In this assignment, I used neural networks to automatically generate facial keypoints.
Here are some of the sampled images with the ground-truth points for the nose tip.



Each sample image was resized into 60px by 80px, and run through a network with the following neural network:
Net(
(conv1): Conv2d(1, 32, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1))
(conv3): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=480, out_features=240, bias=True)
(fc2): Linear(in_features=240, out_features=2, bias=True)
)
Each convolutional layer had a ReLU and Maxpool with width 2 applied after it. There was also a ReLU operation applied between the first and second fully connected layers.
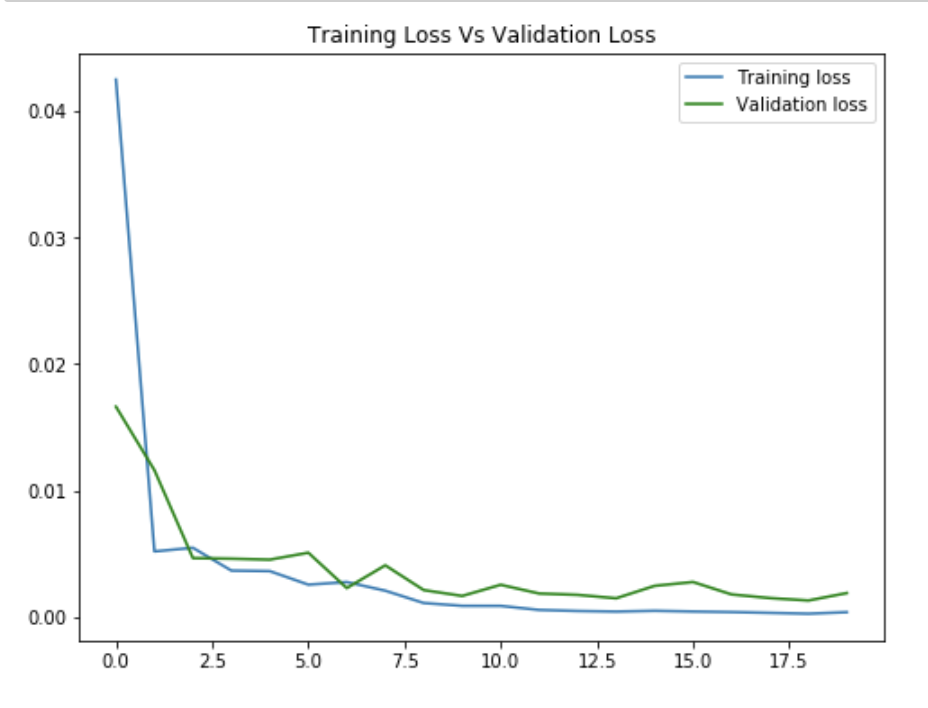
Here's my training and validation loss over 20 epochs. The validation loss was initially much lower for the first epoch because I calculated it after the network had been trained on the first epoch of the training data.
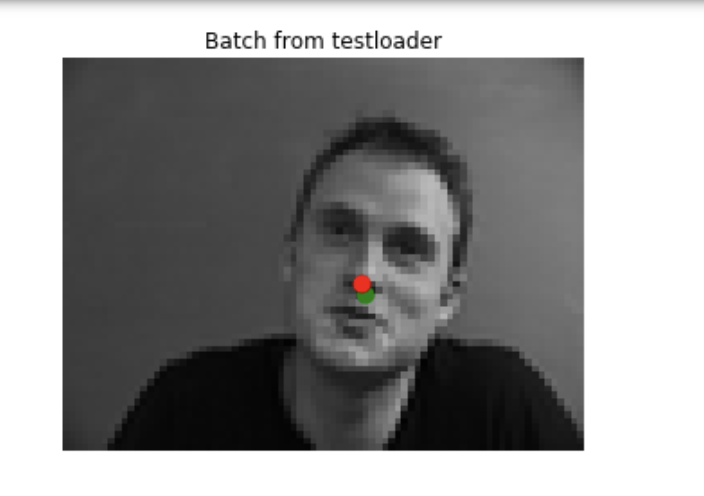
Here are some images (mostly from the validation set) that had good results. The ground-truth point is in green, and the generated point is in red. The images that had good results generally had noses that were very centered in the frame, and often looking straight ahead or only slightly turned.



