Part 1: Nose Tip Detection
I created a Dataset class to lead the images downscaled to 80x60. Here are some example images:

|

|

|

|
Then I created a CNN class that takes in a bunch of different hyperparameters so I can sweep over. The basic structure is:
- Three layers of Conv2d with 32 channels, kernel size 3, stride 1
- ReLU activation after each Conv2d
- MaxPool2d after each ReLU with size 2 and stride 2
- After the 3 Conv2d blocks, flatten the output and pass through a Linear layer with ReLU activation
- Finally pass through the output Linear layer with output size of 2, no activation
Then I created the training loop, using the Adam optimizer. I used learning rate of 6e-5, batch size 1, 25 epochs. I also used early stopping, which meant I save the epoch with the best validation loss and load it back after all the training is done, to prevent overfitting. Here's the learning curve:
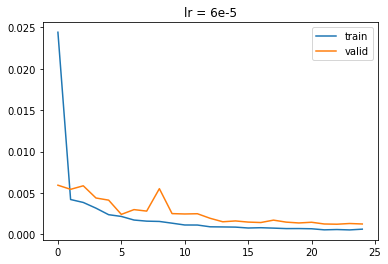
This model achieved best validation loss of 0.001234.
I also sweeped two hyperparameters: learning rate and kernel size. I sweeped learning rate over three values, 1e-4, 6e-5, and 1e-5. Here are the results:
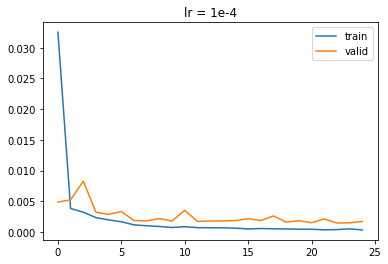
|
|
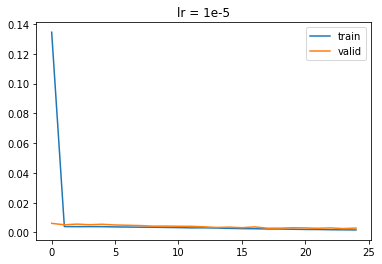
|
We see that 6e-5 is the best, with best validation loss of 0.001234. 1e-4 got 0.001446 so it overfitted. 1e-5 got 0.00259 so it likely got into a local minima and couldn't get out due to its low learing rate.
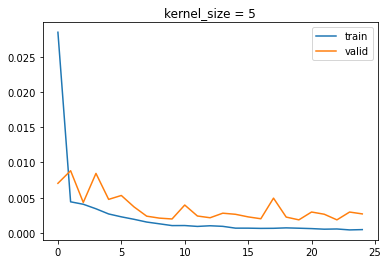
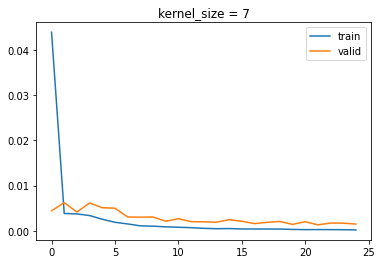
For kernel size, I tested 3, 5, and 7:
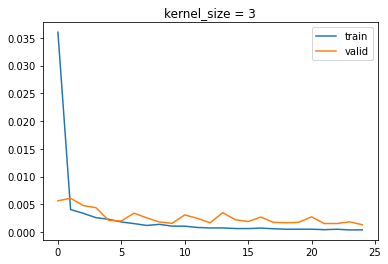
|
|
|
Size 3 got 0.001304, 5 got 0.00186, and 7 got 0.001294.
Here are 2 images that the network correctly predicted (red is prediction, green is true label):

|

|
Here are 2 images that the network incorrectly predicted:

|

|
The incorrect ones are likely due to the small size of dataset and their faces being turned to the side, so it hasn't seen enough samples of this situation. Their face shape and hair color might also attribute to this, being more rare in the dataset.
Part 2: Full Facial Keypoints Detection
I created a Dataset that output image with size 240x180, and uses augmentation. The augmentation techniques I used was first to randomly crop it and resize back to 240x180, then color jitter, convert to grayscale, and then rotate the image randomly 15 degrees either direction. This now also outputs the entire keypoints, not just the nose, and I had to transform the points as well according to the augmentation. Here are some examples from the dataset:

|

|

|

|
The CNN architecture is as follows, with a total of 5,843,028 parameters:
(0): Conv2d(1, 16, kernel_size=(7, 7), stride=(2, 2))
(1): ReLU()
(2): Conv2d(16, 32, kernel_size=(5, 5), stride=(2, 2))
(3): ReLU()
(4): Conv2d(32, 32, kernel_size=(5, 5), stride=(2, 2))
(5): ReLU()
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(7): ReLU()
(8): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(9): ReLU()
(10): Flatten(start_dim=1, end_dim=-1)
(11): Linear(in_features=22080, out_features=256, bias=True)
(12): ReLU()
(13): Linear(in_features=256, out_features=256, bias=True)
(14): ReLU()
(15): Linear(in_features=256, out_features=116, bias=True)
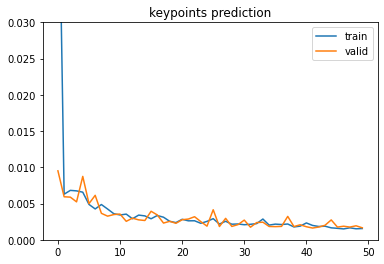
For training, I used 50 epochs, batch size 1, learning rate of 5e-5, Adam optimizer, and early stopping on validation loss. Here is the learning curve, which achieved final validation loss of 0.001621.
Here are 2 images that the network correctly predicted:

|

|
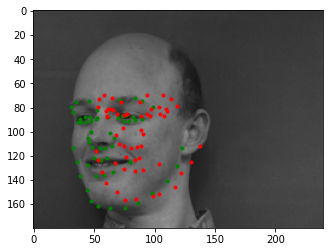
Here are 2 images that the network incorrectly predicted:

|
|
Notice how the people this fails on are the same as in Part 1, because they have uncommon facial structure including hair color or lack of hair. Since dataset is small, it doesn't learn as well on those, even with data augmentation. It also has issue with people with their face turned to the side, possibly due to the network not being large enough.
Here are the 16 7x7 filters that the CNN learned in its first Conv2d layer:

Part 3: Train With Larger Dataset
For the Dataset, I used the same data augmentation techniques as Part 2. I also used a 80-20% train-validation split for early stopping in the training, which is done by randomly choosing 20% of the training set as the validation set, and train on the other 80%. I also had to use the bounding box and resize image to 224x224.
The CNN I used was ResNet18 provided by torchvision. I used the pretrained resnet18 model, but replaced
the first Conv2d layer to use input channel of 1 (since grayscale), and replaced the last fully-connected layer to have
output size of 136 instead of 1000. See the ResNet paper for details
on the architecture. PyTorch outputs this as the architecture:
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
This model has a total of 11,240,008 parameters.
I trained the model over 100 epochs, with learning rate 1e-4, batch size 128, using Adam optimizer. Here is the learning curve, with a final validation loss of 0.0005983:
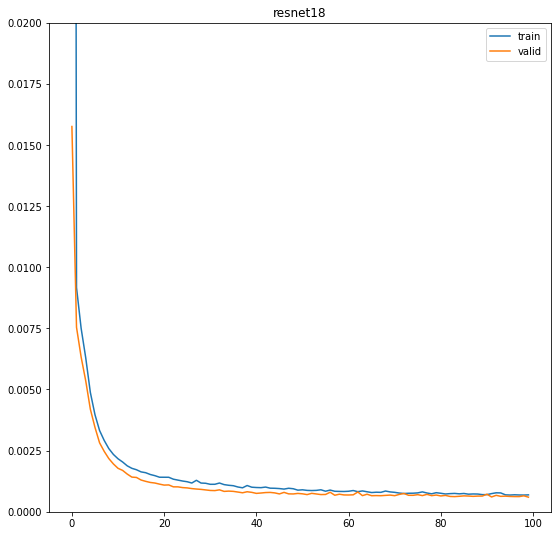
We see that validation loss is slighly below training loss, which means it is underfitting slightly, but that is okay since we want to generalize to our test set.
Here are some images with its prediction in the test set, renormalized and shifted back to original image pixel coordinate.

|

|
|

|
I see that it does pretty well. On Kaggle I got score of 7.81921.
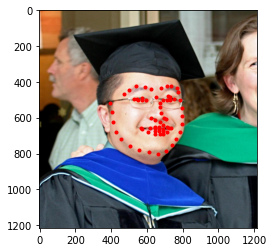
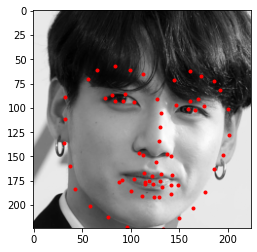
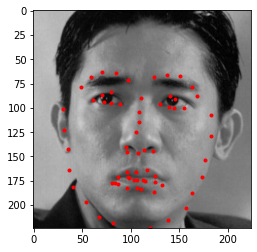
I also tried it on three images I chose. I also had to provide my own bounding boxes. Below we see the prediction on the actual input, and also their corresponding original image:

|
|
|

|
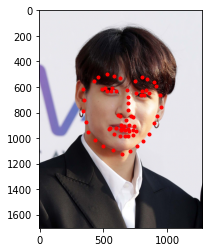
|

|
It worked really well on all three images. We do see that it tends to not fit properly to the chin area, typically predicts a larger shape than what it actually is, probably due to how the data is distibuted in the original dataset.