Project 5: Facial Keypoint Detection with Neural Networks
CS 194-26: Intro. to Computer Vision & Computational Photography, Fa21
Doyoung Kim
Overview
Using a dataset that consists of facial figures and labels denoting some of the facial features such as eyes, nose, chin and etc, I trained Convolutional Neural Network so it can recognize those facial features from an un-seen image.
First, I started with detecting where the tip of the nose is, and then I moved on to detect the entire facial features from face images. Pytorch was used as a deep learning framework.
Part.1 Nose Tip Detection
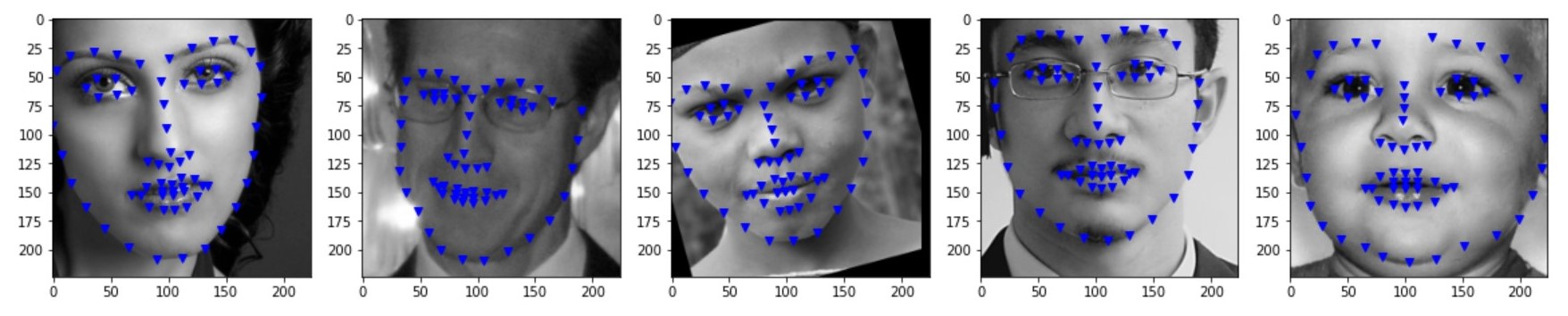
The images above are some of the sample images and label(tip of the nose) that will be used in training. These are loaded with the data loader implemented in PyTorch.
To start off, we first set up the dataloader which allows to conveniently extract the data in batches while training and testing the neural net. And then, set up the CNN as the project description requires as the follwoing:
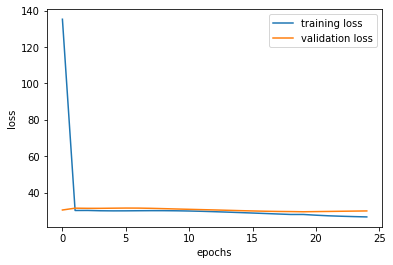
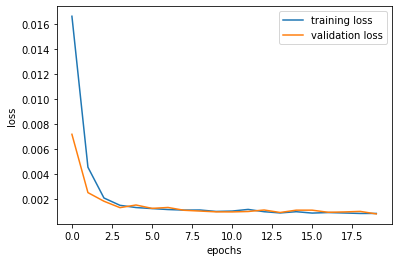
While training, I set the training set separately to training set and validation set. And this allowed me to come up with some plottings on loss values for training and validation. See the following plot:
After training with 25 epochs with a leanring rate of 1e-3 with the CNN described above, some of the successful/failing results are the following. Blue point represents the prediction from the CNN and the red point represents the ground truth:
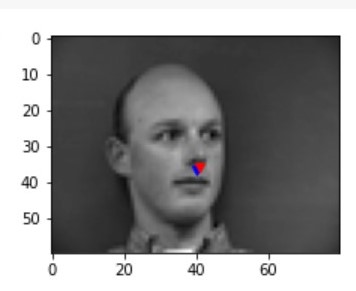 succss 1 succss 1
|
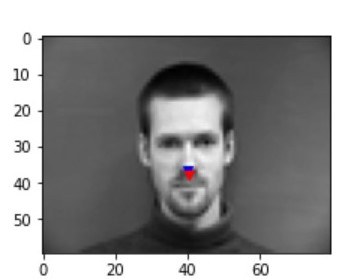 success 2 success 2
|
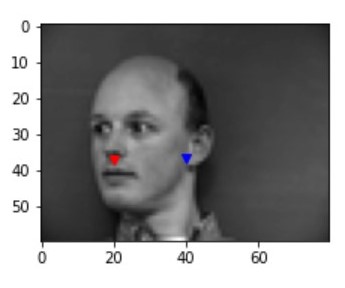 failure 1 failure 1
|
 failure 2 failure 2
|
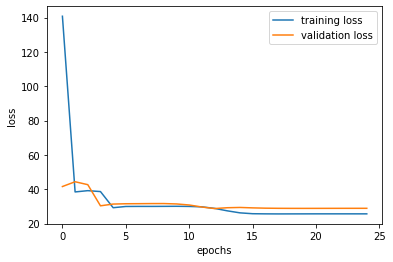
To check if changing the hyper parameters changes the result, I tried to add more layers and tried out different learning rate of 1e-2. The following results show plotting and some of the prediction results by training with a lower learning rate of 1e-2.
