Project 4B: Feature matching and Autostitching
Nose Tip Detection
For this part, we use PyTorch and a simple CNN to train a model to detect the tip of the nose on faces. We are not predicting the entire set of 58 keypoints, but rather just 1 (x,y) keypoint for the tip of the nose.
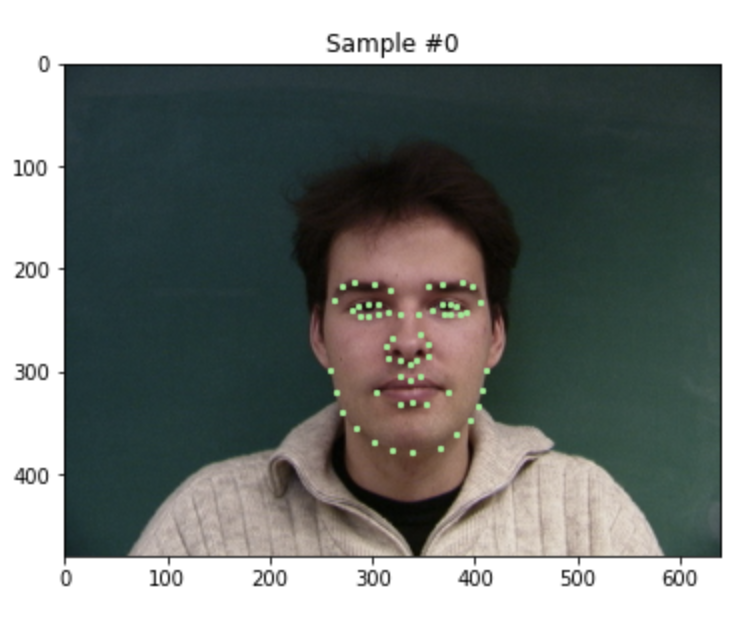
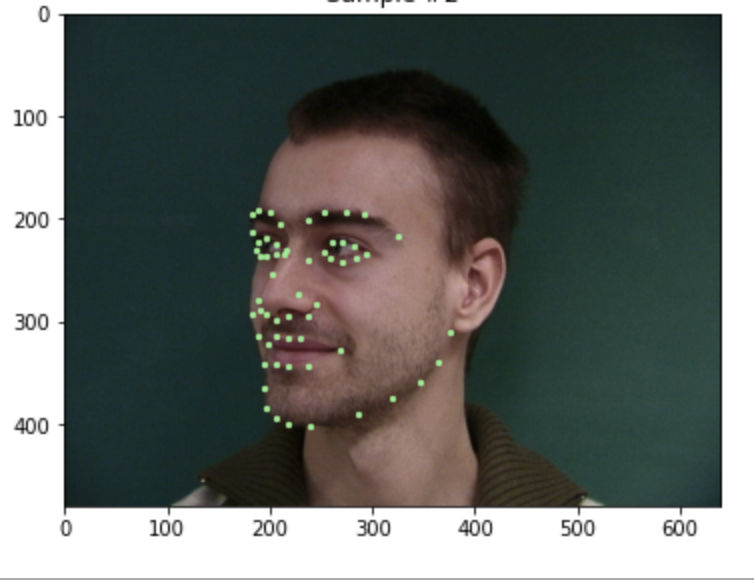
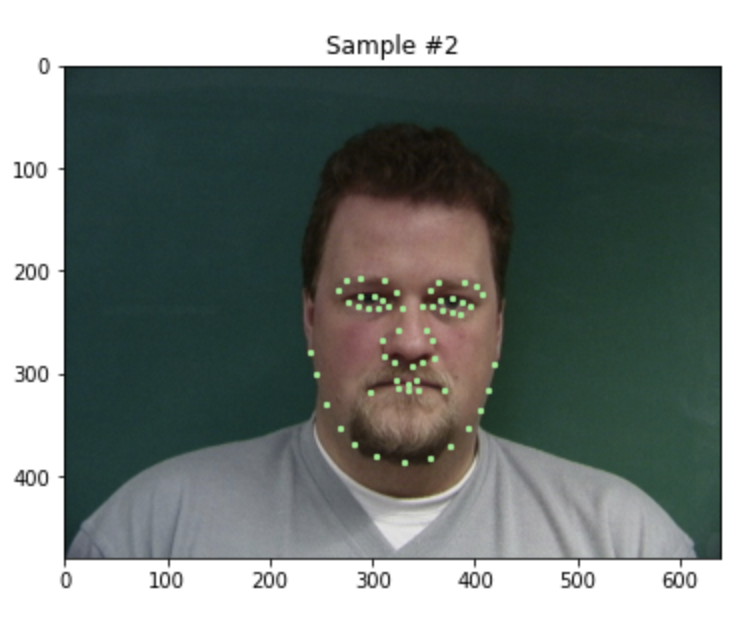
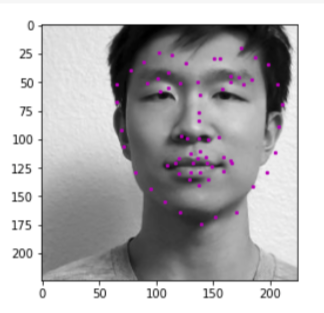
