Overview
First, we have a dataloader that loads images and corresponding information associated with the image, such as true keypoints. Then use CNN torch model and MSE loss function to train the model.
Nose Tip Detection
These are some sampled image from the face dataloader, with true nose keypoints marked in red.

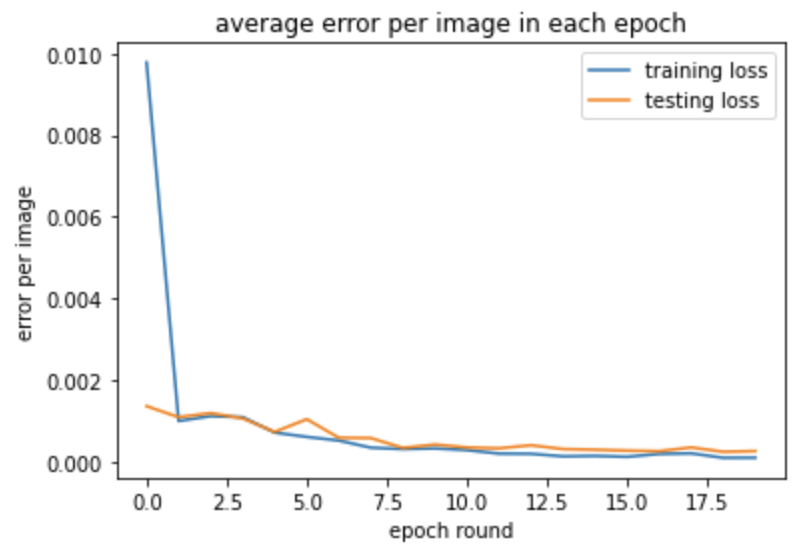
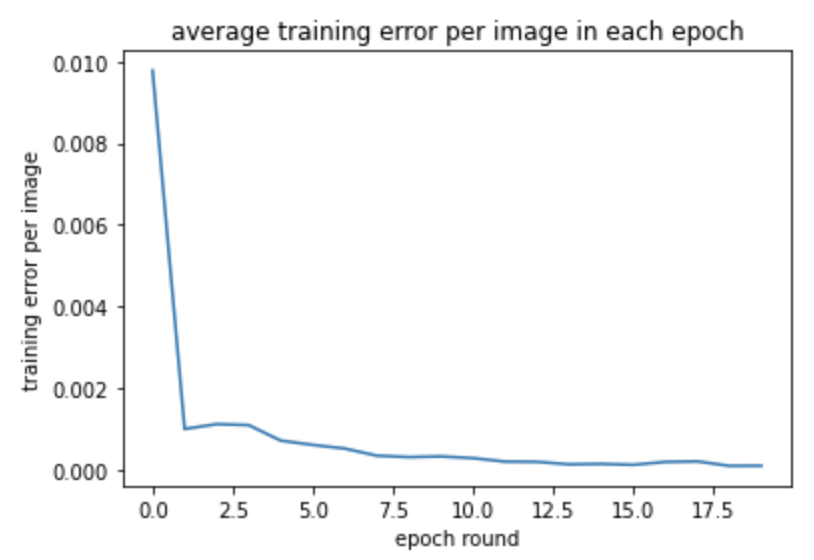
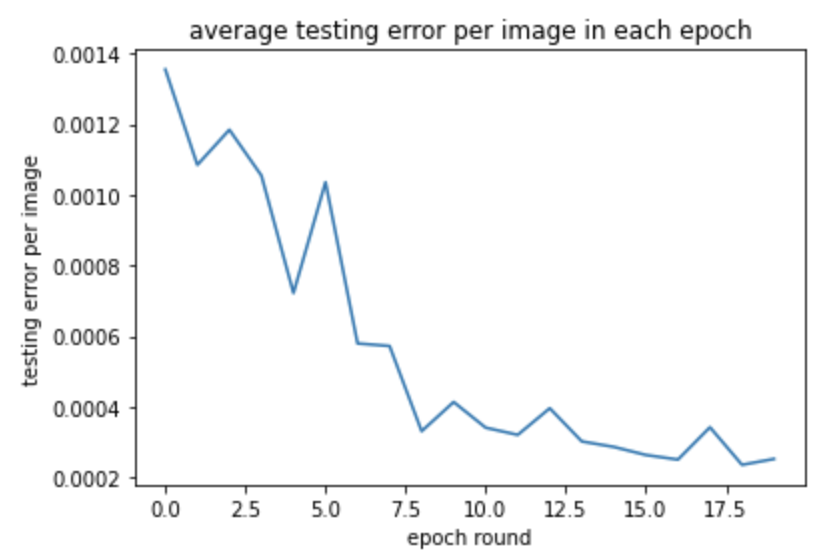
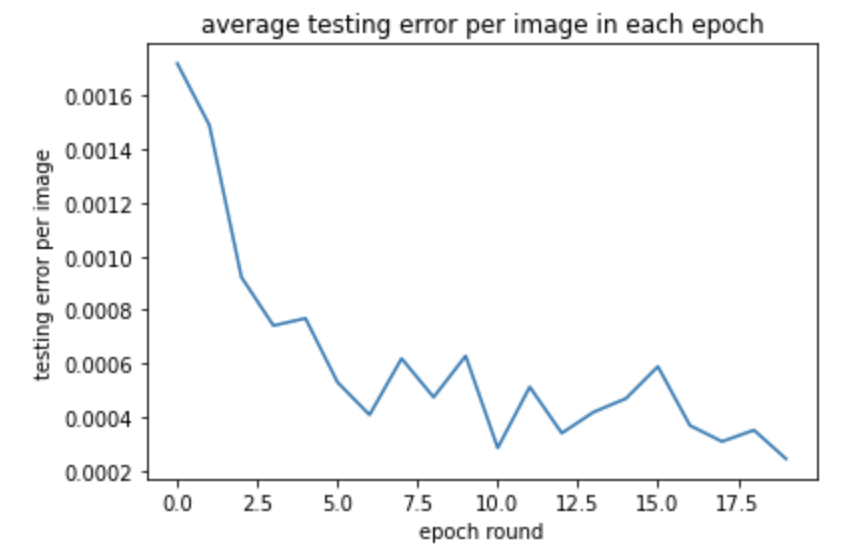
These are graphs of training and testing MSE Loss during the training process of 20 epoches. The model have 3 layers with max pooling after every convolution. The first convolution have 12 output channels and a 7x7 square convolution kernel. The second have 12 input image channel, 18 output channels, and 5x5 square convolution kernel. The third have 18 input, 24 output and kernel size 3x3.
