Facial Keypoint Detection with Neural Networks

In this project, I explore automatically detecting facial features through the use of convolutional neural networks on the IMM Face Database.
Part 1: Nose Tip Detection
Dataloader
First, we must create a dataloader that parses through the IMM face database, and returns a face, along with its nose point. We first preprocess the images by converting them all to grayscale, and normalizing the pixel values to float values between -0.5 and 0.5. We then resize the images to 80x60. Here is a face with its corresponding nose point after preprocessing:

CNN
After tweaking hyperparameters and architectures, I settled on a neural network with three convolutional layers, two max-pool layers, and two fully-connected layers. I used mean squared error as the loss function, and used an Adam optimizer with a learning rate of 0.01 to train the network. Here is a detailed overview of the network:
| Layer | Output Shape | Number of Parameters | |
|---|---|---|---|
| 1 | Conv2d-1 | [1, 8, 60, 80] | 208 |
| 2 | ReLU-2 | [1, 8, 60, 80] | 0 |
| 3 | MaxPool2d-3 | [1, 8, 30, 40] | 0 |
| 4 | Conv2d-4 | [1, 16, 30, 40] | 3,216 |
| 5 | ReLU-5 | [1, 8, 30, 40] | 0 |
| 6 | MaxPool2d-6 | [1, 8, 15, 20] | 0 |
| 7 | Conv2d-7 | [1, 32, 15, 20] | 12,832 |
| 8 | ReLU-8 | [1, 32, 15, 20] | 0 |
| 9 | Linear-9 | [1, 16] | 35,856 |
| 10 | ReLU-10 | [1, 16] | 0 |
| 11 | Linear-10 | [1, 2] | 34 |
Here is a graph of the training and validation losses over time:
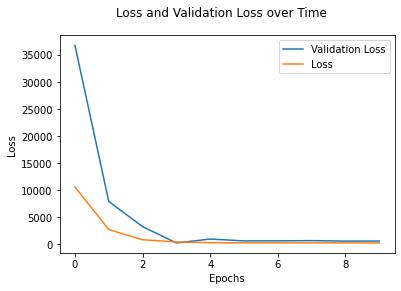
Results
In the following images, the red dots are the actual nose points, and the blue dots are the predicted nose points from our network. Here are two examples where the neural network did well:


Here are two examples where our neural network did not do well:


From these samples, we see that the CNN excels at picking nose points when the subject of the picture is centered and looking directly towards the camera, while it struggles when the subject is looking off to the side. A possible reason for why the network predicts the nose points of subjects with their heads turned less accurately is that the dataset itself consists mostly of pictures with the subject facing straight at the camera, and this disparity could have caused our network to perform worse when the subject is not looking straight at the camera.
Part 2: Full Facial Keypoints Detection
We now graduate from detecting one keypoint to predicting all labeled keypoints.
Dataloader
We use the same pre-processing we did in the nose-tip detection part, but we increase the size of our images to 120x160. We also employ data augmentation to prevent overfitting on our relatively small dataset. On each batch, the images are randomly cropped, rotated, flipped horizontally, and contrast jittered. Here is the result of our preprocessing and data augmentation:




CNN
The architectire of the final model that I chose consisted of six convolutional layers, three max-pool layers, and two fully connected layers. I used a 5x5 kernel, a stride of 1, and a 2x2 padding for the convolutional layers. I used mean squared error as the loss function, and used the Adam optimizer with a learning rate of 0.001. Here is a detailed overview of this network:
| Layer | Output Shape | Number of Parameters | |
|---|---|---|---|
| 1 | Conv2d-1 | [1, 8, 120, 160] | 208 |
| 2 | ReLU-2 | [1, 8, 120, 160] | 0 |
| 3 | MaxPool2d-3 | [1, 8, 60, 80] | 0 |
| 4 | Conv2d-4 | [1, 16, 60, 80] | 3,216 |
| 5 | ReLU-5 | [1, 16, 60, 80] | 0 |
| 6 | MaxPool2d-6 | [1, 16, 30, 40] | 0 |
| 7 | Conv2d-7 | [1, 32, 30, 40] | 12,832 |
| 8 | ReLU-8 | [1, 32, 30, 40] | 0 |
| 9 | MaxPool2d-9 | [1, 32, 15, 20] | 0 |
| 10 | Conv2d-10 | [1, 32, 15, 20] | 51,264 |
| 11 | ReLU-11 | [1, 32, 15, 20] | 0 |
| 12 | MaxPool2d-12 | [1, 32, 15, 20] | 0 |
| 13 | Conv2d-13 | [1, 64, 15, 20] | 112,070 |
| 14 | ReLU-14 | [1, 64, 15, 20] | 0 |
| 15 | Conv2d-15 | [1, 80, 15, 20] | 140,080 |
| 16 | ReLU-16 | [1, 80, 15, 20] | 0 |
| 17 | Linear-17 | [1, 1024] | 24,577,024 |
| 18 | ReLU-18 | [1, 1024] | 0 |
| 19 | Linear-19 | [1, 256] | 262,400 |
| 20 | ReLU-20 | [1, 256] | 0 |
| 21 | Linear-21 | [1, 116] | 29,812 |
Here is a graph of the training and validation losses over time:
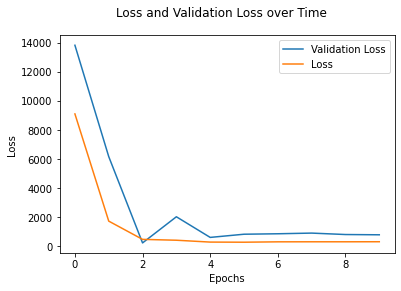
Results
For the following images, red dots represent acutal face points and blue dots represent the models's predictions of face points. Here are two images that the neural net worked well on:


Here are two images that the neural net does not work well on:


In the two failing cases, we can see that the subject's mouth is open. In the dataset, there are few entries where the subject's mouth is open, and we do not have any data augmentations that create an image of a subject with an open mouth. Therefore, the disparity between faces with mouths closed and faces with mouths open may be a reason for the model's inaccuracy.
Learned Filter Visualization
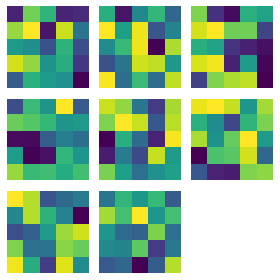
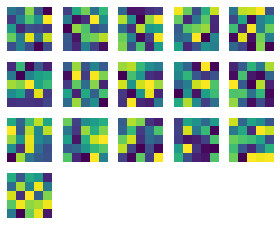
Part 3: Train with Larger Dataset
In this part of the project, we use the iBUG Face in the wild dataset as the basis for our neural network detector. This dataset contains 6666 images of varying image sizes, and each image has 68 annotated facial keypoints.
Dataloader
In the dataset, we are given bounding boxes for the faces, and keypoints for the entire image. We need to convert the coordinates relative to the bounding box that we are given, so that the points actually correspond with the cropped face. We then perform the same data augmentation techniques from the last part to prevent overfitting. I used 90% of the data as training data, and the remaining 10% as the validation set. Here are the results of our preprocessing:




CNN
For our CNN, we utilize a pretrained ResNet18 model with the first and last layer modified to take in a 224x224 image and output a vector of length 136, where each number in the vector corresponds to a predicted facial feature point. I then trained this model using mean squared error as the loss function for 20 epochs, using an Adam optimizer with a learning rate of 0.0001. With this setup, I managed to get a loss of 50.22934 in the Kaggle competition. Here is a detailed overview of our network:
| 1 | Conv2d-1 | [-1, 64, 112, 112] | 3,136 |
|---|---|---|---|
| 2 | BatchNorm2d-2 | [-1, 64, 112, 112] | 128 |
| 3 | ReLU-3 | [-1, 64, 112, 112] | 0 |
| 4 | MaxPool2d-4 | [-1, 64, 56, 56] | 0 |
| 5 | Conv2d-5 | [-1, 64, 56, 56] | 36,864 |
| 6 | BatchNorm2d-6 | [-1, 64, 56, 56] | 128 |
| 7 | ReLU-7 | [-1, 64, 56, 56] | 0 |
| 8 | Conv2d-8 | [-1, 64, 56, 56] | 36,864 |
| 9 | BatchNorm2d-9 | [-1, 64, 56, 56] | 128 |
| 10 | ReLU-10 | [-1, 64, 56, 56] | 0 |
| 11 | BasicBlock-11 | [-1, 64, 56, 56] | 0 |
| 12 | Conv2d-12 | [-1, 64, 56, 56] | 36,864 |
| 13 | BatchNorm2d-13 | [-1, 64, 56, 56] | 128 |
| 14 | ReLU-14 | [-1, 64, 56, 56] | 0 |
| 15 | Conv2d-15 | [-1, 64, 56, 56] | 36,864 |
| 16 | BatchNorm2d-16 | [-1, 64, 56, 56] | 128 |
| 17 | ReLU-17 | [-1, 64, 56, 56] | 0 |
| 18 | BasicBlock-18 | [-1, 64, 56, 56] | 0 |
| 19 | Conv2d-19 | [-1, 128, 28, 28] | 73,728 |
| 20 | BatchNorm2d-20 | [-1, 128, 28, 28] | 256 |
| 21 | ReLU-21 | [-1, 128, 28, 28] | 0 |
| 22 | Conv2d-22 | [-1, 128, 28, 28] | 147,456 |
| 23 | BatchNorm2d-23 | [-1, 128, 28, 28] | 256 |
| 24 | Conv2d-24 | [-1, 128, 28, 28] | 8,192 |
| 25 | BatchNorm2d-25 | [-1, 128, 28, 28] | 256 |
| 26 | ReLU-26 | [-1, 128, 28, 28] | 0 |
| 27 | BasicBlock-27 | [-1, 128, 28, 28] | 0 |
| 28 | Conv2d-28 | [-1, 128, 28, 28] | 147,456 |
| 29 | BatchNorm2d-29 | [-1, 128, 28, 28] | 256 |
| 30 | ReLU-30 | [-1, 128, 28, 28] | 0 |
| 31 | Conv2d-31 | [-1, 128, 28, 28] | 147,456 |
| 32 | BatchNorm2d-32 | [-1, 128, 28, 28] | 256 |
| 33 | ReLU-33 | [-1, 128, 28, 28] | 0 |
| 34 | BasicBlock-34 | [-1, 128, 28, 28] | 0 |
| 35 | Conv2d-35 | [-1, 256, 14, 14] | 294,912 |
| 36 | BatchNorm2d-36 | [-1, 256, 14, 14] | 512 |
| 37 | ReLU-37 | [-1, 256, 14, 14] | 0 |
| 38 | Conv2d-38 | [-1, 256, 14, 14] | 589,824 |
| 39 | BatchNorm2d-39 | [-1, 256, 14, 14] | 512 |
| 40 | Conv2d-40 | [-1, 256, 14, 14] | 32,768 |
| 41 | BatchNorm2d-41 | [-1, 256, 14, 14] | 512 |
| 42 | ReLU-42 | [-1, 256, 14, 14] | 0 |
| 43 | BasicBlock-43 | [-1, 256, 14, 14] | 0 |
| 44 | Conv2d-44 | [-1, 256, 14, 14] | 589,824 |
| 45 | BatchNorm2d-45 | [-1, 256, 14, 14] | 512 |
| 46 | ReLU-46 | [-1, 256, 14, 14] | 0 |
| 47 | Conv2d-47 | [-1, 256, 14, 14] | 589,824 |
| 48 | BatchNorm2d-48 | [-1, 256, 14, 14] | 512 |
| 49 | ReLU-49 | [-1, 256, 14, 14] | 0 |
| 50 | BasicBlock-50 | [-1, 256, 14, 14] | 0 |
| 52 | BatchNorm2d-52 | [-1, 512, 7, 7] | 1,024 |
| 53 | ReLU-53 | [-1, 512, 7, 7] | 0 |
| 55 | BatchNorm2d-55 | [-1, 512, 7, 7] | 1,024 |
| 56 | Conv2d-56 | [-1, 512, 7, 7] | 131,072 |
| 57 | BatchNorm2d-57 | [-1, 512, 7, 7] | 1,024 |
| 58 | ReLU-58 | [-1, 512, 7, 7] | 0 |
| 59 | BasicBlock-59 | [-1, 512, 7, 7] | 0 |
| 61 | BatchNorm2d-61 | [-1, 512, 7, 7] | 1,024 |
| 62 | ReLU-62 | [-1, 512, 7, 7] | 0 |
| 64 | BatchNorm2d-64 | [-1, 512, 7, 7] | 1,024 |
| 65 | ReLU-65 | [-1, 512, 7, 7] | 0 |
| 66 | BasicBlock-66 | [-1, 512, 7, 7] | 0 |
| 67 | AdaptiveAvgPool2d-67 | [-1, 512, 1, 1] | 0 |
| 68 | Linear-68 | [-1, 136] | 69,768 |
| 69 | ResNet-69 | [-1, 136] | 0 |
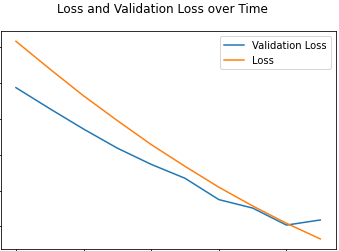
Here is the plot of our loss and validation loss over time:
Results
Here are some results on the testing set:




Here are the results on some of my own images:



Overall, the network does relatively well, however, it seems to struggle a little bit in detecting faces with glasses. The network also succeeds in excluding the hat in the third picture from facial points.