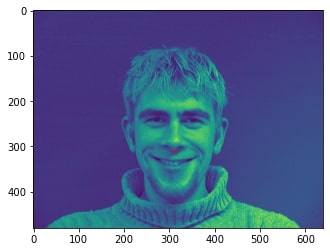
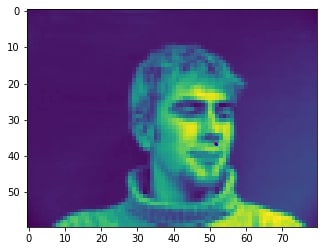
2 facial images which the network detects the nose correctly:
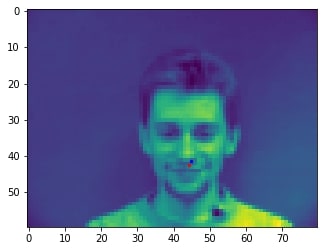
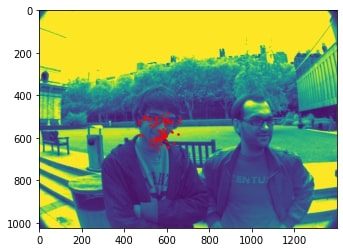
2 facial images which the network detects the nose incorrectly:
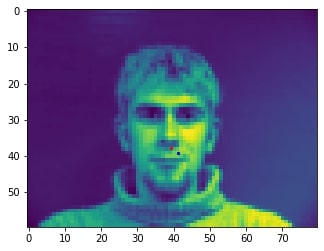
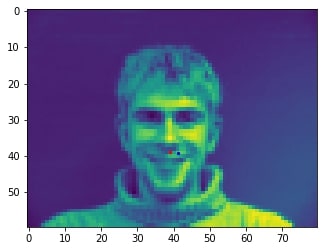
In the two images where the network detects the nose incorrectly, the prediction is still pretty close to the actual result. The difference might come from the fact that the model needs further training to improve accuracy.