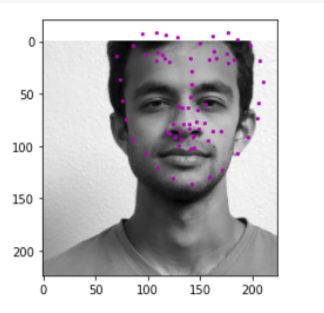
Visualizing the given keypoint on the tip of the nose
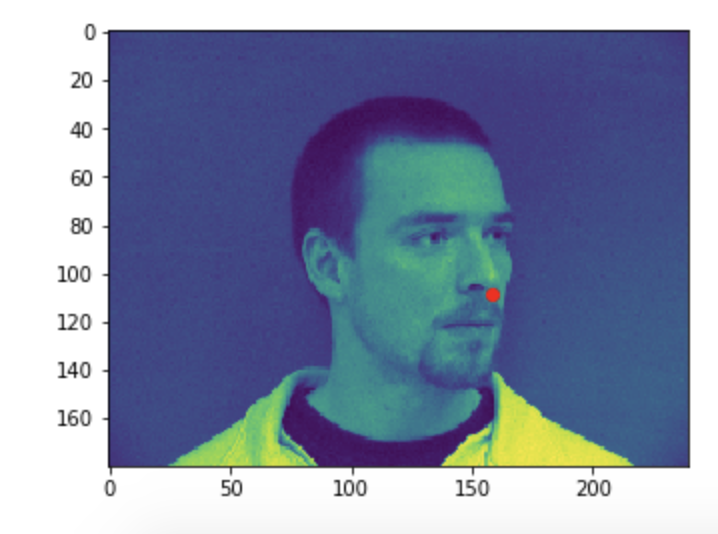
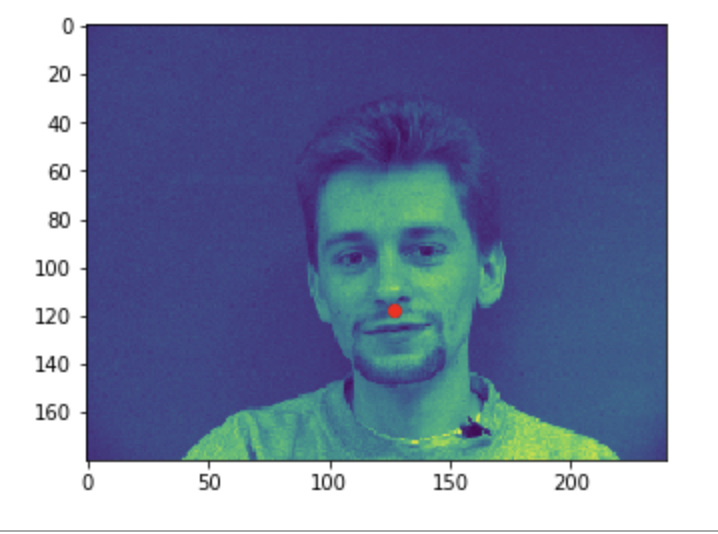
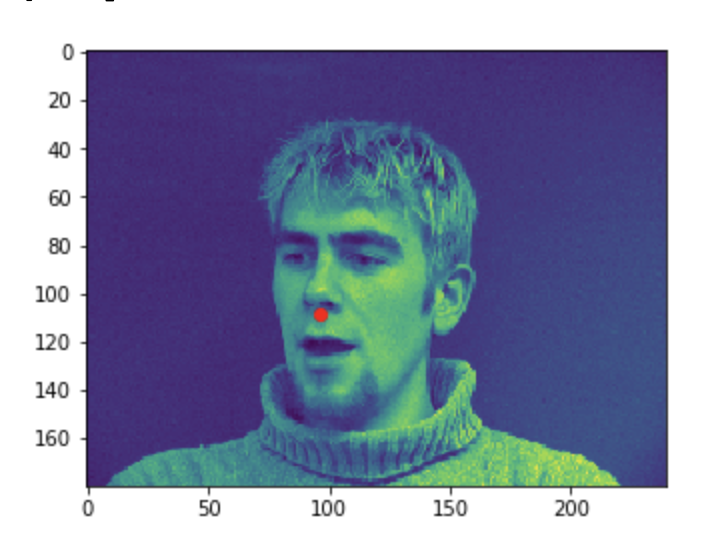
