CS 194-26: Project 5 - Facial Keypoint Detection with Neural Networks
By Prangan Tooteja
Nose Tip Detection
The goal of this task was to detect a person's nose-tip. To do this we created a dataloader and downsized the input images to 160x120. Below are some sampled images with the ground truth nose keypoint displayed in red.

|

|

|
The next step is to train our neural network to predict these points. I used a shallow network with 3 convolutional layers followed by 2 linear layers.
Here are my best results which achieved a validation accuracy of 85% where an accurate prediction is a prediction with distance 1 less than the ground truth keypoint. I used a learning rate of 0.001
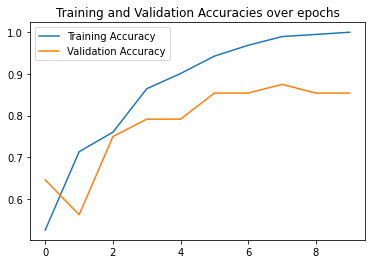
|
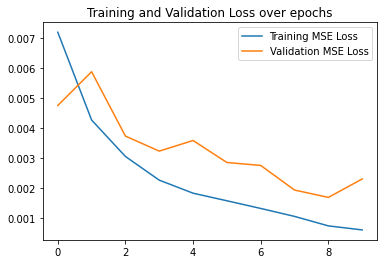
|
Below are images where the model predicted the nose keypoint correctly and where it predicted it incorrectly. I think the model performed poorly on the incorrect images because it looked for shiny spots as an indicator of the nose tip.

|

|

|

|
Here are my second best results which achieved a validation accuracy of 60% where an accurate prediction is a prediction with distance 1 less than the ground truth keypoint. I used a learning rate of 0.01. As can be seen in the MSE plot, the model converged to a local optimum fairly quickly and was not able to find other optima.
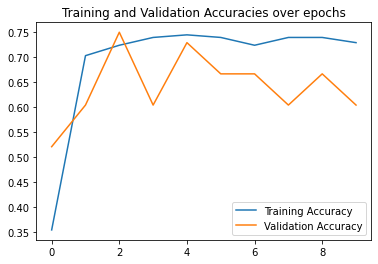
|
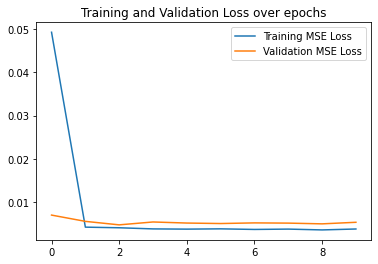
|
Below are images where the model predicted the nose keypoint correctly and where it predicted it incorrectly. I think the model performed poorly on the incorrect images because it overfit to the training set and predicted the mean point each time.

|

|

|

|
Here are my third best results which achieved a validation accuracy of 80% where an accurate prediction is a prediction with distance 1 less than the ground truth keypoint.
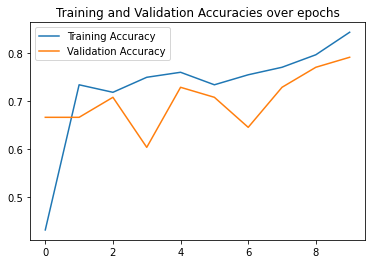
|
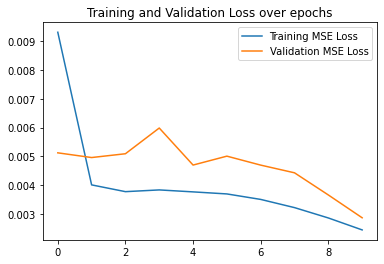
|
Below are images where the model predicted the nose keypoint correctly and where it predicted it incorrectly. I think the model performed poorly on the incorrect images because of differences in contrast to the typical training example

|

|

|

|
Full Facial Keypoints Detection
Building off of the previous task - this part tried to predict all of the keypoints for a given image. Similarly, we created a dataloader and downsized the input images. However, a problem I found in the previous part was that the model would sometimes overfit the training data predict the average nose-tip. To reduce the likelihood of this, we randomly transformed the image so that the model would effectively get to see a new image every time. Below are some of the sampled images with the ground truth keypoints overlaid on top of it.

