Han Cui, SID: 3033631995
Email: louiscuihan2018@berkeley.edu
Part 1: Nose Tip Detection
I use the Pytorch dataset and Pytorch dataloader classes to create my own dataset and dataloader for the IMM dataset. I manually split all data into a training set of 192 images and a validation set of 48 images based on indexes. Besides these, all images are normalized to the range of (-0.5, 0.5) and resized into the shape of (80, 60). Below are some examples of preprocessed images along with target points.
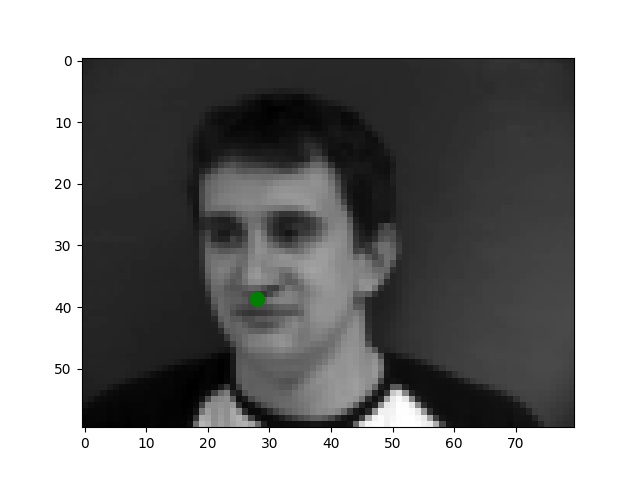
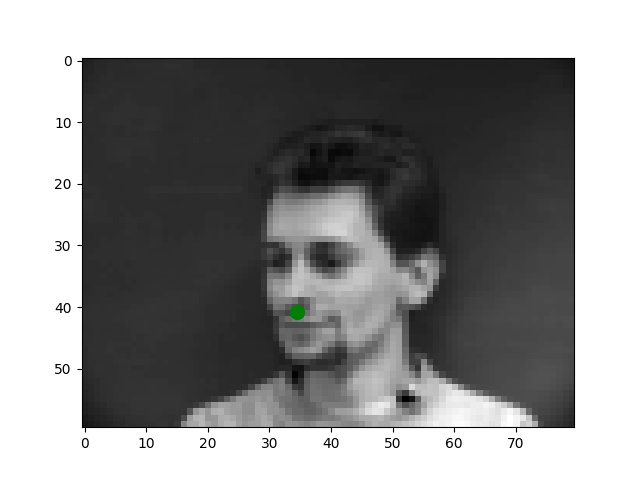
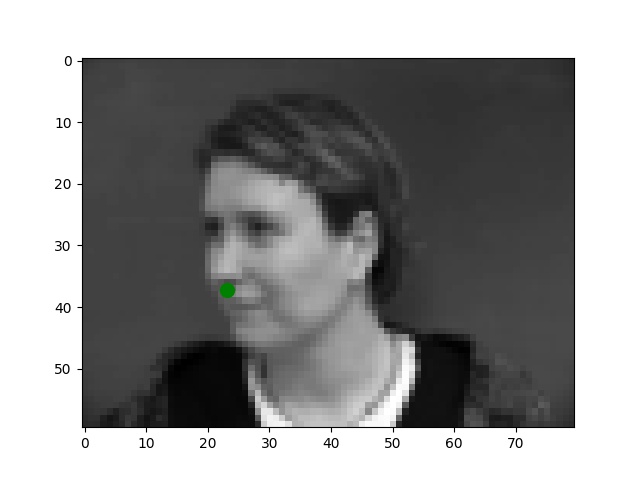
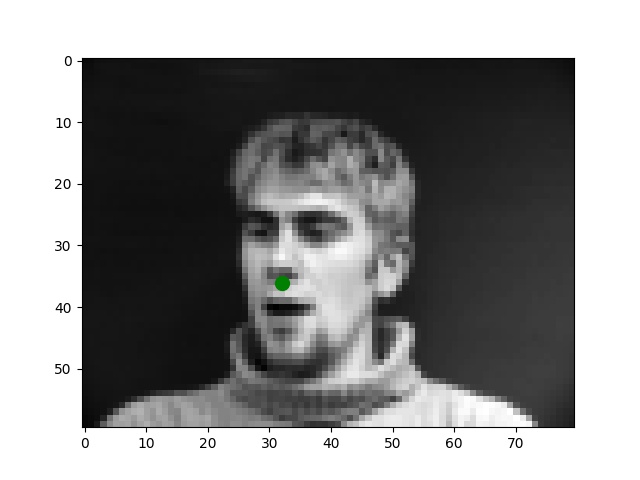