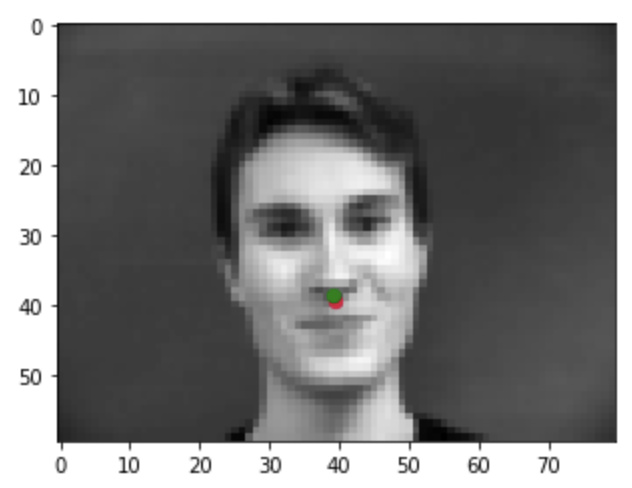
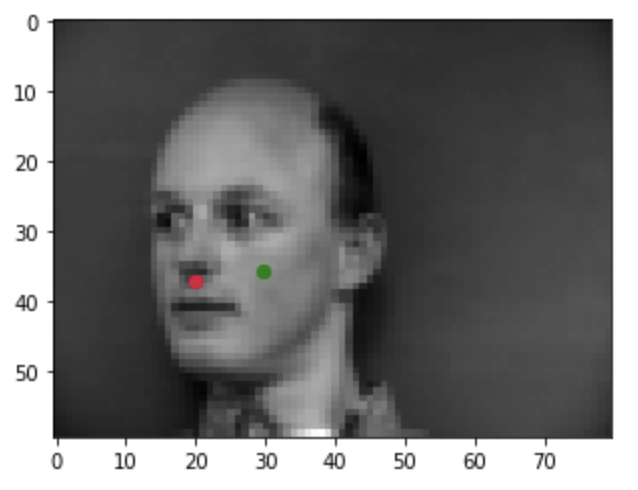
These are graphs overview of how the model works at predicting the nose tip. True nose tip is marked in green and learned nose tip is red.

Correct nose detection:


Incorrect nose detection:


Images where the model make incorrection detection generally have larger facial expression and have higher and clearer cheeks. When nose tips is not the only obvious bumps in the face, the detection is easily wrong, such as consider cheek as nose.
When try to tune with the hyperparameters:
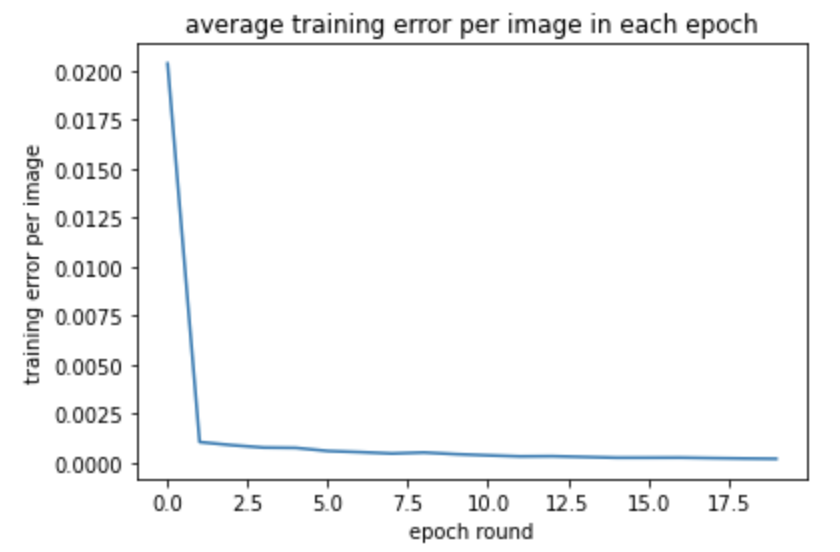
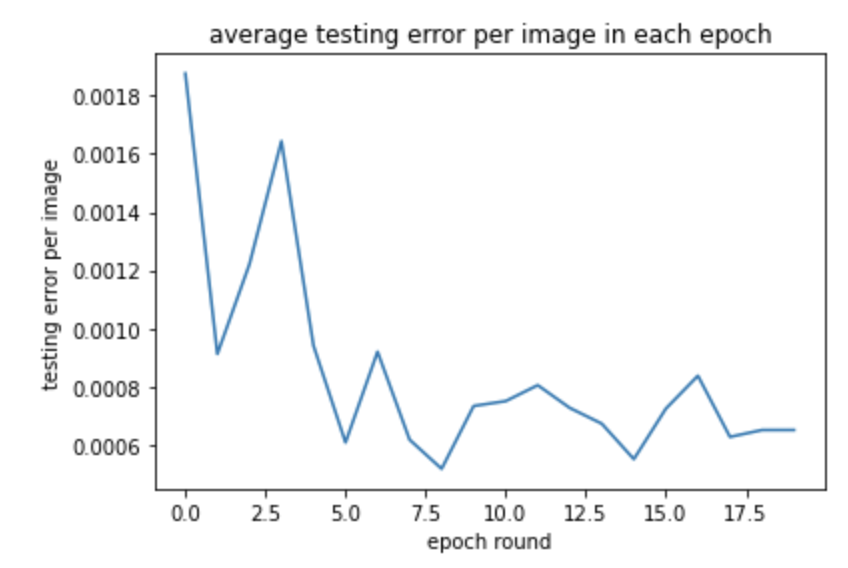
When I try to add one more layer to 4 convolution layers in total, the result of one more layers makes the detection worse. The training loss and testing loss are shown below:
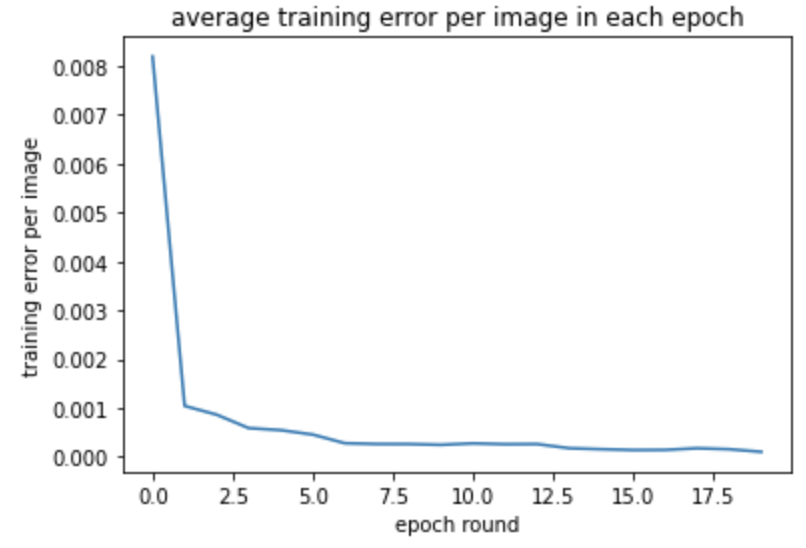
When I try to change the kernel size of first convolution from 7 to 5, the result doesn't change much. The training loss and testing loss are shown below:
Full Facial Keypoints Detection
To avoid overfitting, we use data augmentation. After apply rotation between degree -15 and 15 and some random brightness changes, some sampled images with true facial keypoints are shown below.
