Part 1: Nose Tip Detection
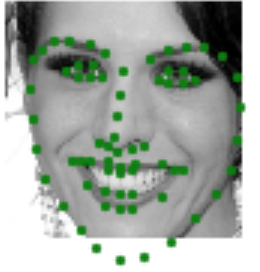
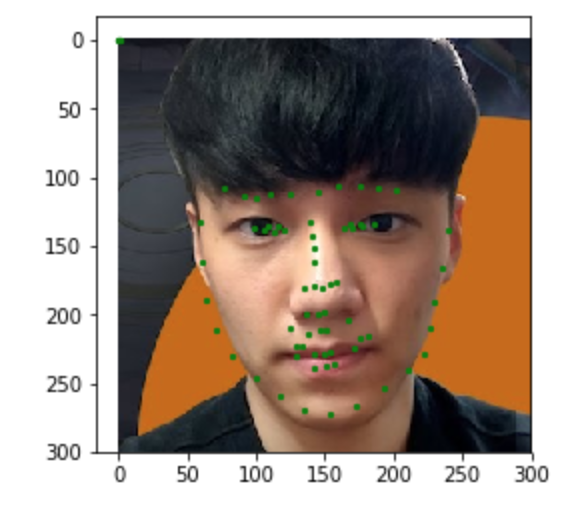
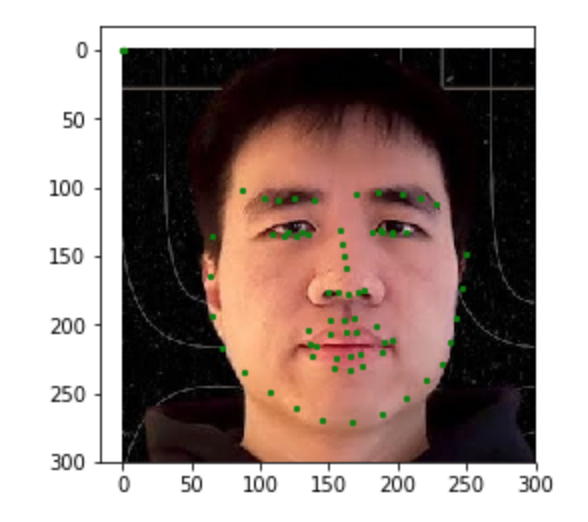
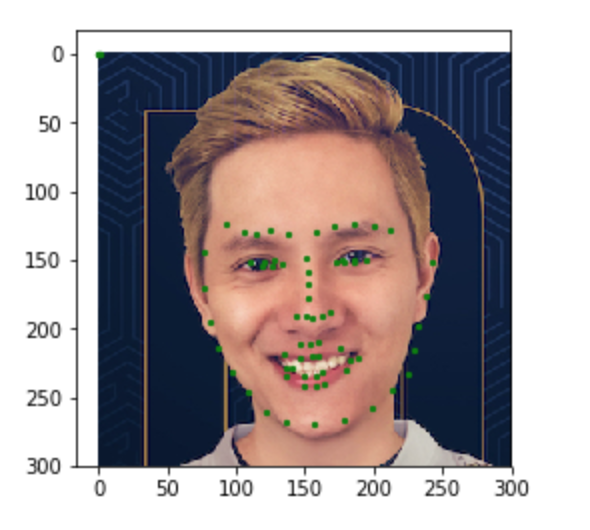
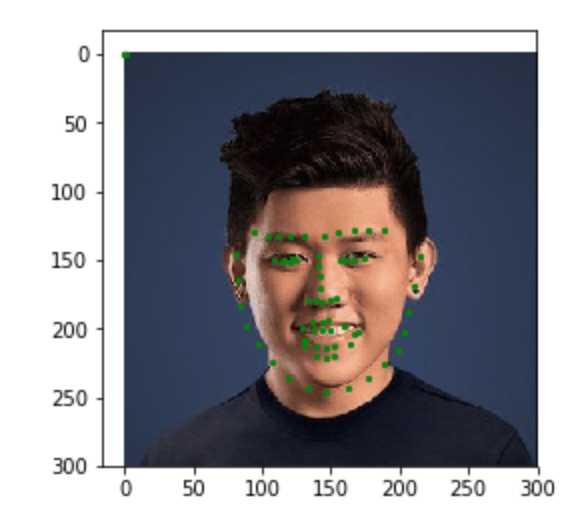
The goal of this part is to be able to predict the location of the nose keypoint on an input face image using a convolutional neural network. The first step is to create a dataloader for our face dataset. Here are some sample images from my dataloader visualized with the ground-truth keypoint.