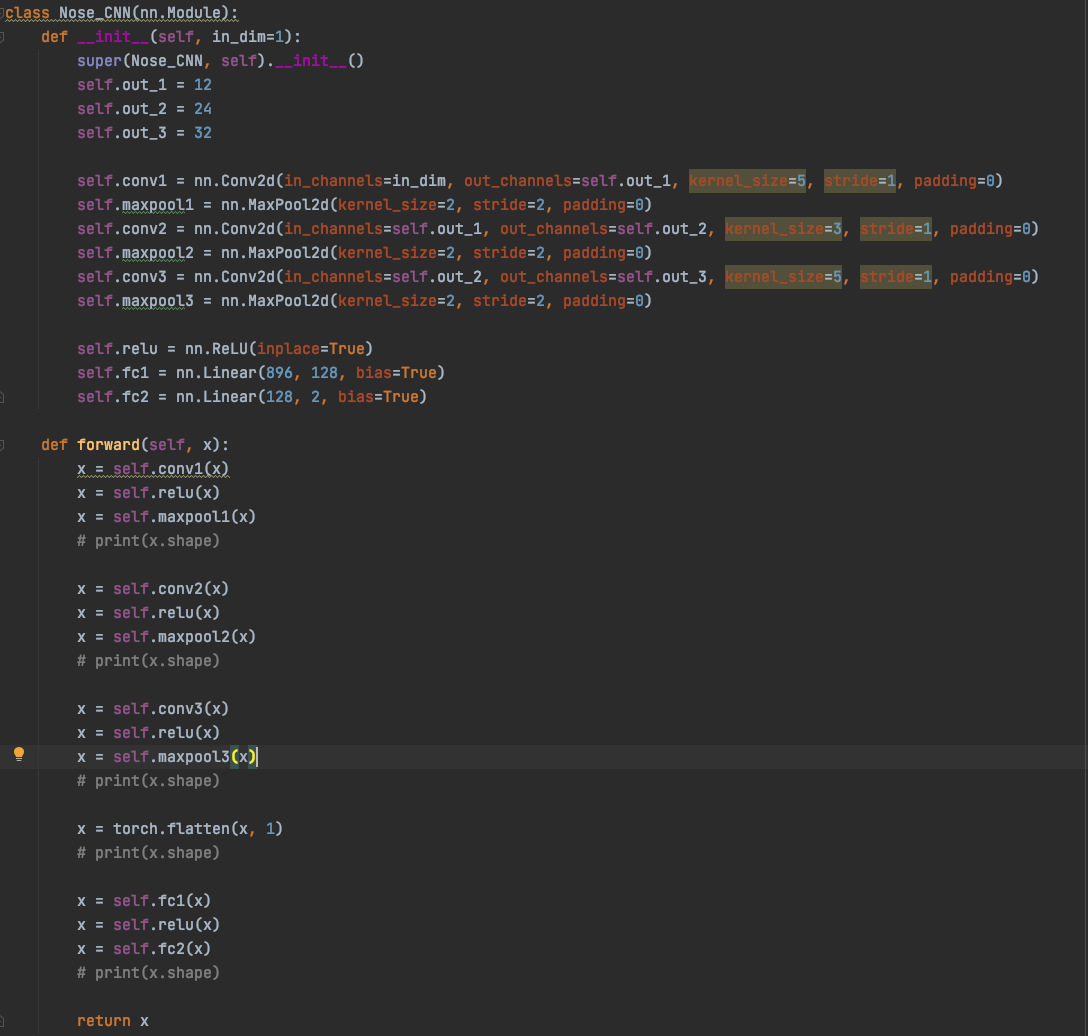
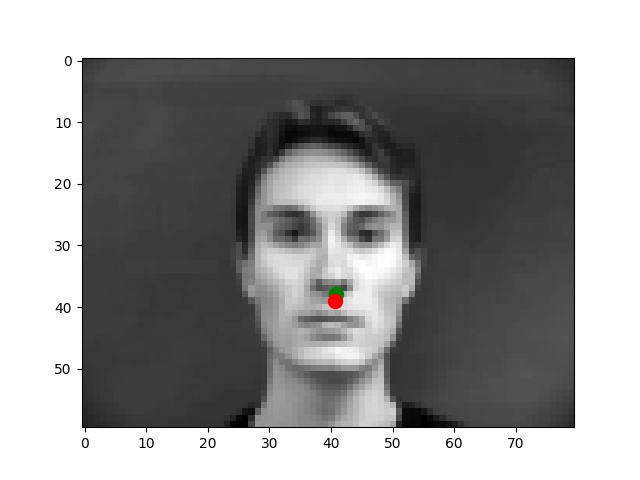
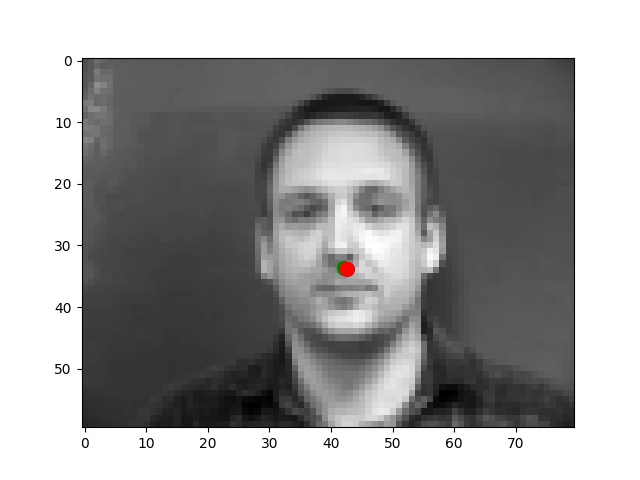
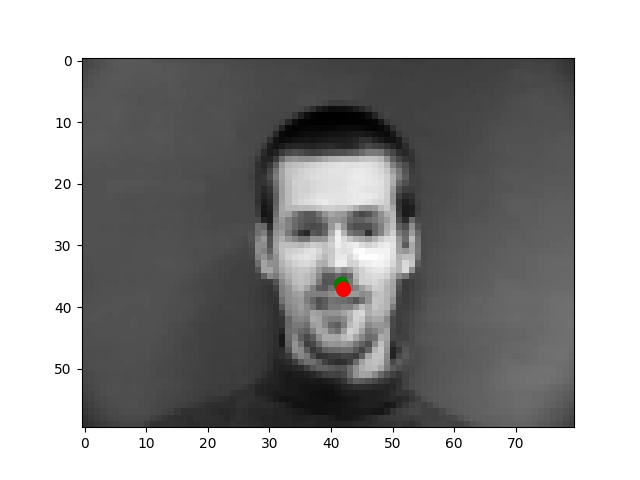
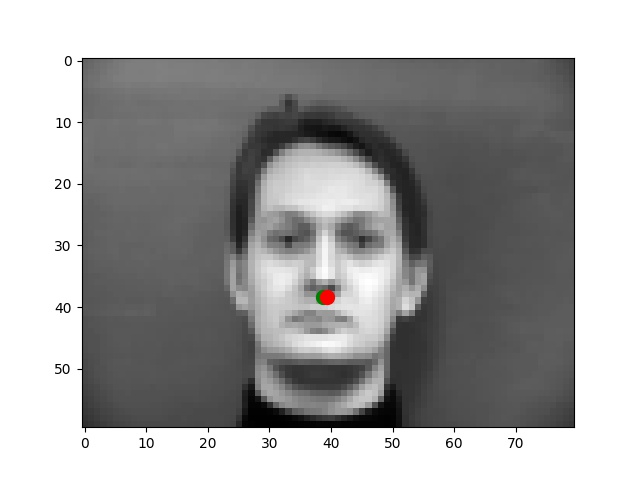
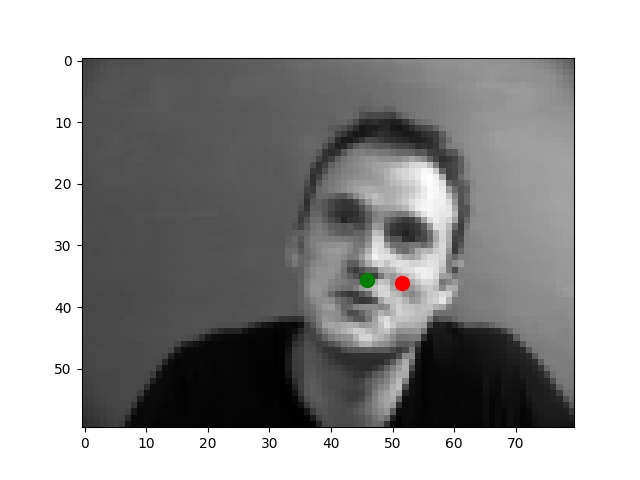
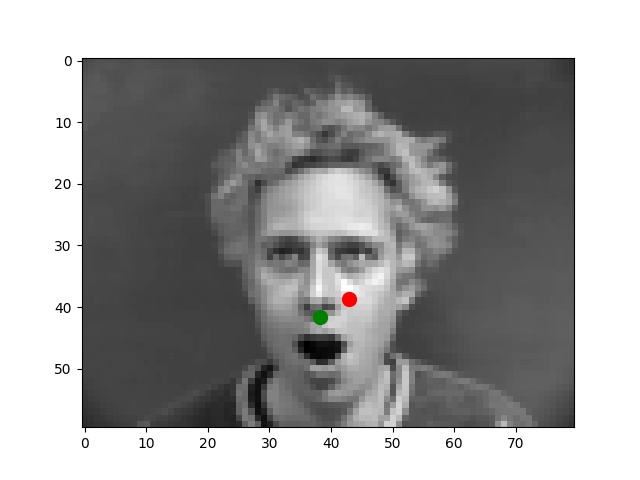
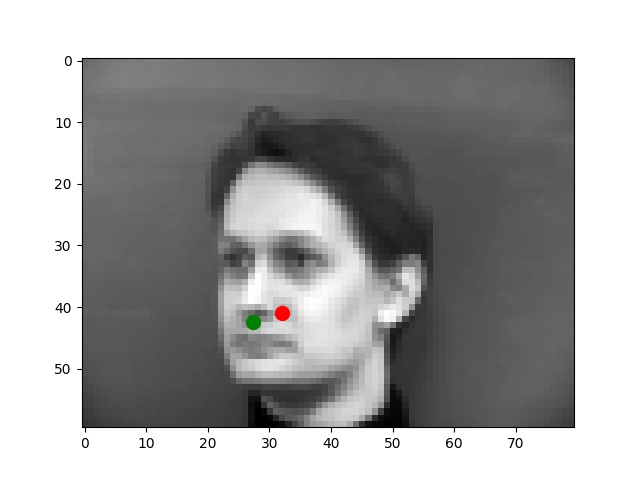
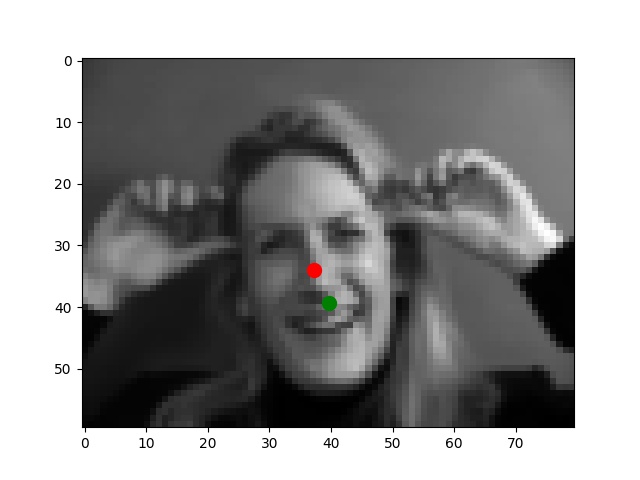
From my observations, most correct predictions are on examples like passport-style images. Once the face's angle, expression, location change, the neural network fails to precise the nose tip. The main reason should be somehow related to the model capacity and dataset information: the model is too shallow to deal with variations like different angles. The training dataset is too small to provide enough information for the model to become robust.
Part 2: Full Facial Keypoints Detection
For this part, I use similar Pytorch dataset and dataloader classes. Also, all the images are normalized into the range of (-0.5, 0.5) and appropriate resize. In this part, I also write data argumentations for randomly adjusting brightness and saturation, random rotation between -15 to 15 degrees, and random shift between -10 to 10 pixels. These argumentations also apply to the ground truth points. Here are some examples of the training images and ground truth feature points.