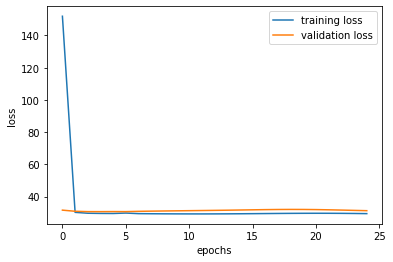
The following results show plotting and some of the prediction results by training with a an additional layer of Convolutional Layer within the CNN and a learning rate of 1e-3:
Changing the learning rate to 1e-2 seems to work well compared to 1e-3 at least with the epoch of 25 and adding an additional convolutional layer doesn't seem to do much.
Part. 2 Full Facial Keypoints Detection
In part 2, rather than detecting the tip of the nose, we try to predict the entire facial keypoints given in the dataset. As the task is more complicated, we use data augmentation to improve the lack of data. By shifting and rotating randomly of the given training dataset, I improved the quantity of dataset. Also, by adding more layers to the CNN, we try to learn more detailed features from the data. The following are some of the augmented images from the dataloader that are used to train followed by the architecture of the used CNN.
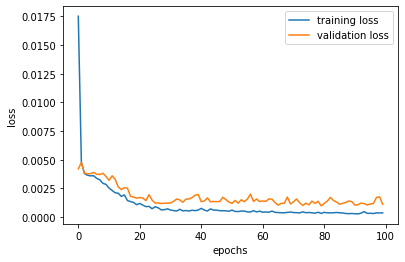
I have played around with the learning rates and the filter sizes and concluded that the learning rate of 1e-3 was the best with the filter sizes and architectre described above. Following is the plotting for the training and the validation losses:
After iterations of 100 epochs with a learning rate of 1e-3 and data augmentation, following are some of the results I gained. Blue points are the prediction from the CNN and the green points are the ground truth label from the dataset:
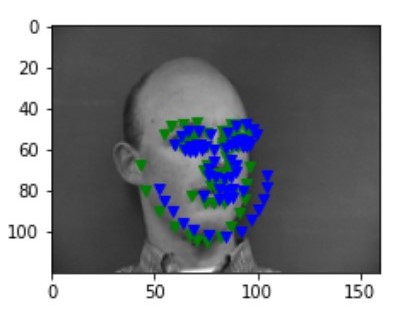 succss 1 succss 1
|
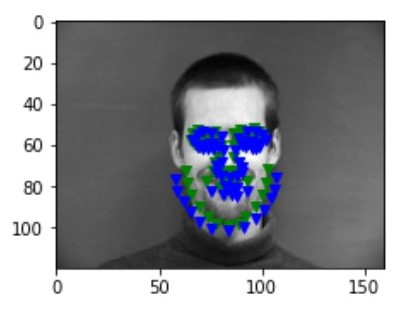 success 2 success 2
|
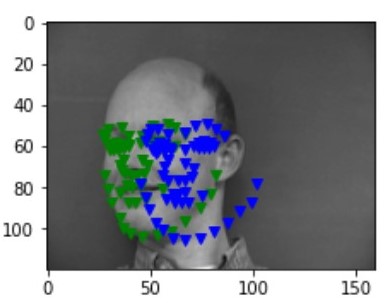 failure 1 failure 1
|
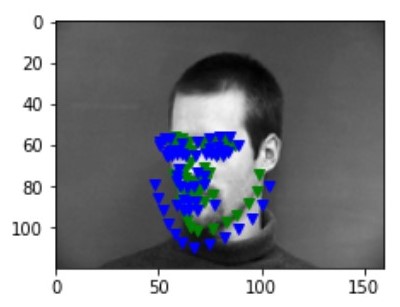 failure 2 failure 2
|
There are some of the images that fails like above, and they seem to face somewhere else rather than facing front. I believe this happens as majority of the images in the dataset are facing front. This issue can be resolved by having more images that are not facing front.
One of the great properties of CNN is that it can learn filters that can distinguish each image's feature. Following are some of the filters learned in each of the layer.