Here are some images that had bad results. The ground-truth point is in green, and the generated point is in red. These images likely had bad predictions because the faces were very turned (something the network didn't have much data on), positioned off center within the frame, or looking up or down.



I tried changing the filter size and number of channels from the above model to see how it would affect the results.
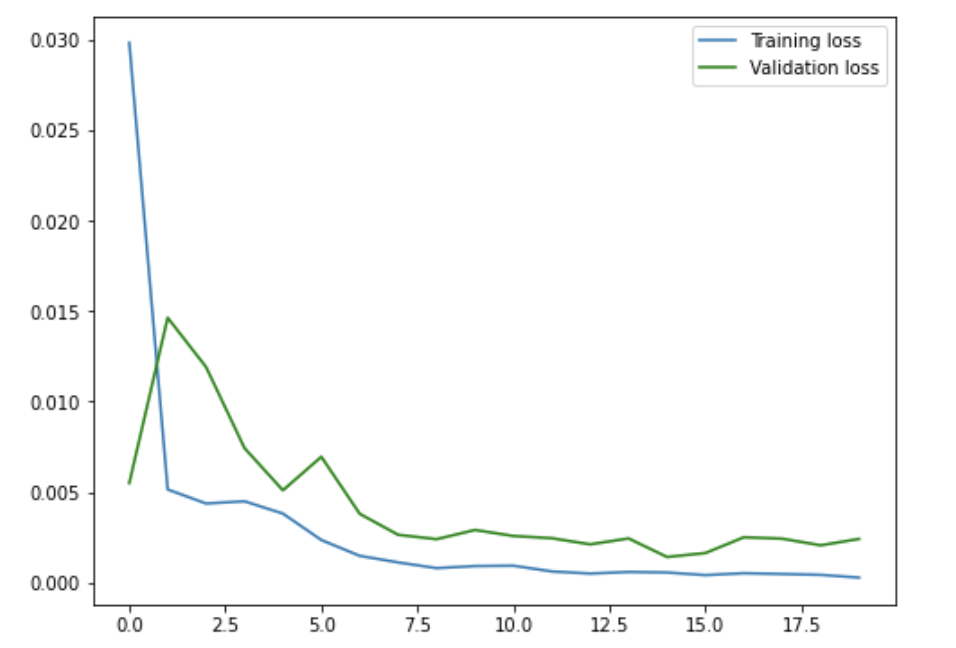
For the first change, I changed all of the kernel sizes in the convolutional layers to be 3x3. I then compared the results for the "good" images above.
Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=1280, out_features=240, bias=True)
(fc2): Linear(in_features=240, out_features=2, bias=True)
)