Convolutional Neural Network Architecture
- Conv2d: 1 input channel, 6 output channels, 5x5 kernel
- Relu
- MaxPool (2x2)
- Conv2d: 6 input channel, 16 output channels, 5x5 kernel
- Relu
- MaxPool (2x2)
- Conv2d: 16 input channel, 32 output channels, 5x5 kernel
- Relu
- MaxPool (2x2)
- Fully Connected 768 x 120
- Relu
- Fully Connected 120 x 2
Training
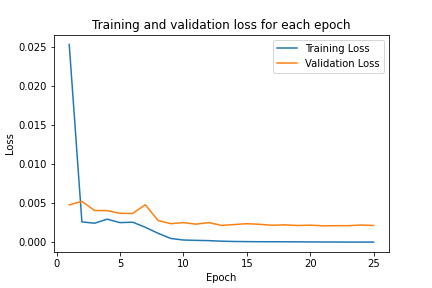
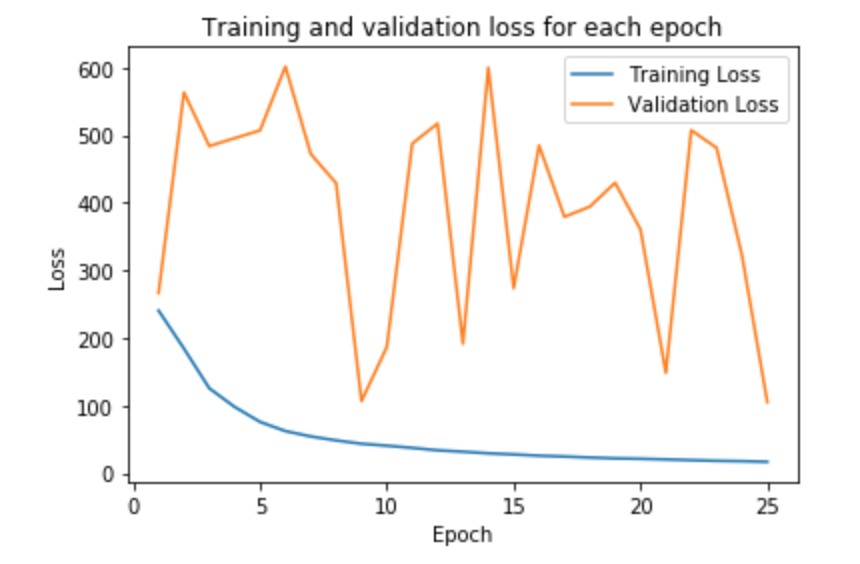
We now train our model for 25 epochs, using adam optimizer, MSELoss as our criterion, and 0.001 as the learning rate. Shown below is the plot for the training and validation MSE loss.