|

|

|
The next step is to train our neural network to predict these points. I used a deeper network than the previous part increasing the number of convolutional layers to 6 followed by 2 linear layers. I also increased the number of epochs I trained for to 20 and changed my batch_size to 20 as well.
Here are my best results which achieved a validation accuracy of 77% where an accurate prediction is a prediction with distance 1 less than the ground truth keypoint, I have also included my detailed architecture

|
|
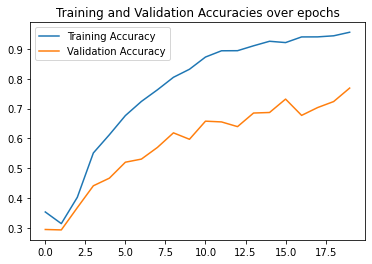
|
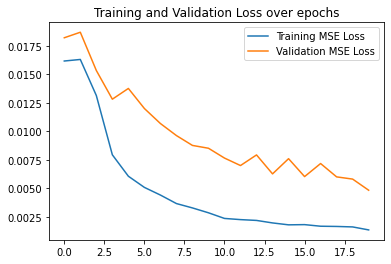
|
Below are images where the model predicted the nose keypoint correctly and where it predicted it incorrectly. I think the model performed poorly on the incorrect images because of significant deviations from the average training point. There were not too many women in the training set and not many flipped images.
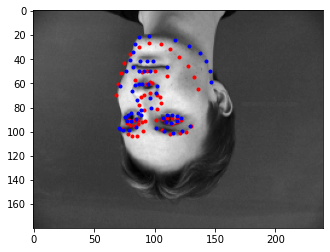
|

|

|
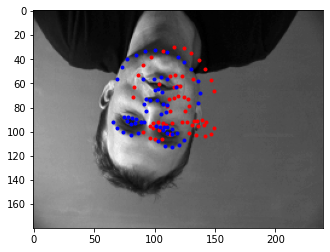
|
Below I have included the filters for the first convolutional layer.
Below I have visualized the 12 3x3 filters created by the first convolutional layer of my model.
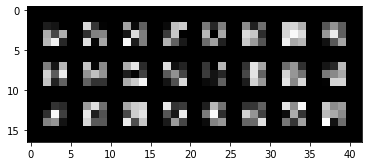
|
Train With Larger Dataset
Building off of the previous task - this part uses a larger and more diverse dataset for keypoint detection. As in the previous task, we created a dataloader and downsized the input images as well as randomly transforming the image so that the model can better learn how to handle noisy data. Below are some of the sampled images with the ground truth keypoints overlaid on top of it.

|
The next step is to train a neural network to predict these points. As suggested in Piazza and the spec, I used Pytorch's ResNet18 implementation and modified the first convolutional layer and the last linear layer to accept input from our dataset and return the correct number of keypoints. Here are my first and last layers. model.conv1 = nn.Conv2d(1, 64, 7, stride=2, padding=3, bias=False) model.fc = nn.Linear(512, 136) I used a learning rate of 1e-3 and an Adam optimizer. I trained with a batch_size of 100 for 20 epochs.
Here are my results which achieved an MSE Loss of 21.5566 on Kaggle my team name is Prangan Tooteja.
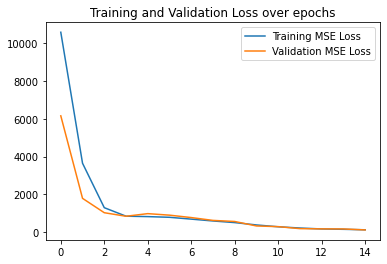
|

|

|
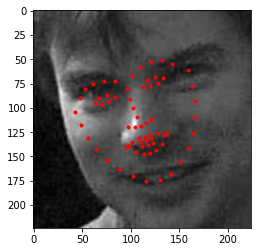
|

|
Below are images from my own collection. The model performed fairly well when identifying the images and works best when the image is not blurry or is facing the front. Darker images are not handled well as well as images which have more background in them.

|

|

|

|
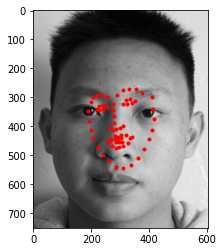
|
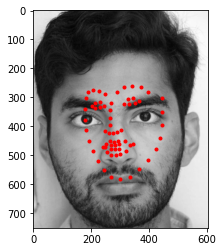
|