Reducing the kernel sizes definitely had an adverse effect on my results, especially on the images where the subject wasn't facing directly forward.
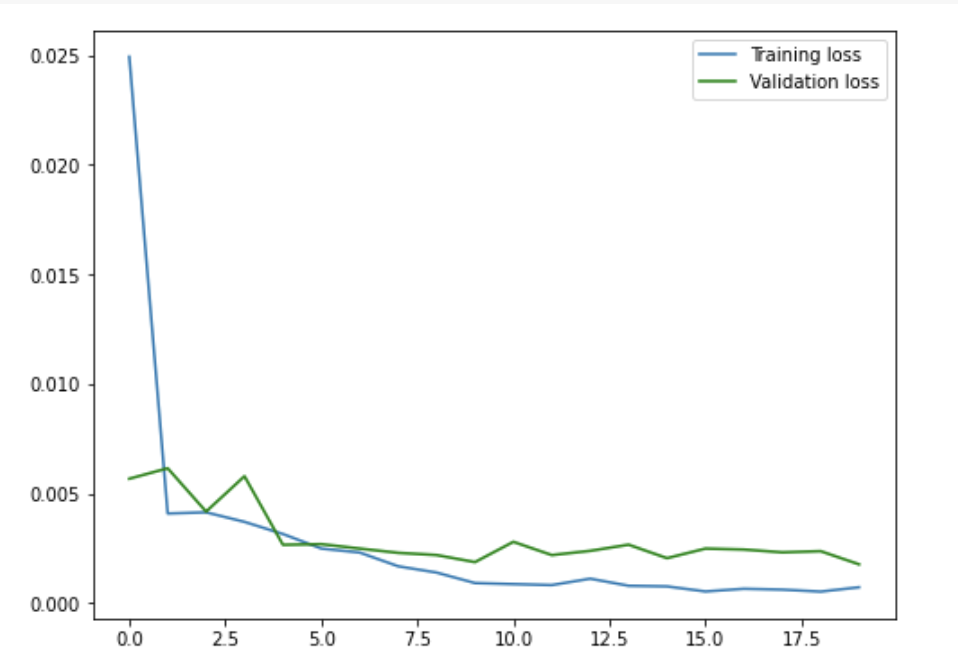
For the second change, I reduced the number of channels to 16 instead. While this did speed up the training period, it had a negative effect on my loss and overall prediction accuracy. I also compared the results to the previous "good" images.
Net(
(conv1): Conv2d(1, 16, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(16, 16, kernel_size=(7, 7), stride=(1, 1))
(conv3): Conv2d(16, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=240, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=2, bias=True)
)




Reducing the number of channels definitely had an adverse effect on the accuracy of my results, especially on the images where the subject wasn't facing directly forward. The image facing directly forward returned a similar result as the non-modified model. For the images facing slightly to the side, it seems like the predictions shifted upward relative to the ground-truth annotations.
This time we tried to predict all the facial keypoints based on the Danish computer scientists set.
Here are some of the ground truth images.



However, since the dataset was quite small, I performed some data augmentation. This included randomly cropping the image by up to 10 pixels in either dimention, rotating the image by a random amount between -10 and +10 degrees around the center, and varying the brightness of the image randomly. Below are what some of the augmented images looked like.