|
|
|
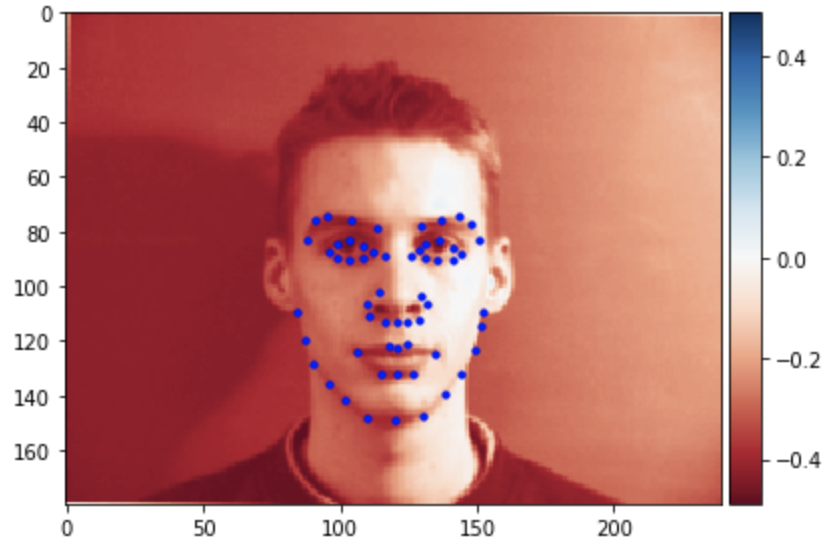
|
The model have 5 convolution layers and 2 linear fully connect layers.
The first convolution layer has 1 input channel, 12 output channels, and kernel size 7x7. The first convolution is followed by a ReLu and no max pooling.
The second convolution has 12 inputs channels, 16 output channels, and kernel size 5x5, followed by a ReLu and a max pooling layers of size 2 and step size 2.
The third convolution has 16 input channels, 20 output channels, and kernel size 3x3, followed by a ReLu and a max pooling layer of size 2 and step 2.
The third convolution has 20 input channels, 24 output channels, and kernel size 3x3, followed by a ReLu and a max pooling layer of size 2 and step 2.
The third convolution has 24 input channels, 30 output channels, and kernel size 3x3, followed by a ReLu and a max pooling layer of size 2 and step 2.
Then linear fully connect layer of input 2880, output 600, followed by a ReLu;
Then linear fully connect layer of input 600, output 136
The training and testing loss are shown below:
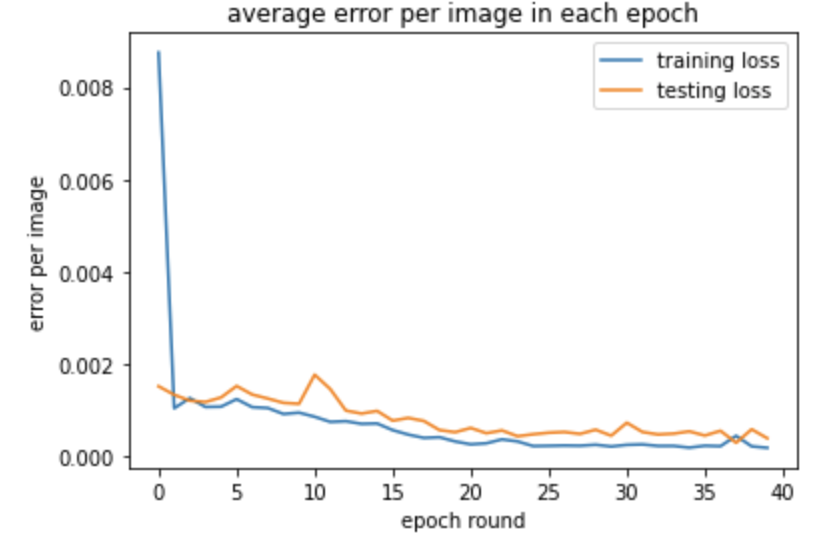
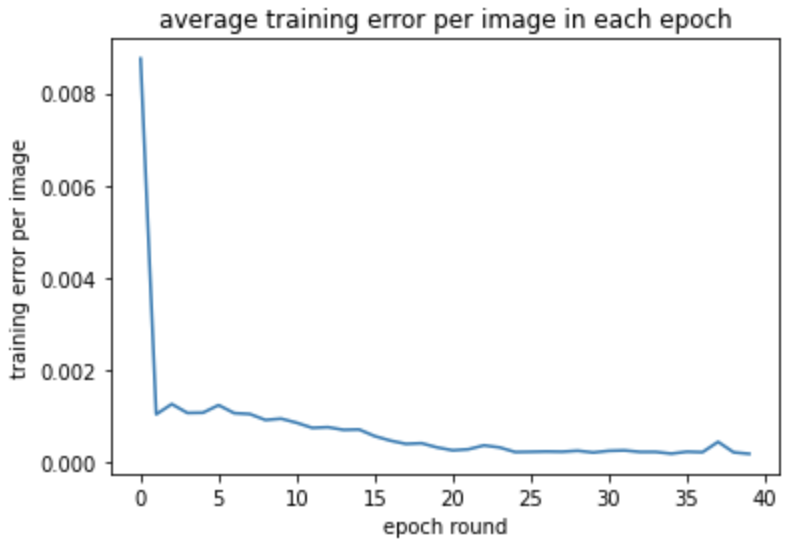
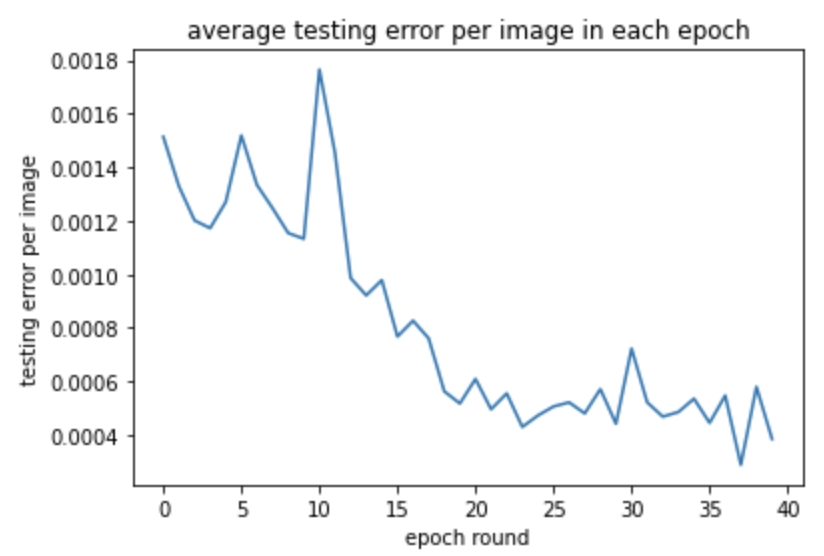
Some detection results are shown below, true keypoints mark in green, detected keypoints mark in red.