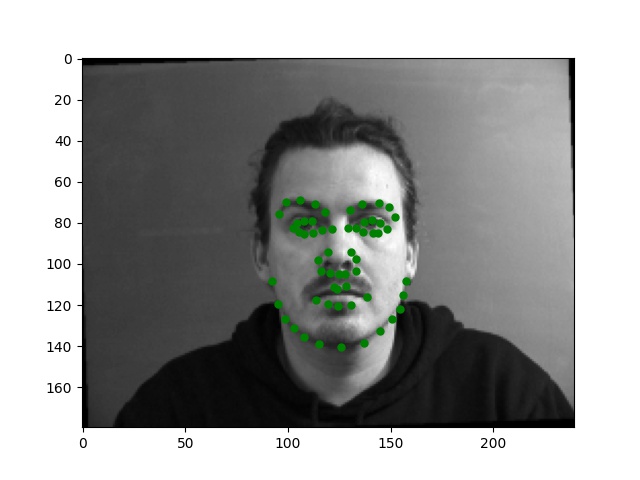
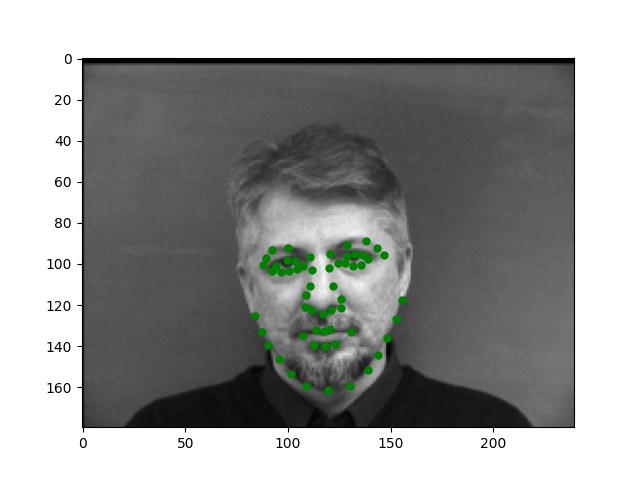
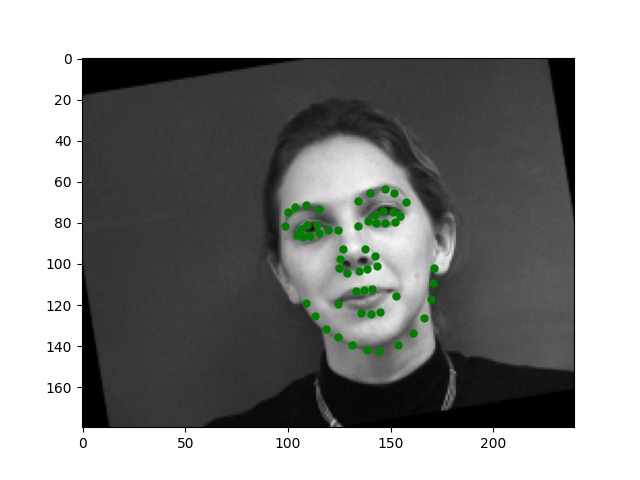
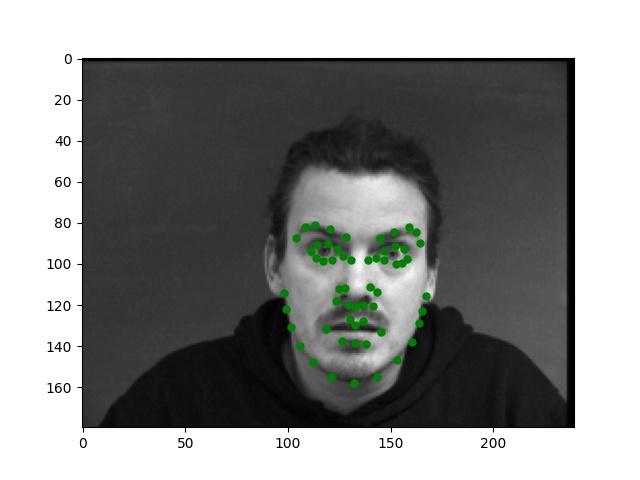
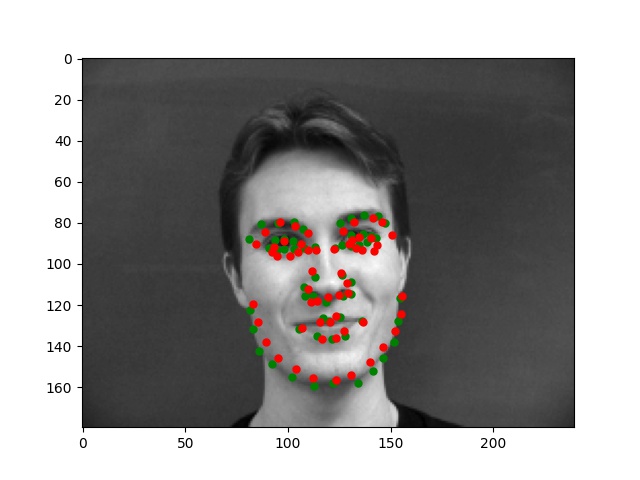
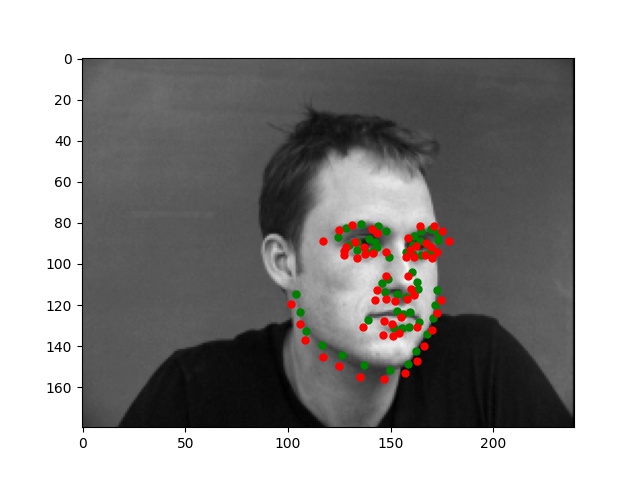
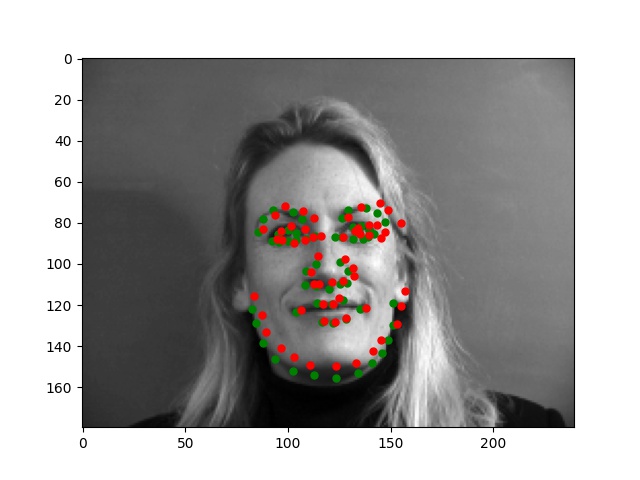
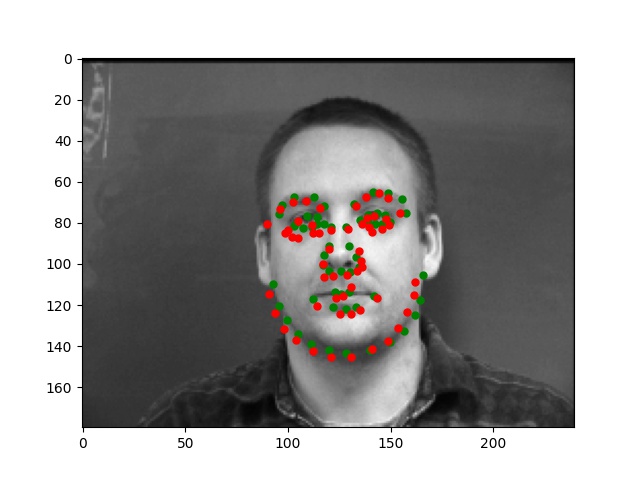
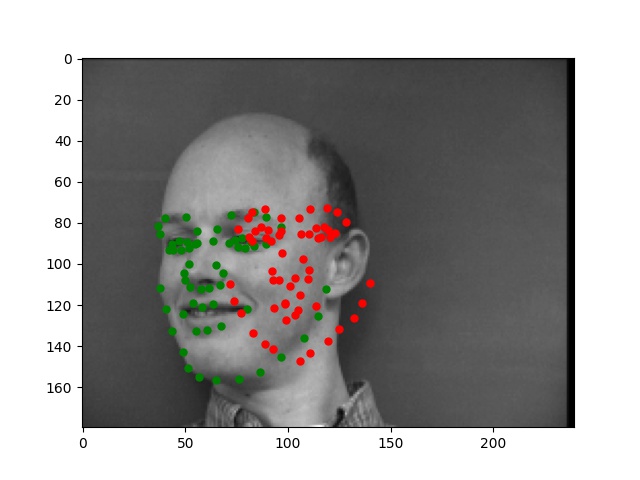
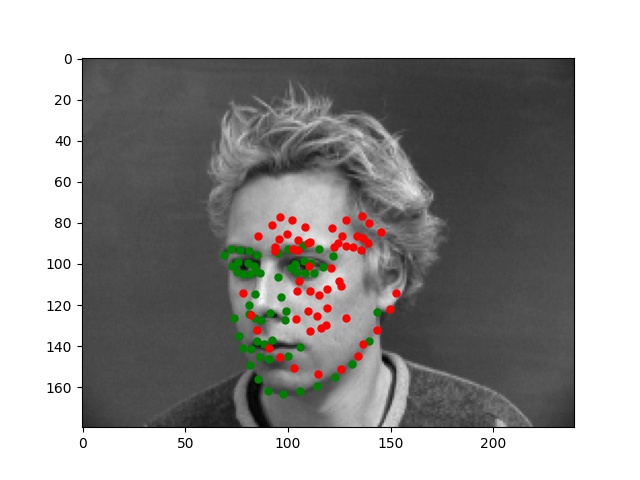
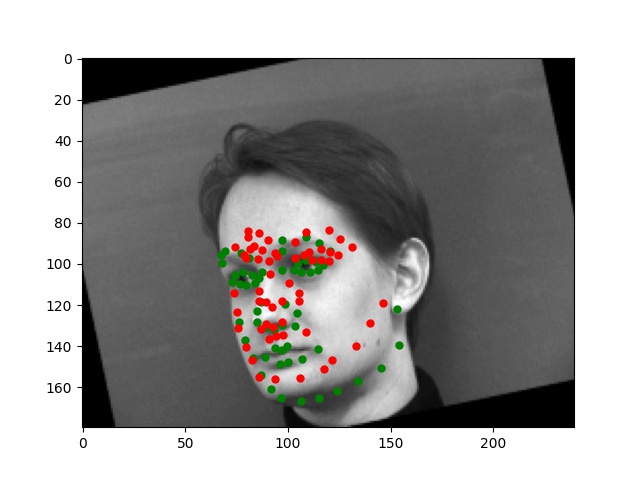