FaceNet(
(conv1): Conv2d(1, 65, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(65, 65, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(65, 65, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(65, 65, kernel_size=(3, 3), stride=(1, 1))
(conv5): Conv2d(65, 65, kernel_size=(3, 3), stride=(1, 1))
(conv6): Conv2d(65, 65, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=195, out_features=2000, bias=True)
(fc2): Linear(in_features=2000, out_features=300, bias=True)
(fc3): Linear(in_features=300, out_features=116, bias=True)
)
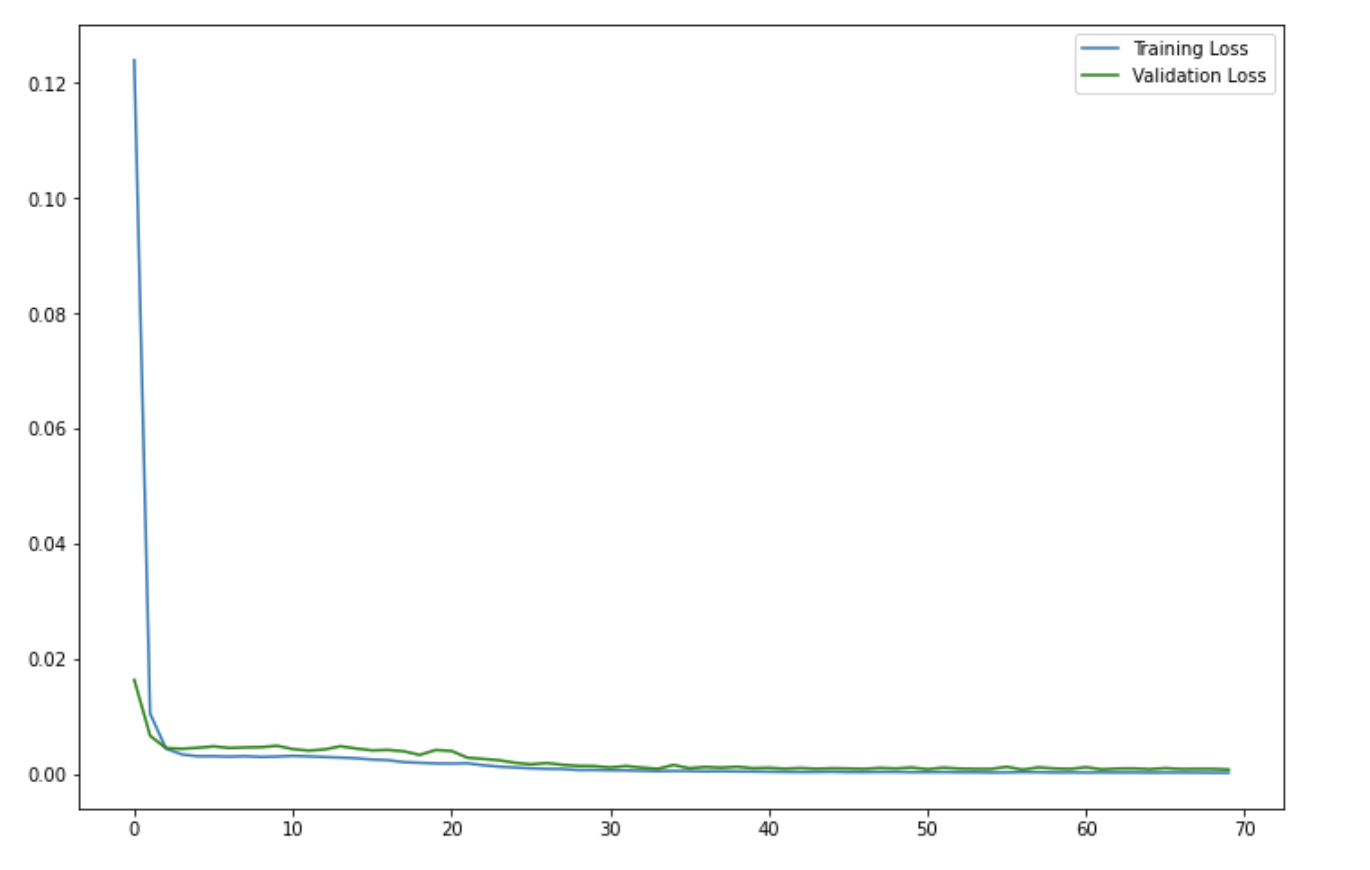
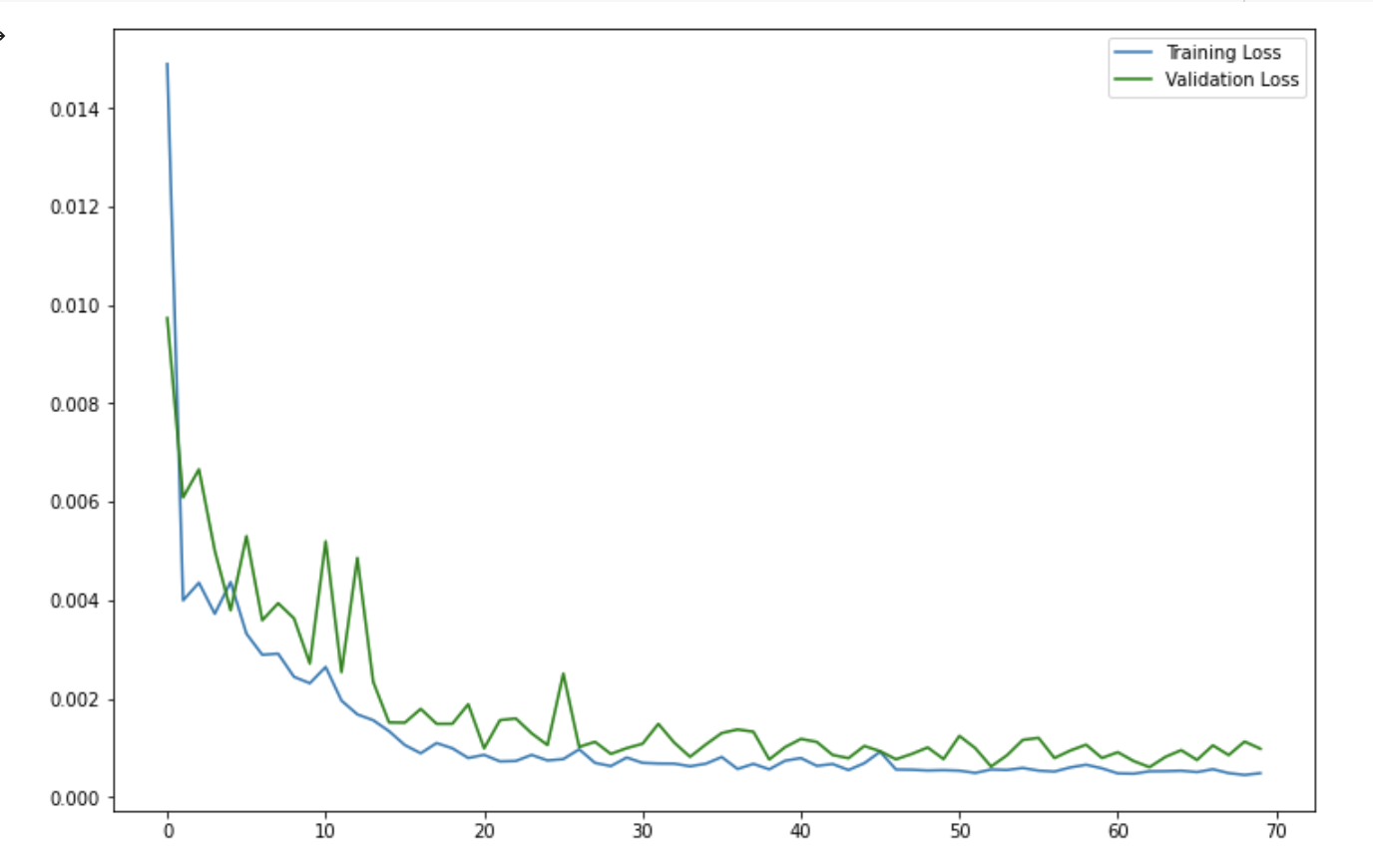
I also viewed the graph without that first error point to see the lines in more detail. The total loss ended up under 0.001 after 70 epochs.
Here are some of the good results on the validation set. The images with good results generally had the people centered in the image, and mostly facing forward while making a neutral expression.