Almost correct detection:
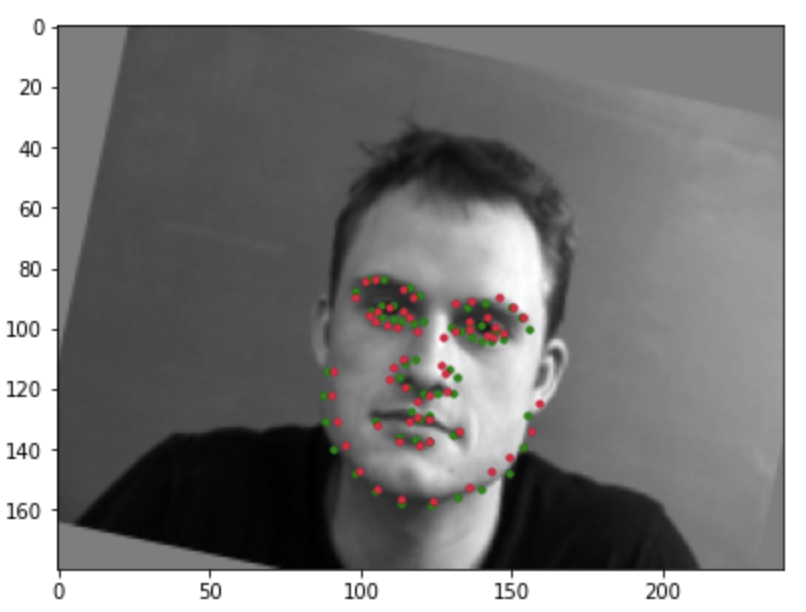
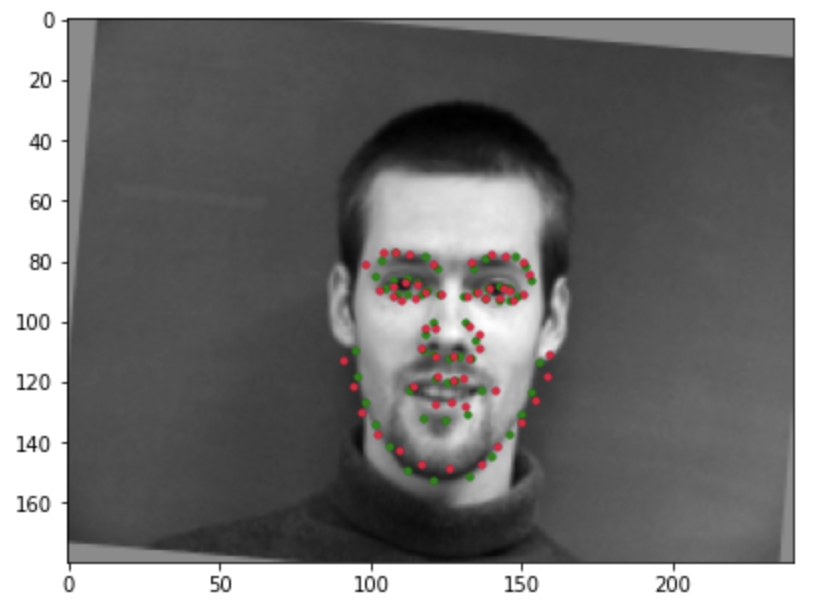
Incorrect detection:
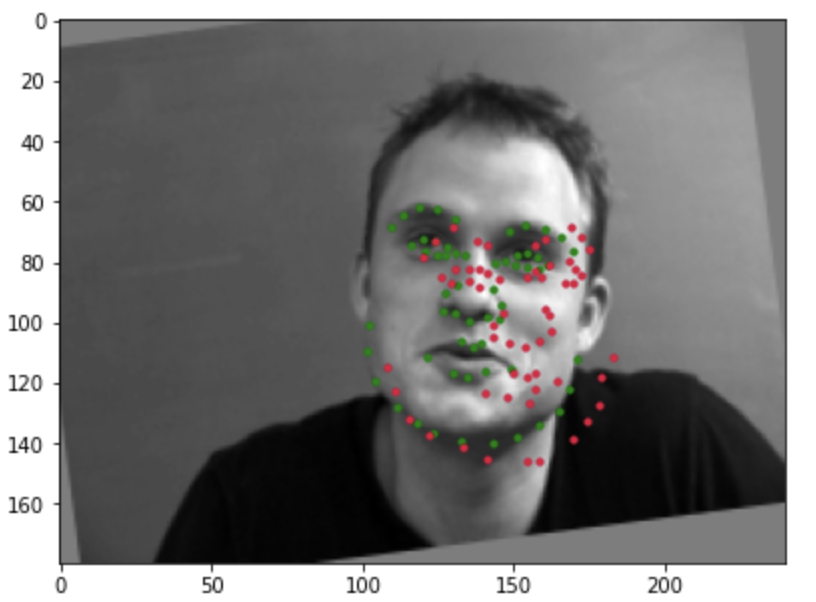
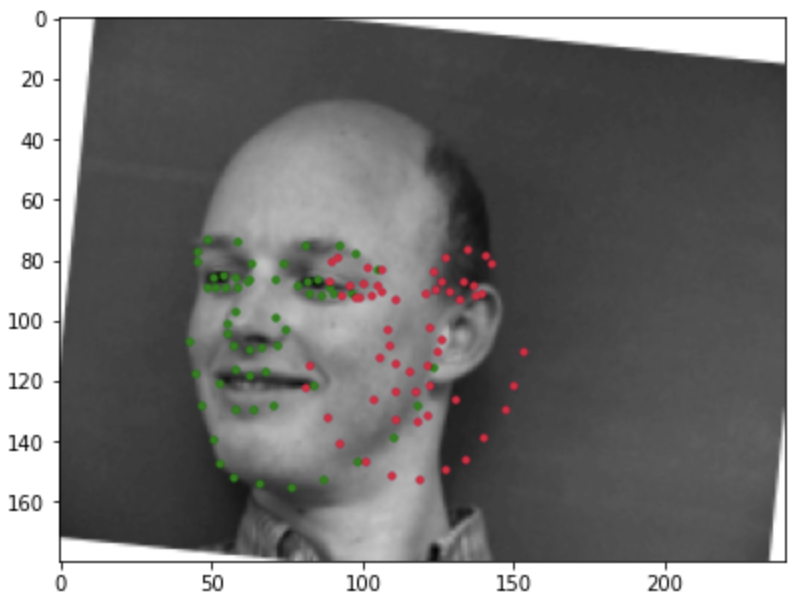
Images where the model make incorrection detection generally have large extent of face turning to one side or rotation from data augmentation. Run the training process the second time without re-initialize the model give better results.