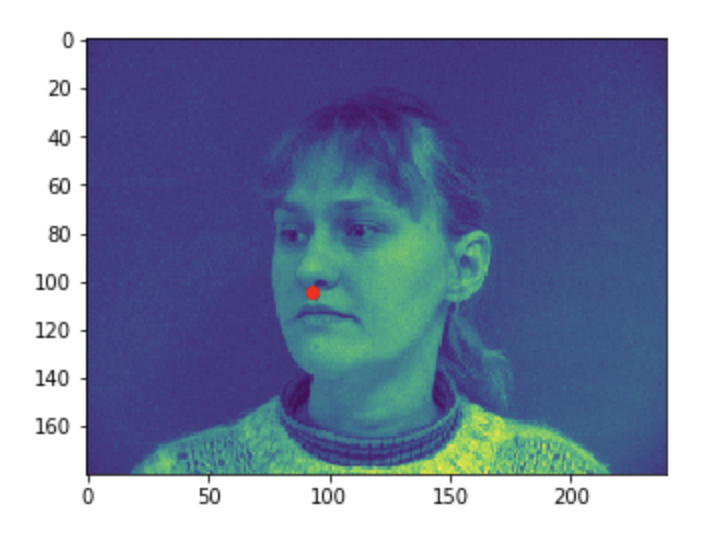
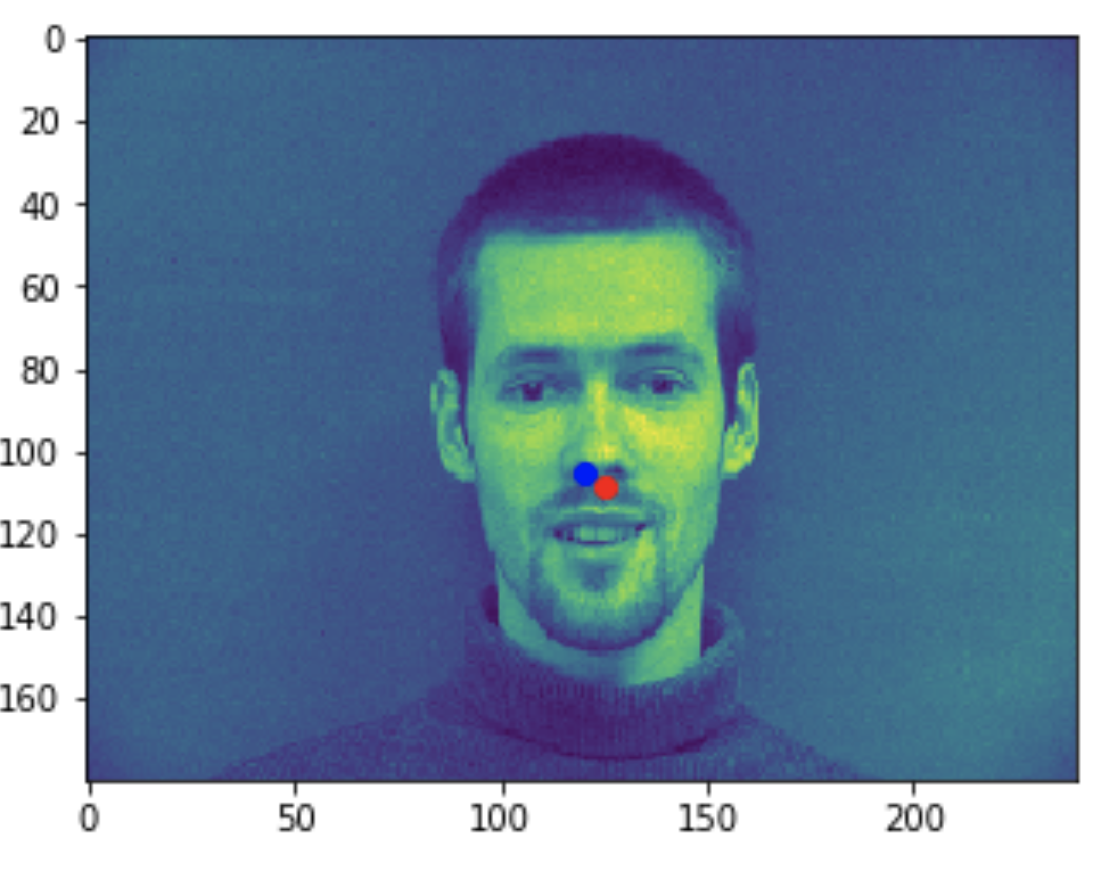
Some good predictions made on the testing set. The red marker is the true keypoint, and blue is the predicted keypoint
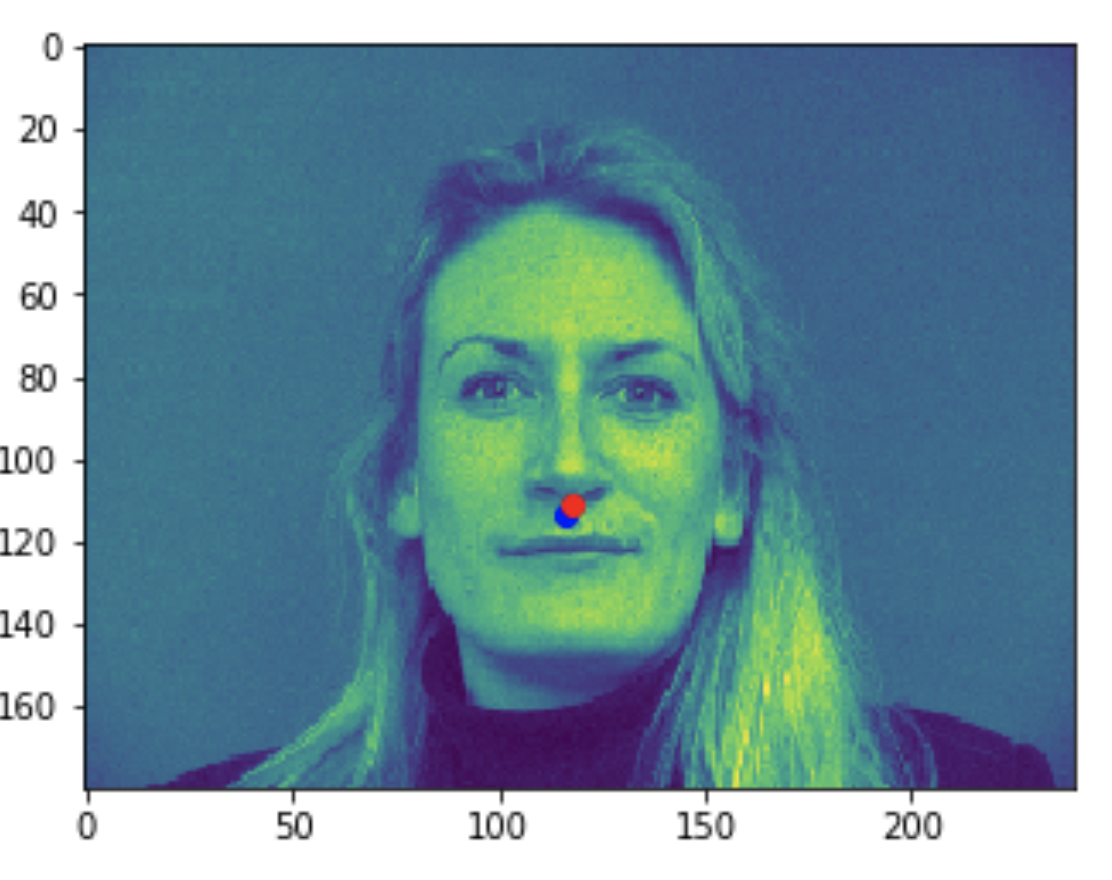