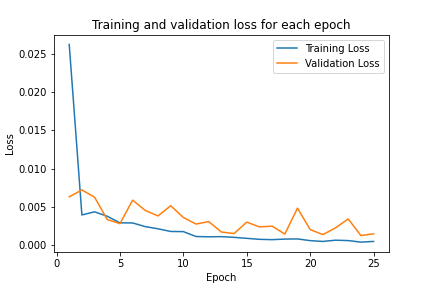
I also did hyperparameter tuning to see if I could make the model performance better. I first tried varying the learning rate to be 0.05. I then tried modifying the model architecture by increasing the sizes of the convolutional layers, and also adding one more fully connected layer. Here are graphs of the training and validation accuracy over time
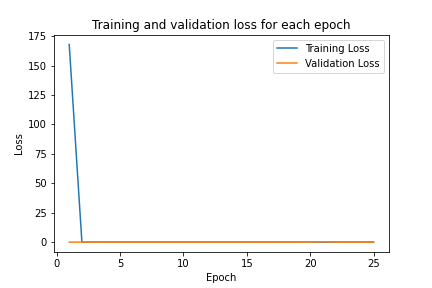
Varying Learning Rate
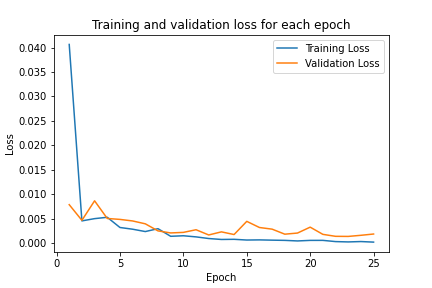
Changing model architecture
Evaluation
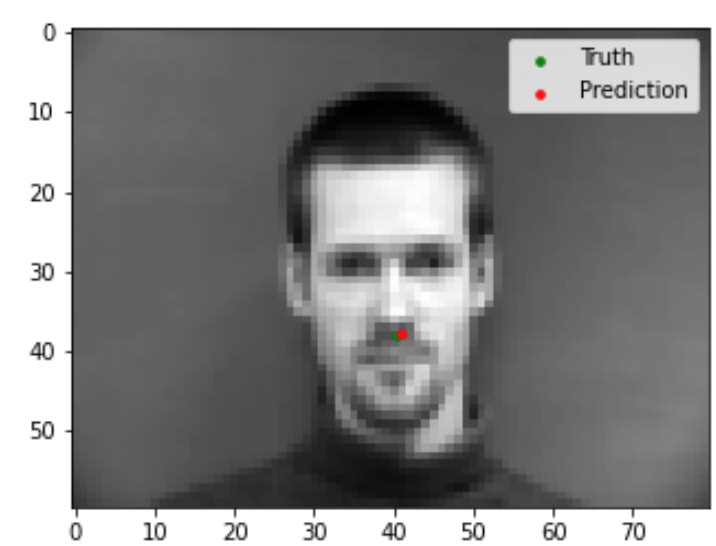
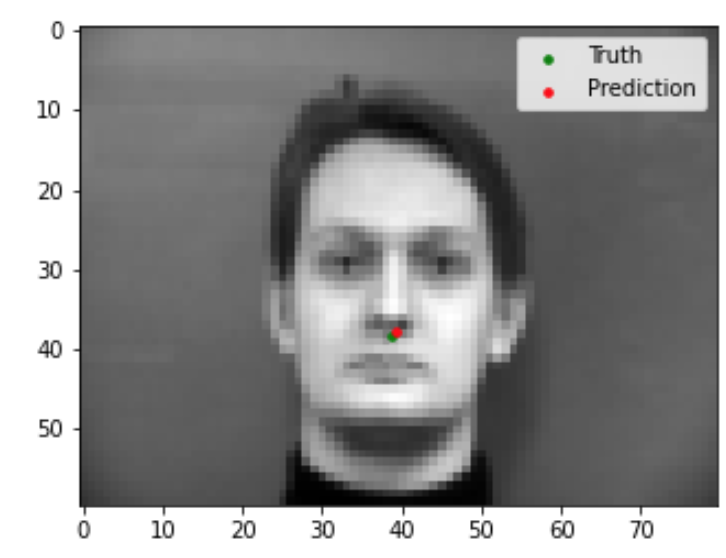
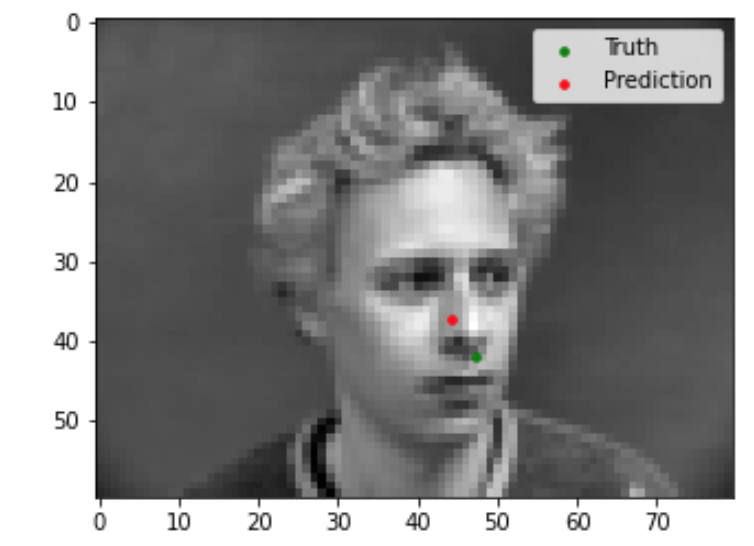