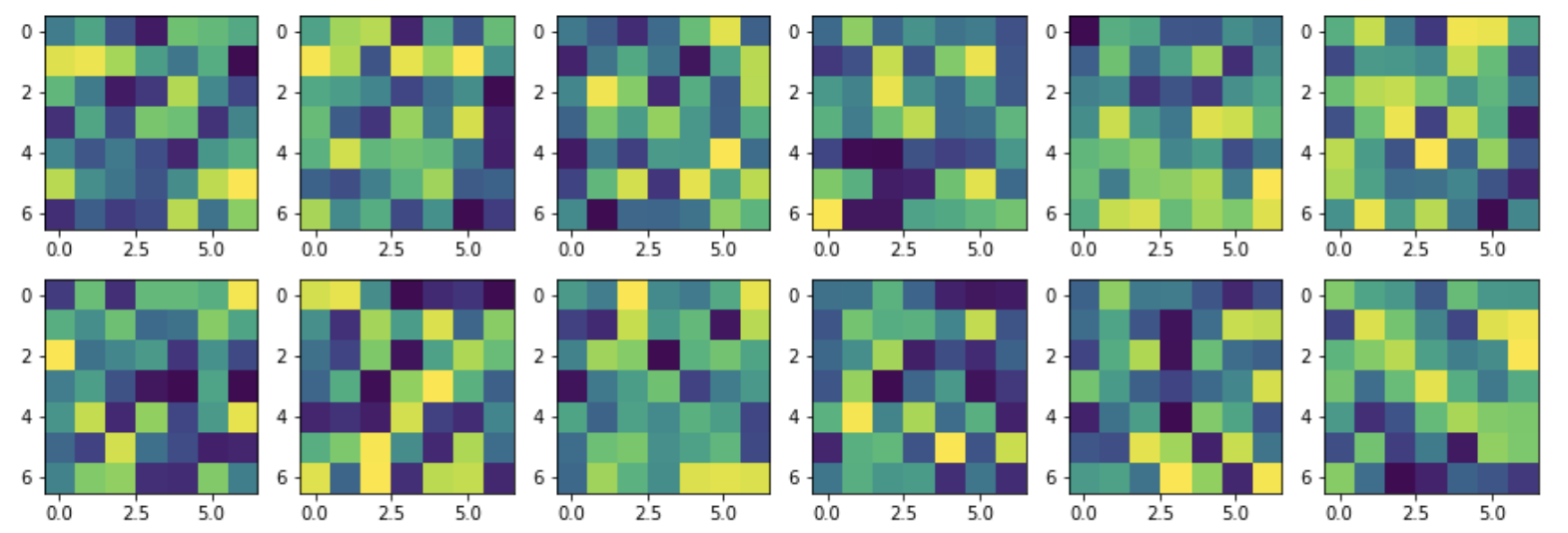
These are the visualized filter of first layer of convolution:
Train With Larger Dataset
Mean absolute error report from kaggle is 8.77859

Here I use standard CNN model resnet18, and change input channel of first convolution to 1, and output channel of final fully connect layer to 136.
The model have 5 convolution layers(The first convolution has 1 layers, rest convolution have 2 basic block and each basic block has 2 convolution, so 4 convolution layer each) and 1 linear fully connect layers. In total 1+4x4+1=18 layers.
The first convolution layer has 1 input channel, 64 output channels, and kernel size 7x7, stride size 2x2.
ReLu;
Max pooling, kernel size 3, stride size 2;
Layer 1:
convolution, 64 input channels, 64 output channels, kernel size 3x3;
bottle neck;
ReLu;
convolution, 64 input channels, 64 output channels, kernel size 3x3;
bottle neck;
convolution, 64 input channels, 64 output channels, kernel size 3x3;
bottle neck;
ReLu;
convolution, 64 input channels, 64 output channels, kernel size 3x3;
bottle neck;
Layer 2:
convolution, 64 input channels, 128 output channels, kernel size 3x3, stride size 2;
bottle neck;
ReLu;
convolution, 128 input channels, 128 output channels, kernel size 3x3;
bottle neck;
downsample; Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
convolution, 128 input channels, 128 output channels, kernel size 3x3;
bottle neck;
ReLu;
convolution, 128 input channels, 128 output channels, kernel size 3x3;
bottle neck;
Layer 3:
convolution, 128 input channels, 256 output channels, kernel size 3x3, stride size 2;
bottle neck;
ReLu;
convolution, 256 input channels, 256 output channels, kernel size 3x3;
bottle neck;
downsample; Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
convolution, 256 input channels, 256 output channels, kernel size 3x3;
bottle neck;
ReLu;
convolution, 256 input channels, 256 output channels, kernel size 3x3;
bottle neck;
Layer 4:
convolution, 256 input channels, 512 output channels, kernel size 3x3, stride size 2;
bottle neck;
ReLu;
convolution, 512 input channels, 512 output channels, kernel size 3x3;
bottle neck;
downsample; Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
convolution, 512 input channels, 512 output channels, kernel size 3x3;
bottle neck;
ReLu;
convolution, 512 input channels, 512 output channels, kernel size 3x3;
bottle neck;
Average pooling;
Fully connected layer, 512 input, 136 output.
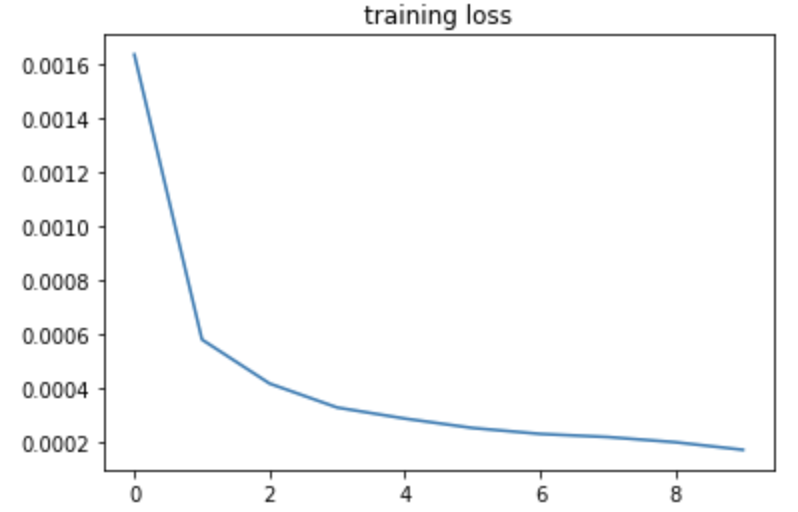
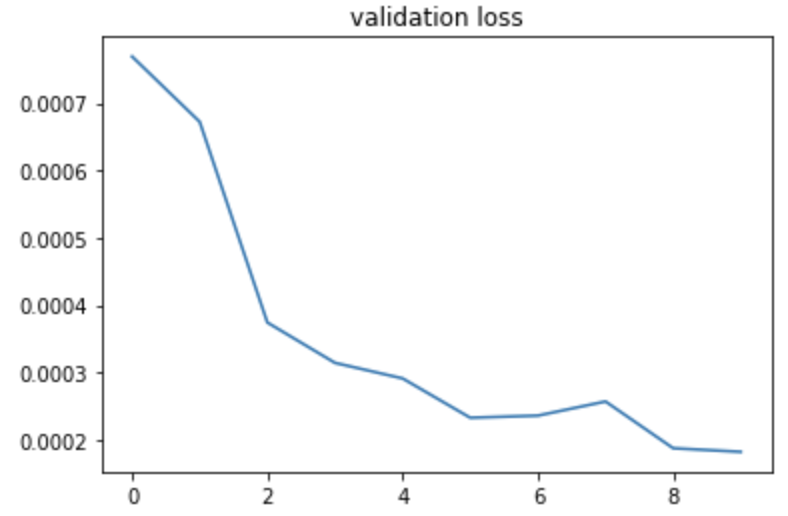
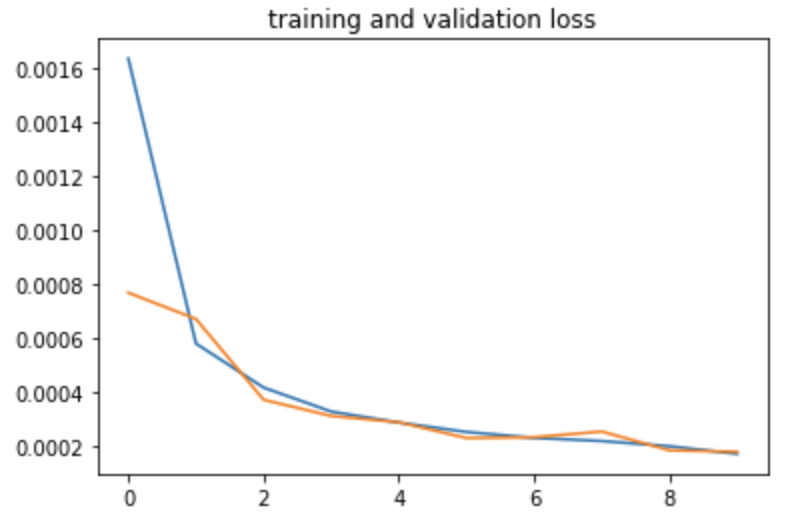
Following are the training error and validation error when split 30% of the data to be validation set.