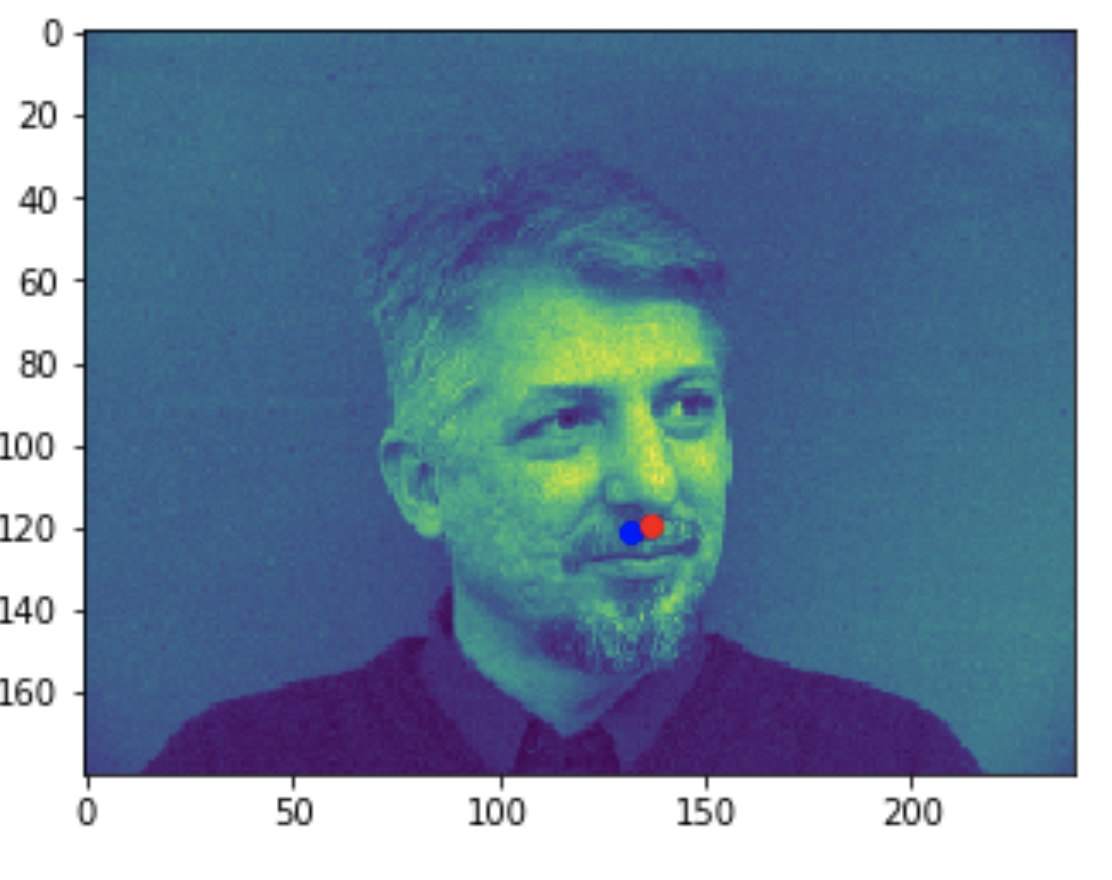
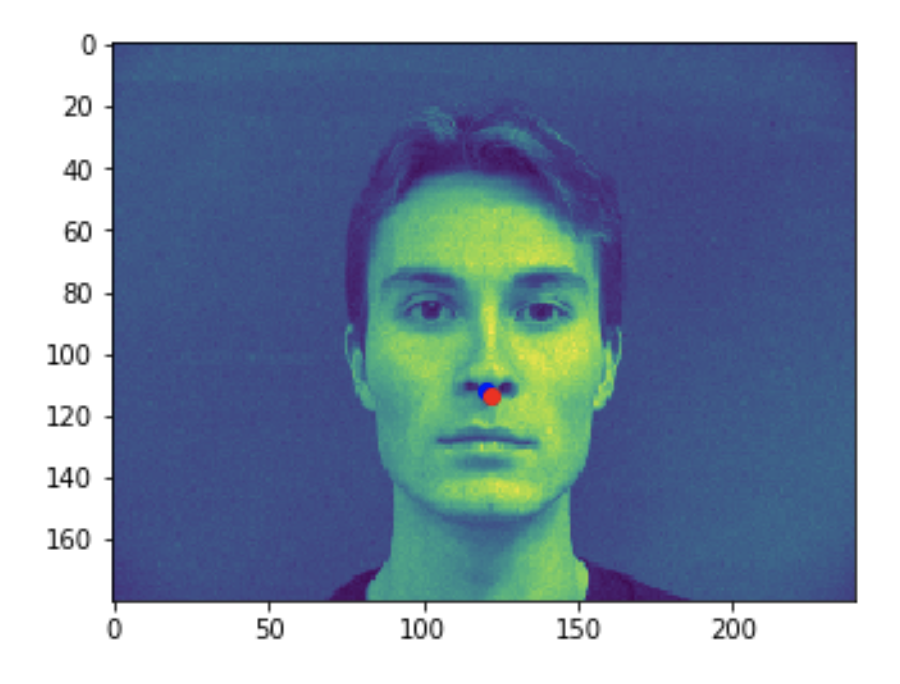
Some bad predictions made on the testing set. Again, red is the true keypoint and blue is predicted
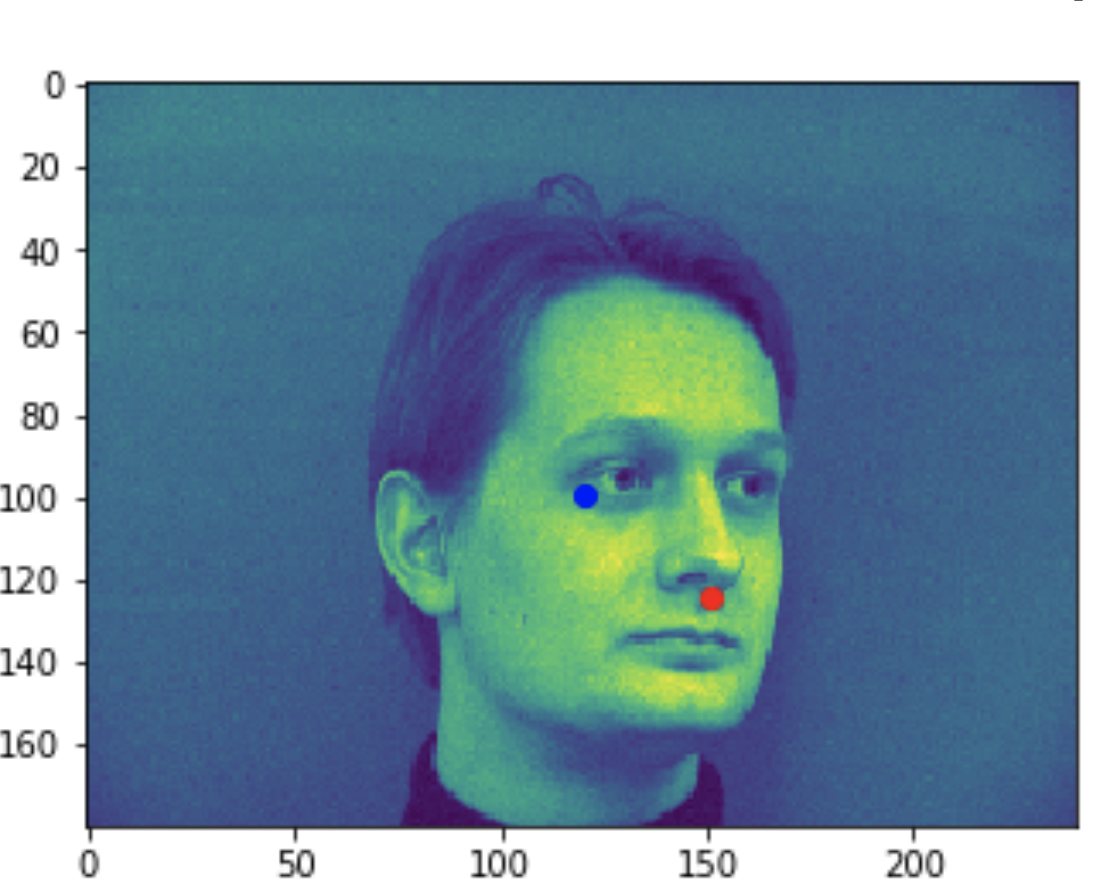