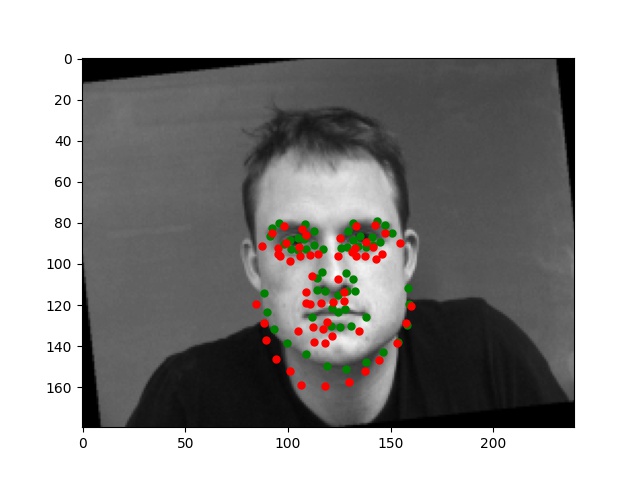
Again, for images with passport style, the network performs pretty well. However, if the images are, for example, hugely rotated or facing towards sides, the network fails to be precise. This, as I suspect, is still involved in the model capacity and dataset capacity. The dataset doesn't include enough examples for the network to generalize to different variated images, or the model is still too simple to do so.