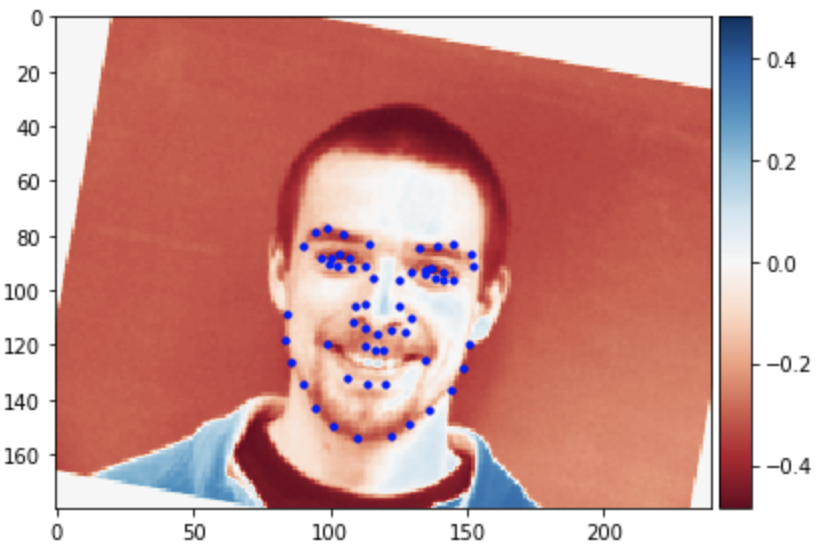
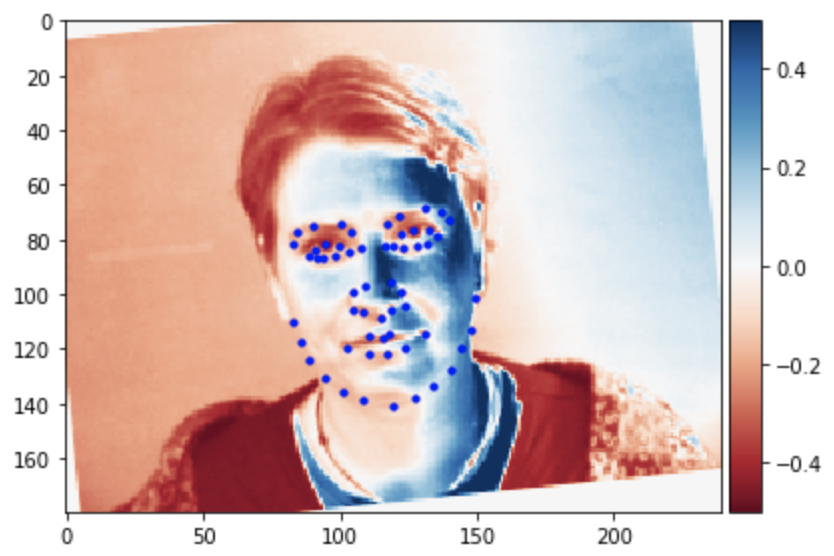
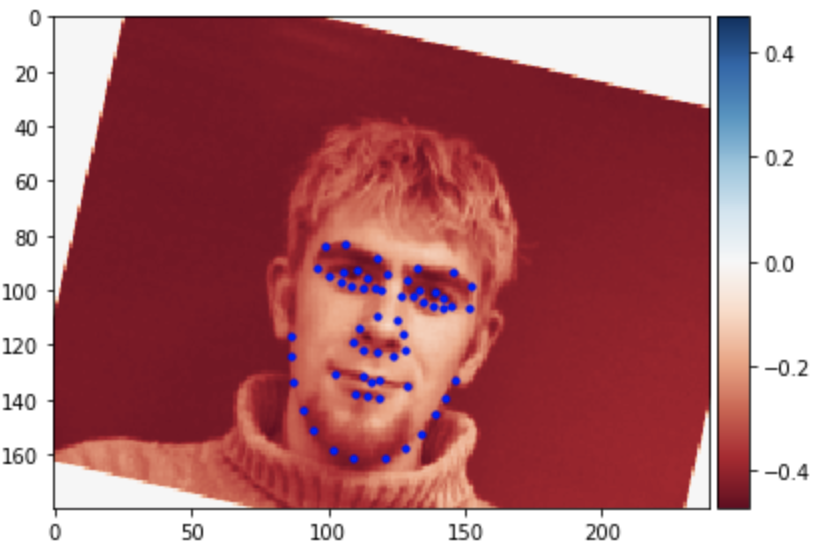
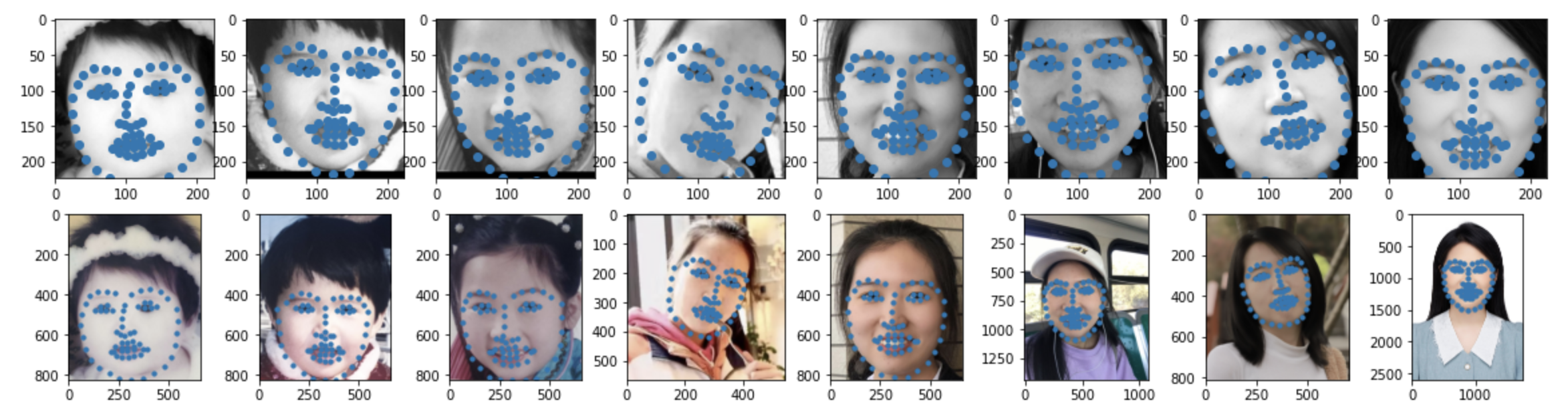
Some images with predicted keypoints from test dataset are shown below:
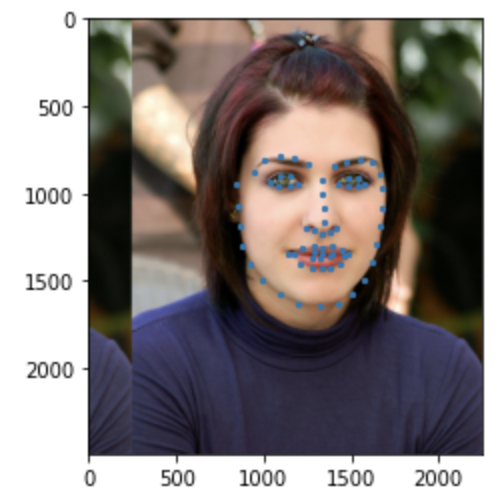