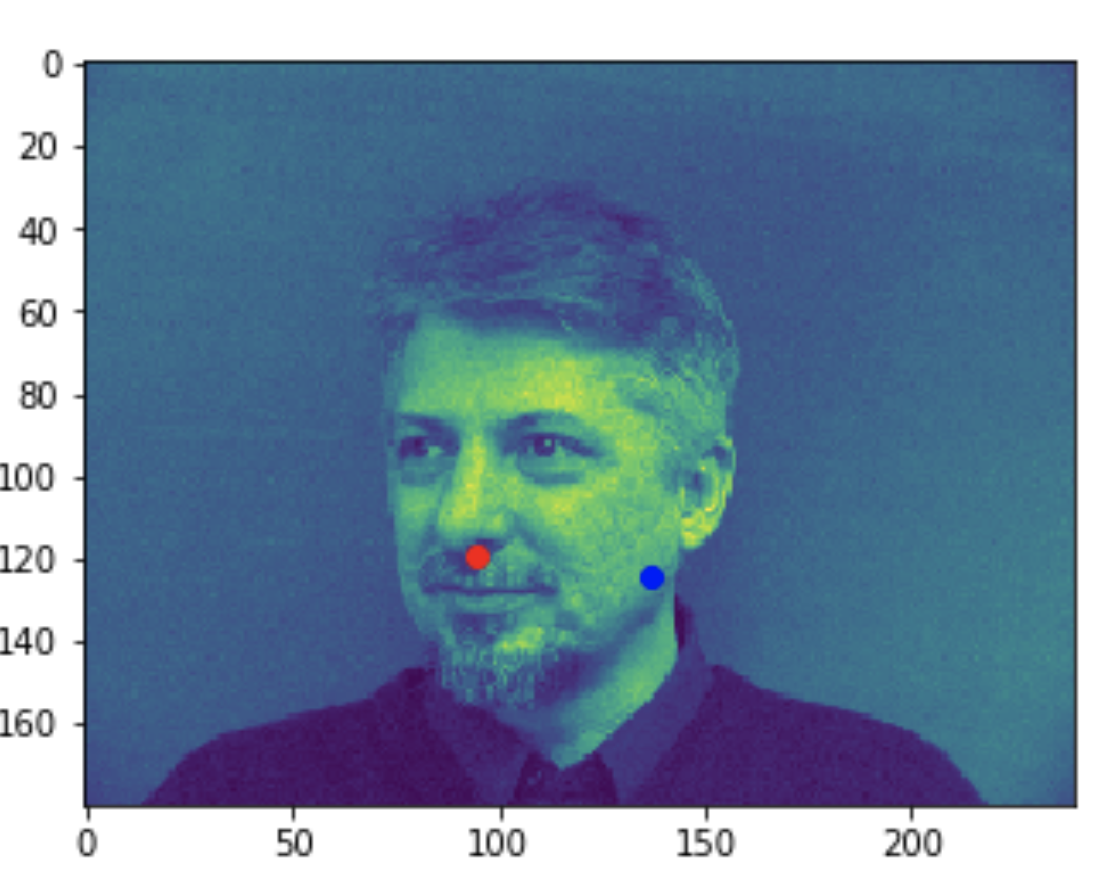
In all the bad images, the faces were tilted to the side, so that may have confused the model, making it perform worse. The predictions in these cases were near the middle of