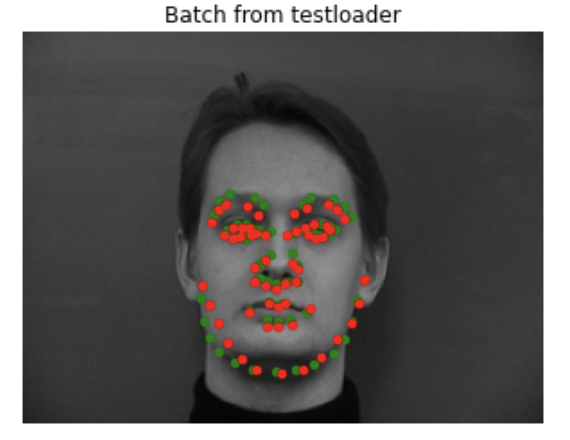

Here are some of the bad results on the validation set. The images with bad results generally had the people not centered in the image, or making odd expressions. This is probably because the model didn't have many examples of off centered images or non-neutral expressions in the training set, so the model doesn't really know how to handle them.




There is a noticable shift in the first two images, probably because the person is not centered in frame or is not looking directly at the camera. As seen in the second and third images, the model didn't really know how to deal with non-neutral/slight smile expression. but it's shifted. In the fourth image the predicted shape is facing the wrong direction for some reason-- perhaps because the person is situated closer to the left side of the page.
I visualized all of the 3x3 convolutional filter weights from the first layer. Since there were 65 output channels, there were 65 filters, as shown here.

I scored a high score of 10.69133 overall in the Kaggle competition.

I used the pre-trained Resnet18 (click to see all the layers in the network) model as a base. I changed the final fully connected layer to have 136 outputs (corresponding with the 136 coordinates we need). I actually chose to train on colored images, so I did not need to make things grayscale as in Part 2. I trained the model in batches of 100 for 20 epochs.
Reference: ResNet18
For data augmentation, I used the same techniques as before, such as randomly cropping the images by +- 10 pixels in either dimension, randomly rotating by +- 10 degrees in either direction, as well as randomly varying color brightness (brightness = .1) and saturation (saturation = .1)
I also had to normalize my inputs because I was using the pretrained models. I normalized each image using the following values:>
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), which was given in the documentation for the PyTorch models.




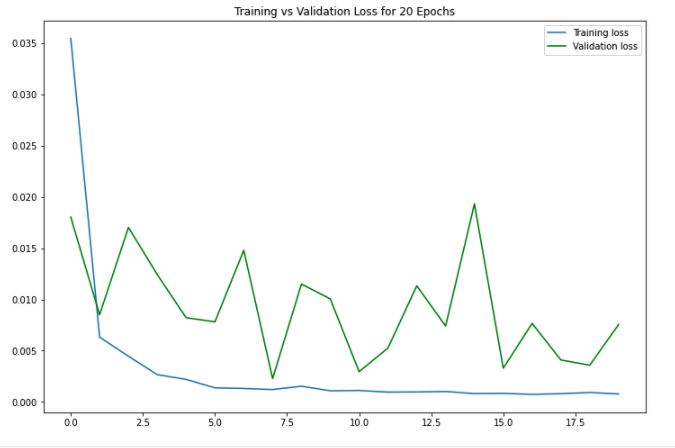
Here is the loss for both the training set and validation set over 20 epochs. The training loss steadily decreased, but the validation loss was very eratic.
Here are some of the results on the test set that turned out well:




Here are some of the results on the test set that didn't turn out so well:




Images that seemed to do poorly included images of people with beards (since it obscures the chin), images where the face is partially hidden (like image 2 and 3), or images where the subject's expression is very exaggerated, like the tongue out of mouth expression in the last photo.
Here are some of my own images that turned out well:

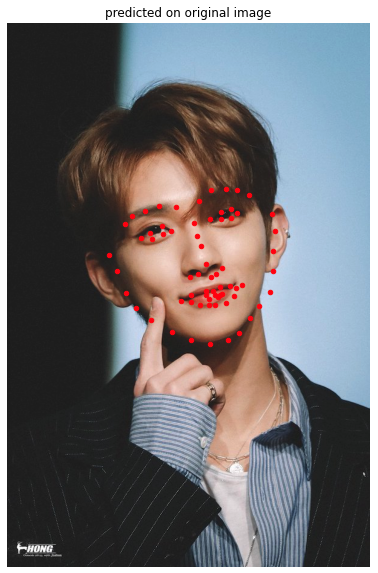

Here are some of my own images that didn't turn out so well:

There's a couple things wrong with these points-- firstly, it seems like the model mixed up his glasses and his eyes. Secondly, although the right side of his face looks fine, his left side is completely off of his face. This is probably because we don't have too many faces that are turned to such a sharp angle to the side in the training set. In addition, the model probably mixed up the edge of his glasses and the edge of his face
This part of the project was also super cool! I think it broke my computer though :( I ran out of GPU in colab so many times OTL