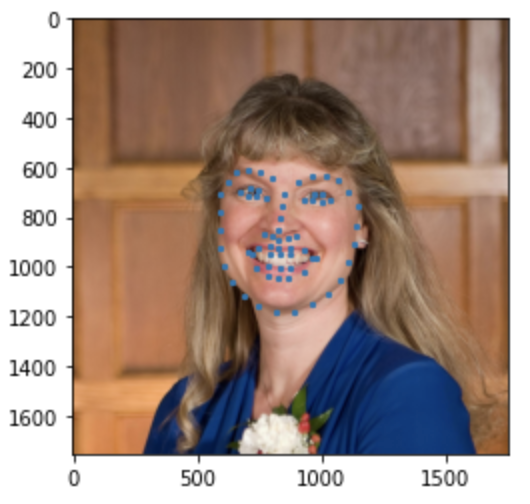

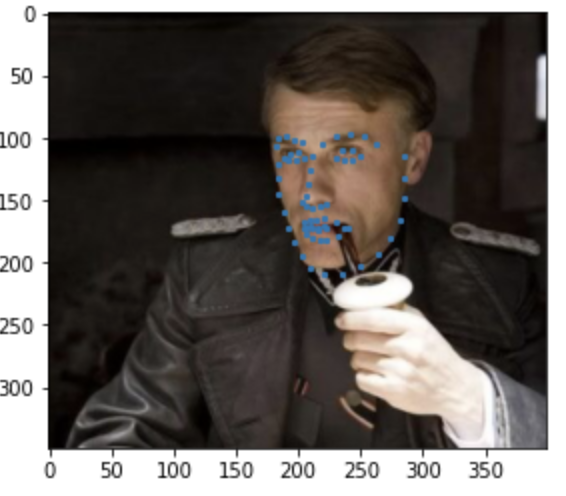
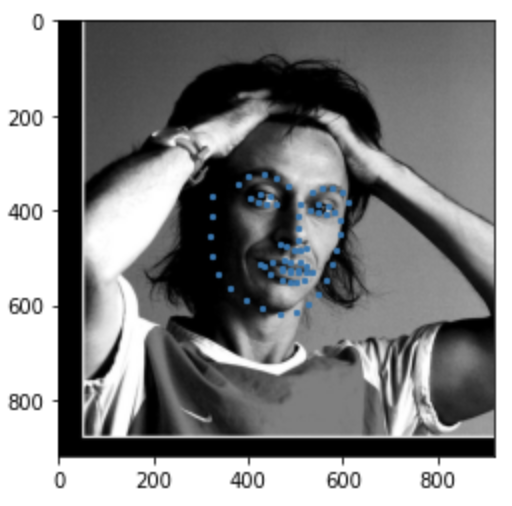
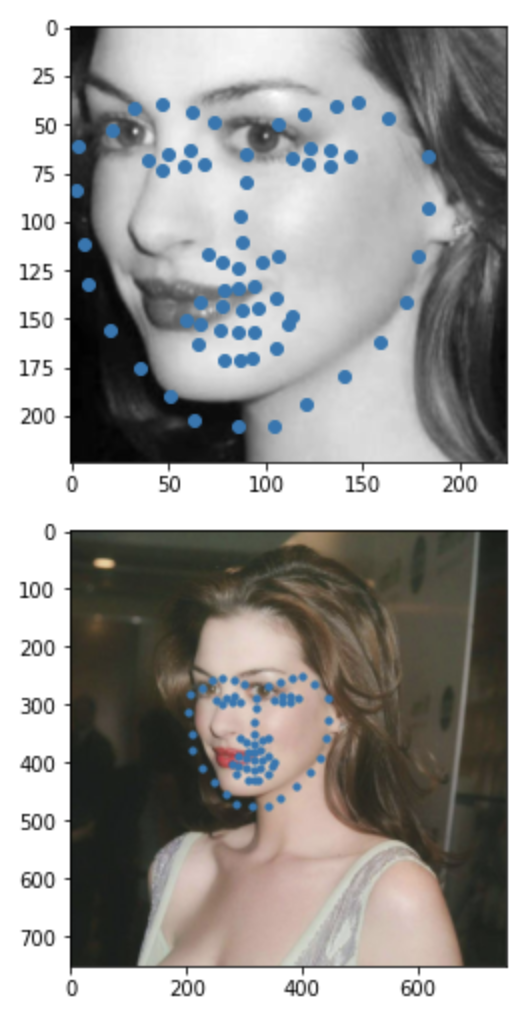
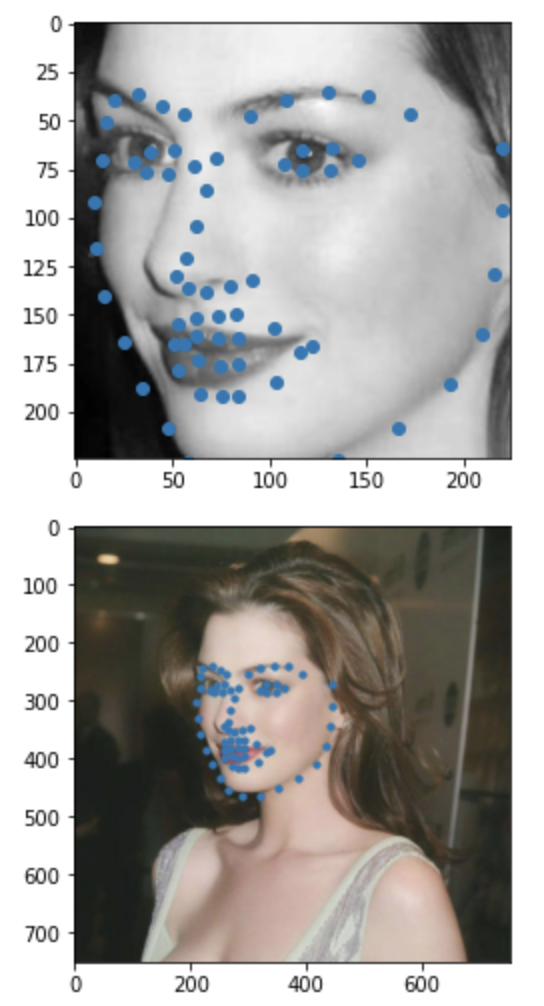
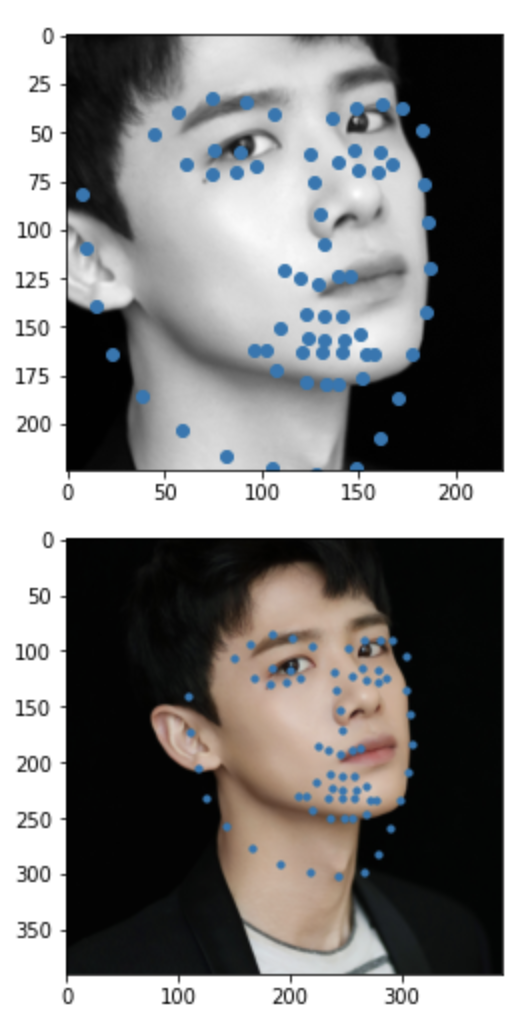