the photo, around where the nose would have been if the person was looking straight ahead.
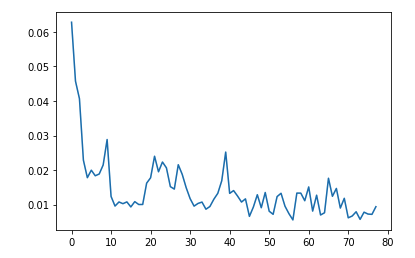
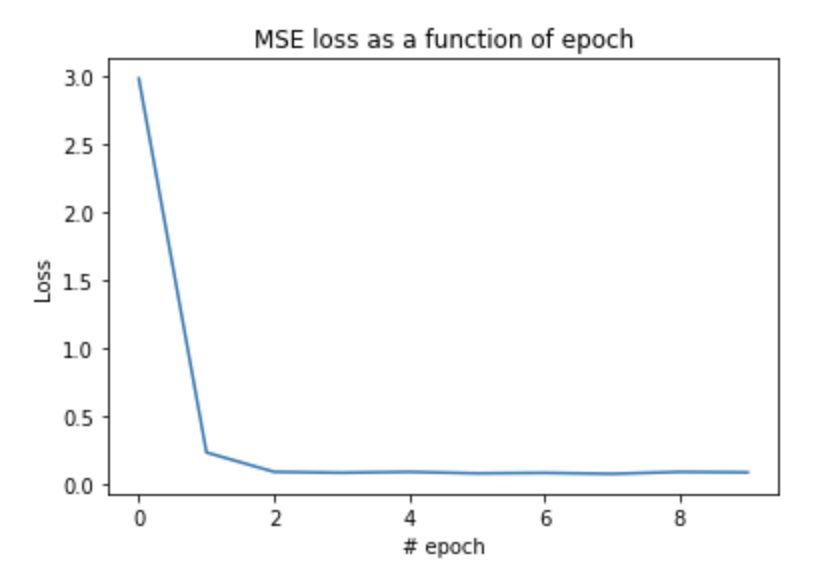
And here is the training loss seen. It quickly decreases, and then settles at around 0.01
A lower batch size did a lot worse, getting results as seen below. These predictions are very off, even on faces that are looking straight ahead. TODO: ADD PICS SHOWING THE BAD RESULTS