Here, I also want to visualize some filters from different convolution layers.
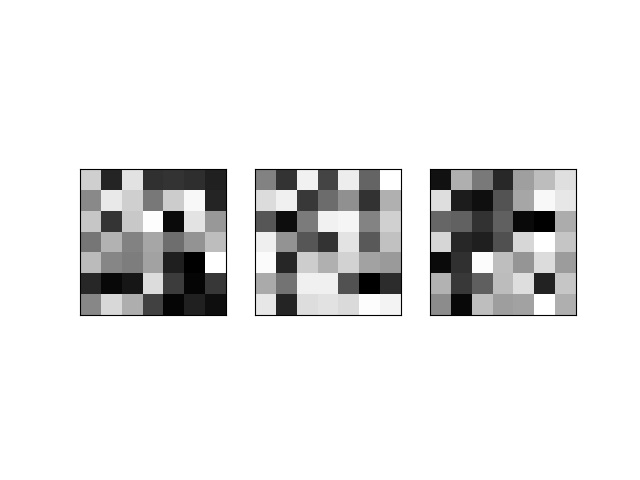
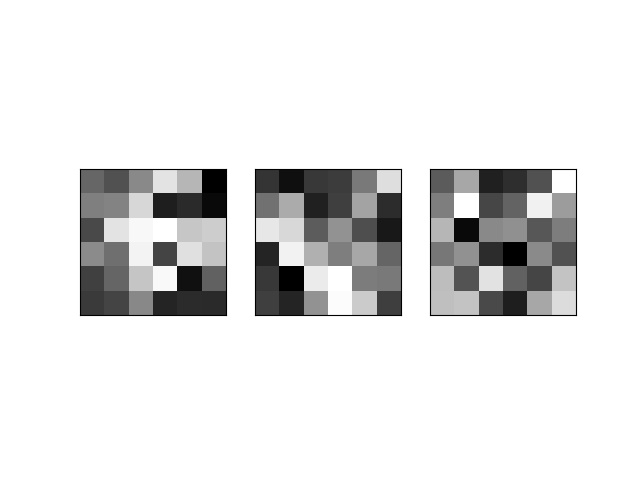
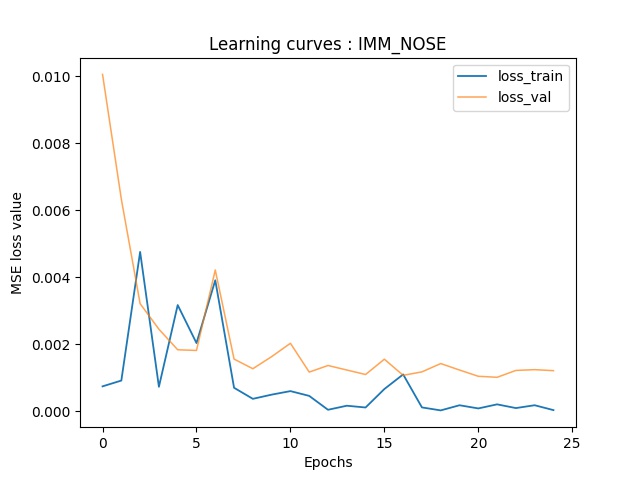
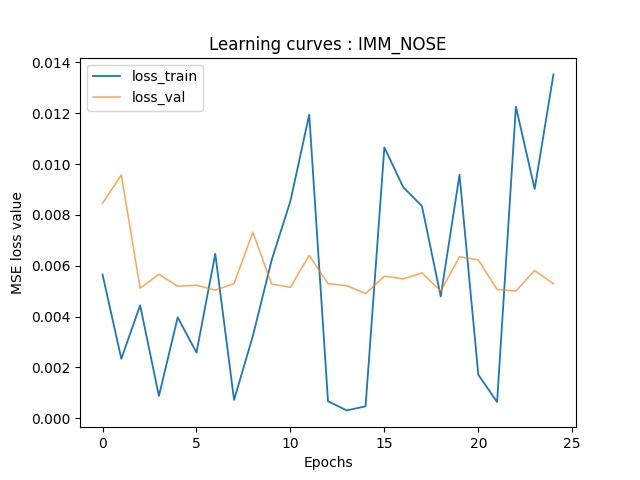
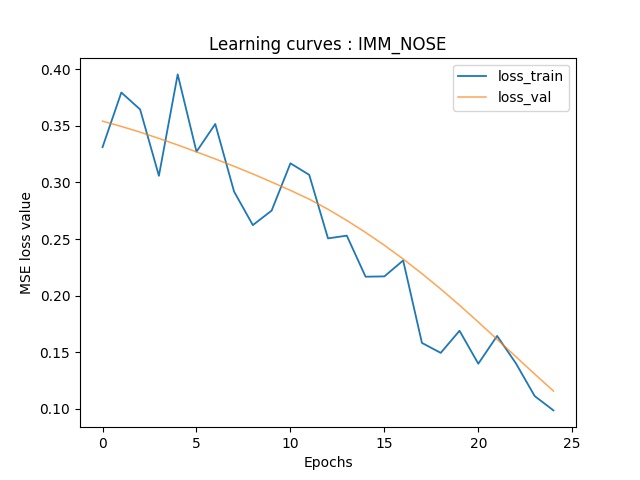
Part 3: Train With Larger Dataset
My Kaggle user name is penywis, and the MAE score I got is 9.13370.