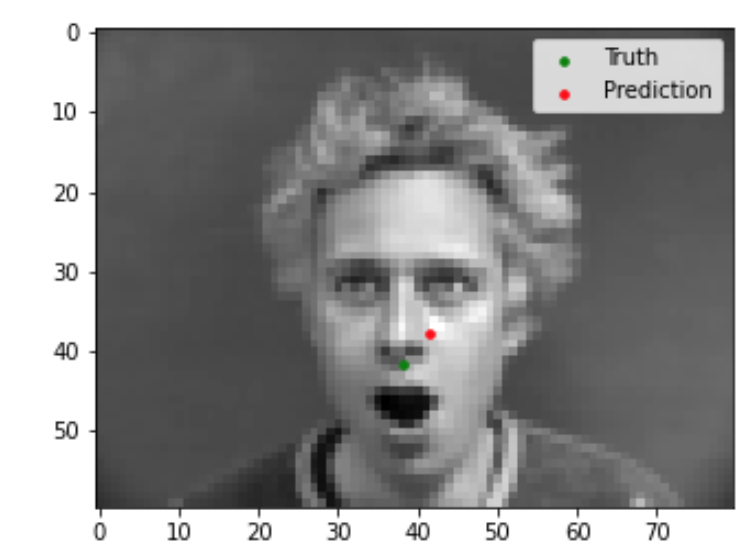
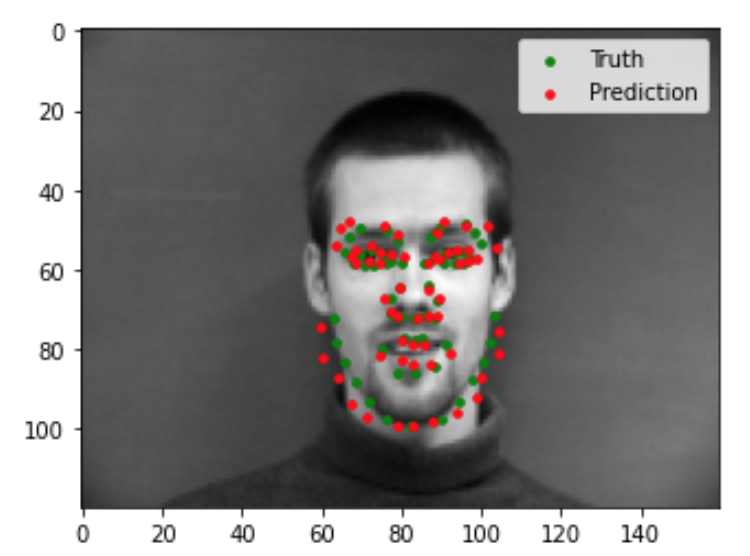
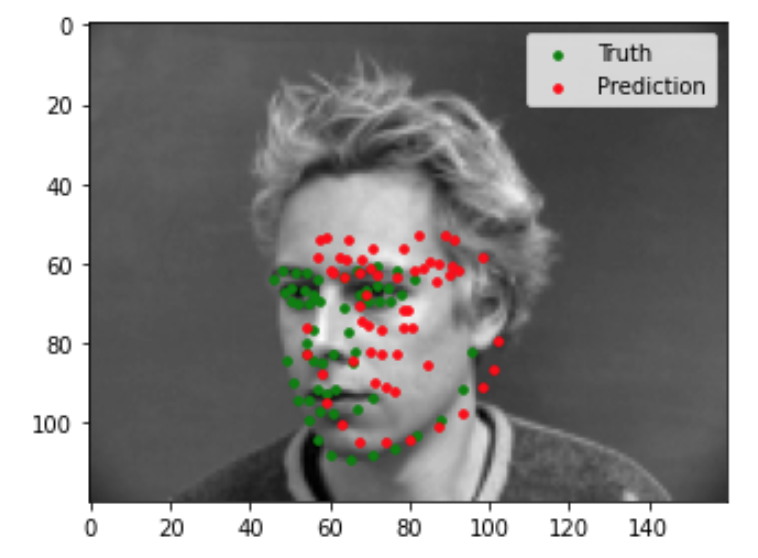
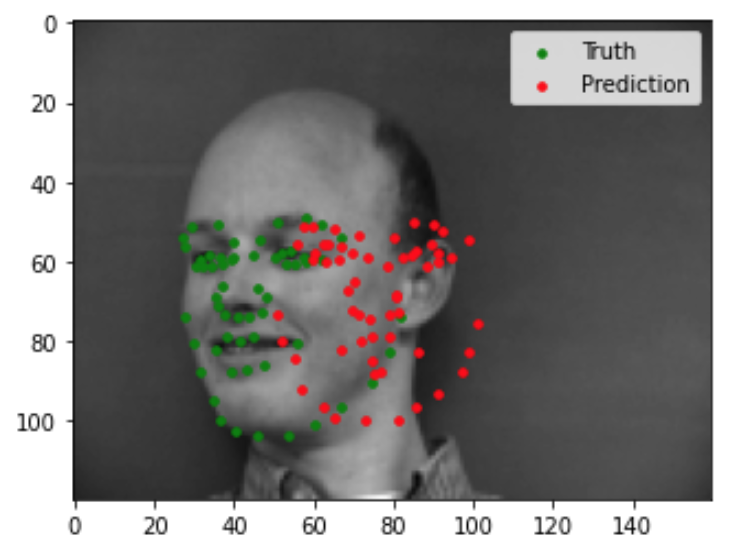
Now we can evaluate our trained model to see the quality of its predictions. Shown below are 2 images that the model did well on, and 2 images that the model did not do so well on. Based on these examples, it seems like my model is able to generalize well to images where the face is in a standard orientation with the mouth closed. In the two images that my model did poorly on, the person's face is turned sideways in the first, and the mouth is open in the second.