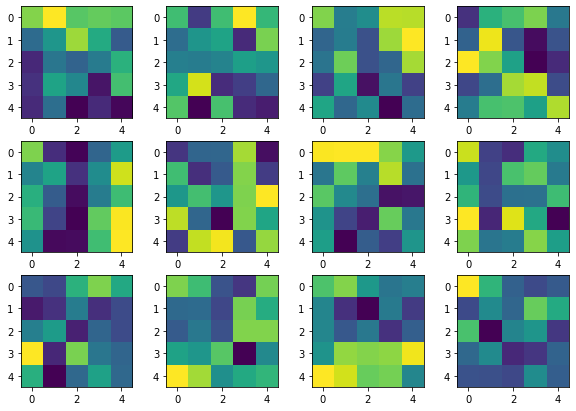 1st layer 1st layer
|
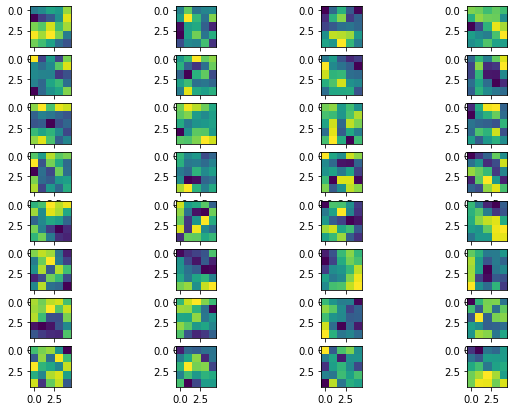 2nd layer 2nd layer
|
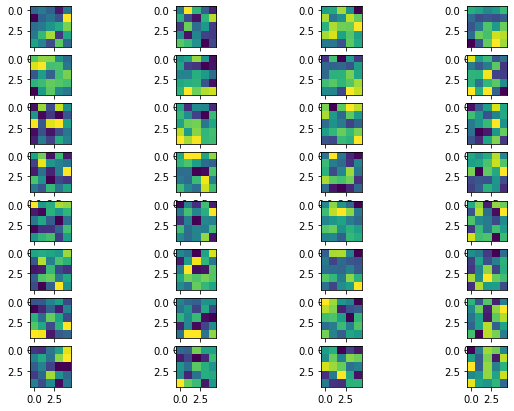 3rd layer 3rd layer
|
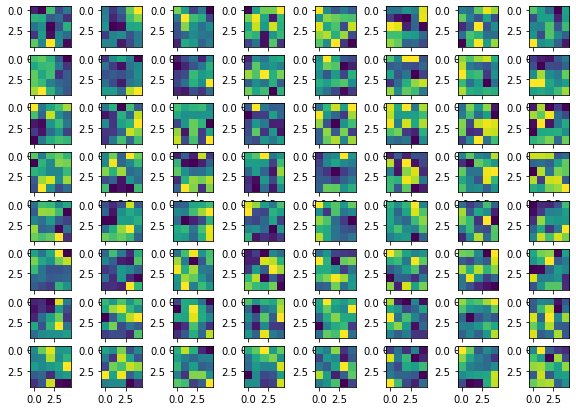 4th layer 4th layer
|
 5th layer 5th layer
|
Part. 3 Train With Larger Dataset
Now we move on to a larger dataset of 6,666 images with full facial keypoint features. The dataset used previously contained images that the majoirty of the image was the face. However, we use some pictures that contains human face, but not necessariy being face images. Hence, we would have to not only use larger model, but also train and test on the cropped face image, and then put the pieces together.
As the dataset got larger, we use some verified, large model that is pretrained, Resnet18. The Architecture is shown in the following:
Some of the cropped images according to the given bounding bo from the dataset with the facial keypoints looks like below:
Trying out several hyperparameters such as epoch, batch size, learning rate, and size of the bounding box, the best result was given with 20 epochs, 1e-4 of learning rate, batch size of 16 and enlarged bounding box by x 1.2.
Following are the predictions made on unseen images along followed by training and validation loss plots:
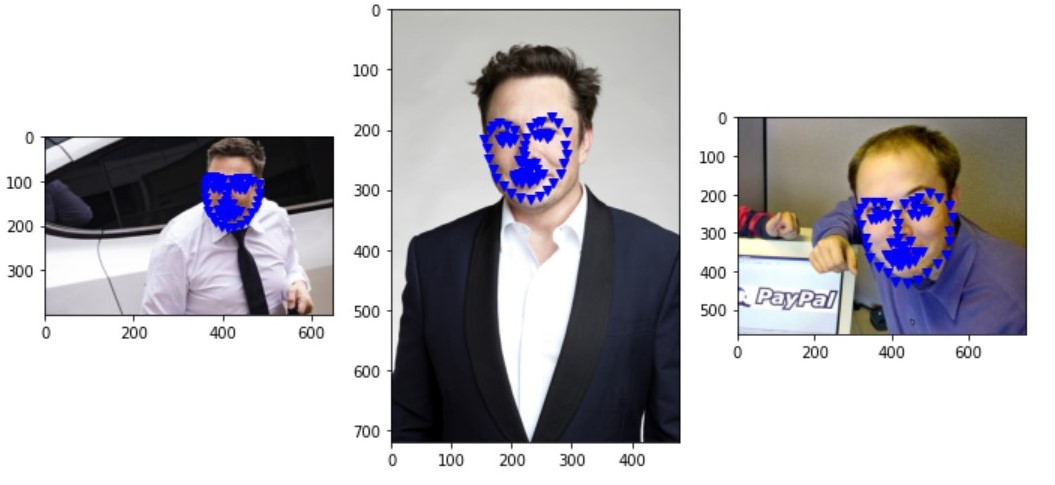
Similar to what we have seen in previous tasks, the model performs better on images that are facing front. Now, I try to predict the facial key points on picture of Elons.
 1st layer 1st layer
|
I purposely picked images that are facing the front as I have noticed the pattern of not working well on other orientations.