Here is the architecture of my model, which is based on the pretrained ResNet18. For this part, I use the following hyperparameters: batch_size=2, lr=1e-5, num_epochs=100.

I made several adjustments to the model in this part: I changed the first layer's input channel, which uses 1 instead of 3, and I changed the output channel of the last fc layer from 1000 to 136. I use similar data augmentations for the dataset: color jitter, random rotation between -15 to 15, and random shift between -10 to 10. I noticed that the bounding box of the dataset is somehow too small, so I shrunk the top-left corner by 0.8 and the bounding box by 1.2 to get a larger patch before I resized it to 224 by 224 and normalized images to the range of (-0.5, 0.5).
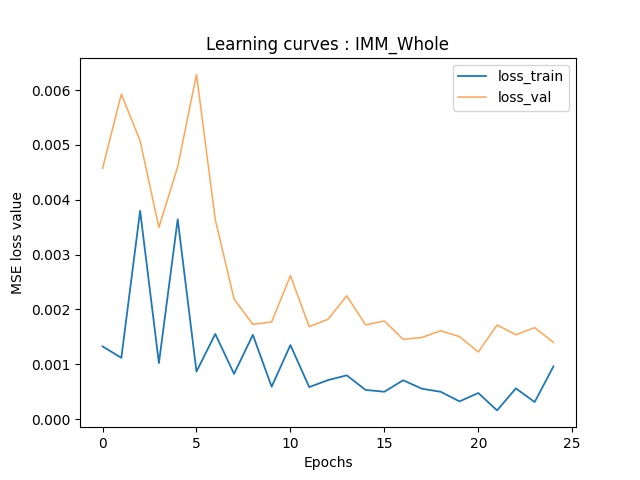
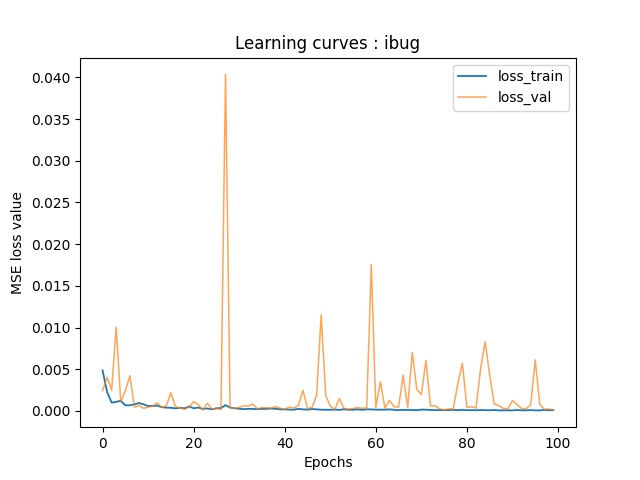
Here are the training-validation curves of my model. Due to the fact that I use batchsize of 1, there're some oscillations in the validation curve.
Here are some examples of the test set images. For some of them, the network is performing great with some minor inaccuracy, while for others, the features points are quite non-sense.
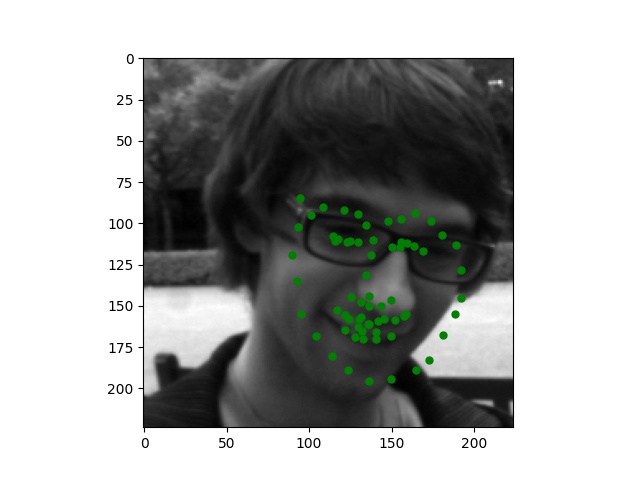
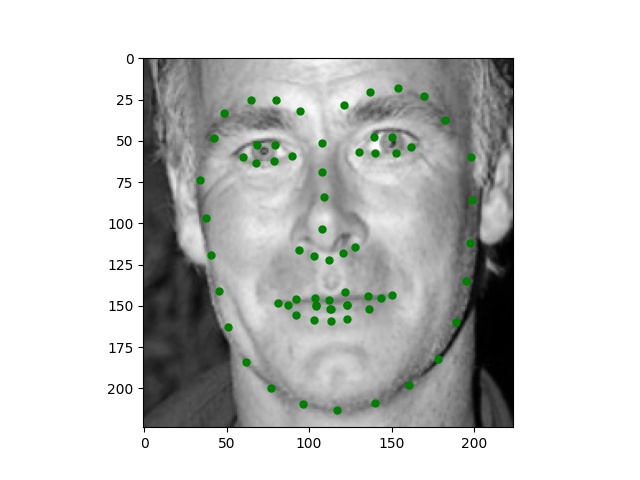
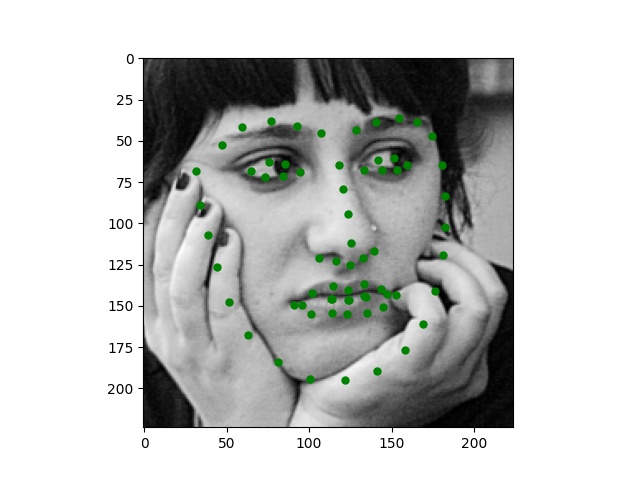
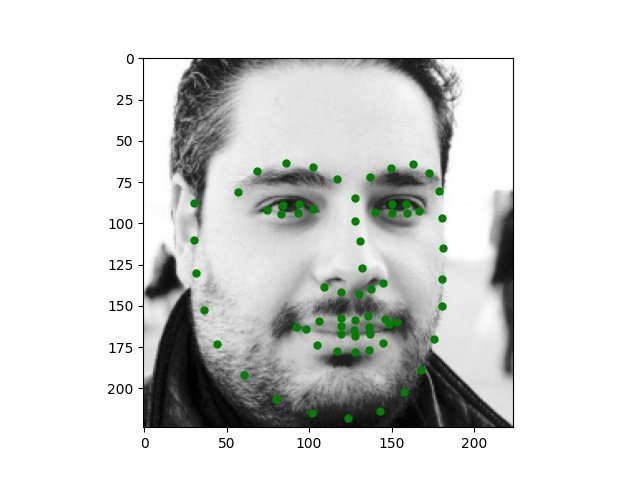
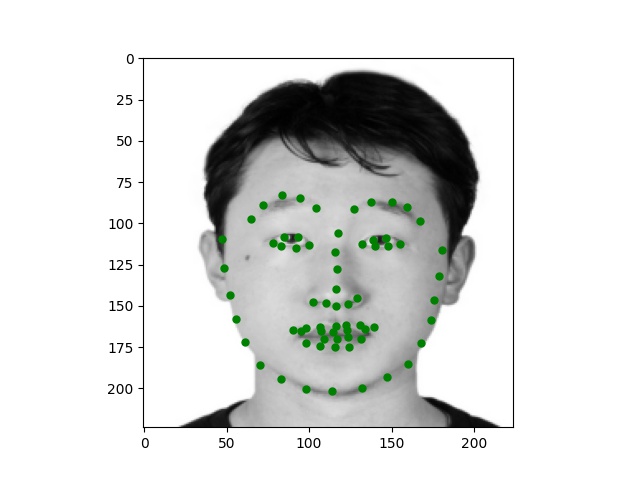
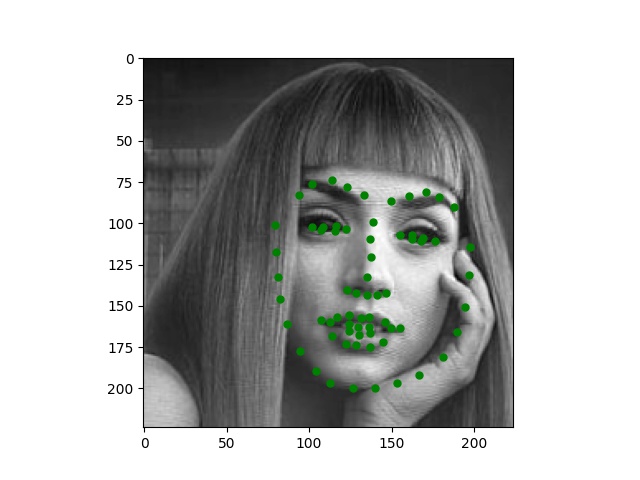
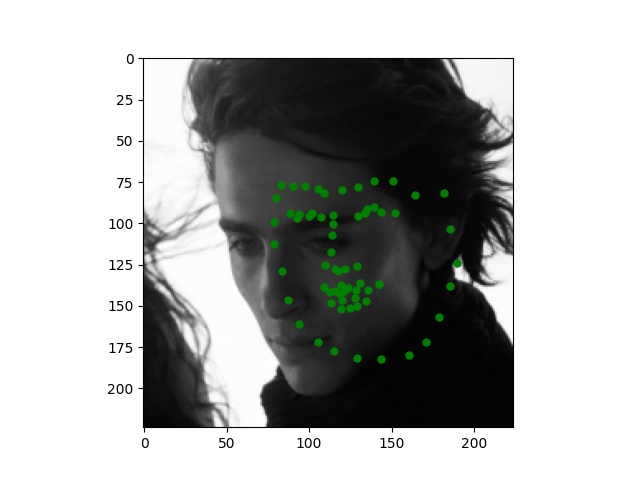
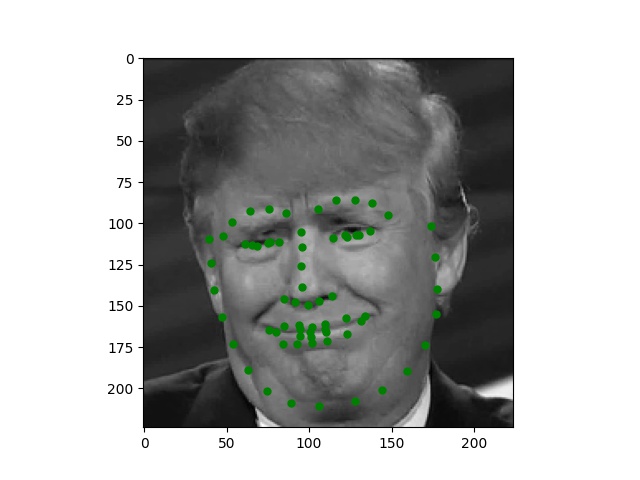
Here are some images I collected by myself and ran through the trained network. While the network performs perfectly on passport-style images as expected, it also produces excellent quality on Trump and Joi but fails on Paul's face.