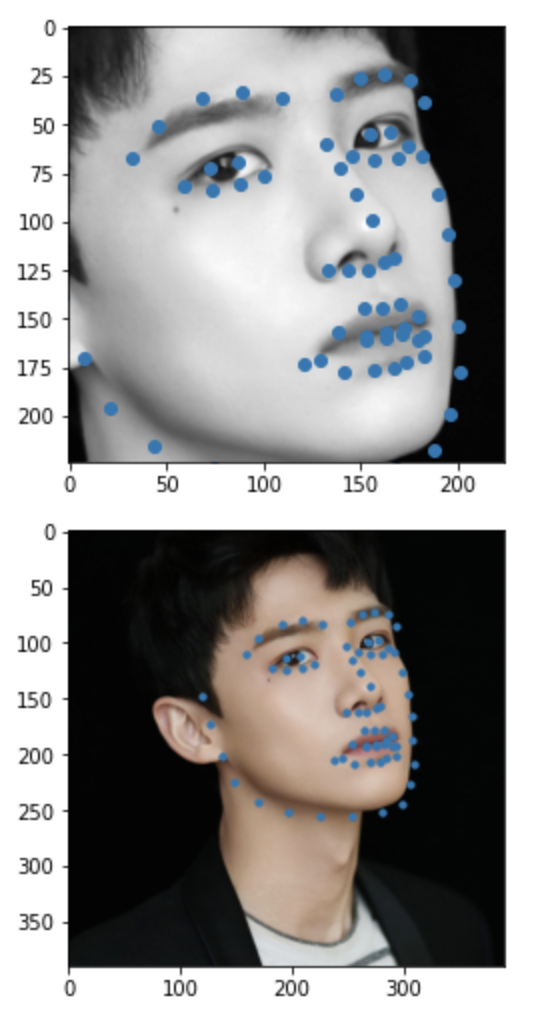
Some images with predicted keypoints from my face photo collection are shown below:
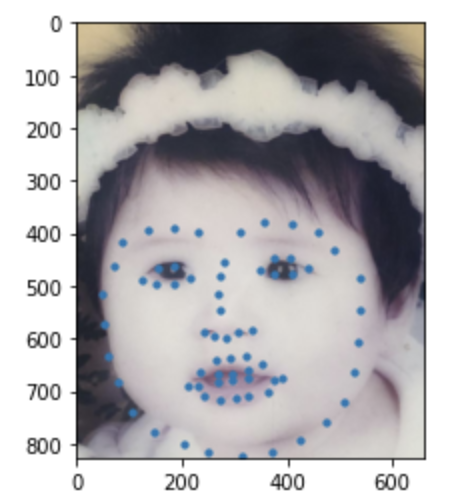
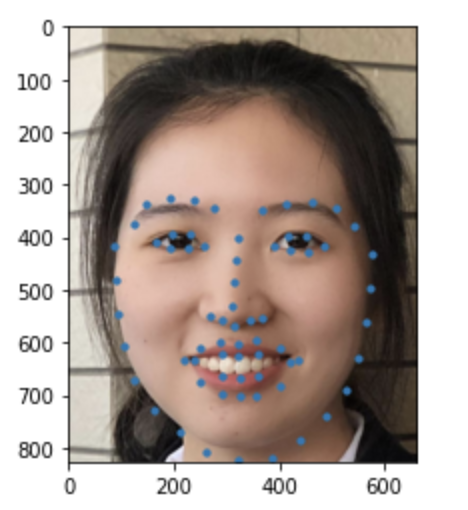
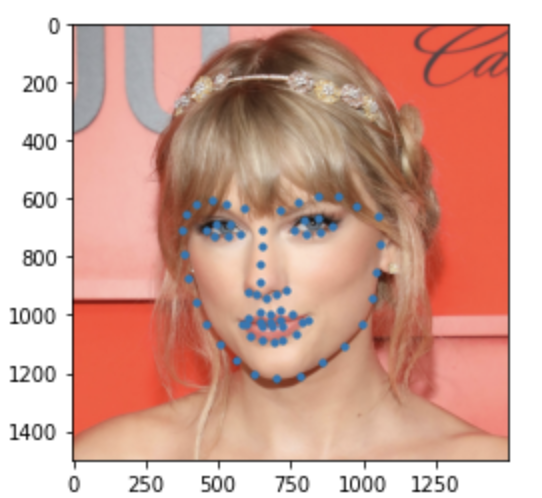

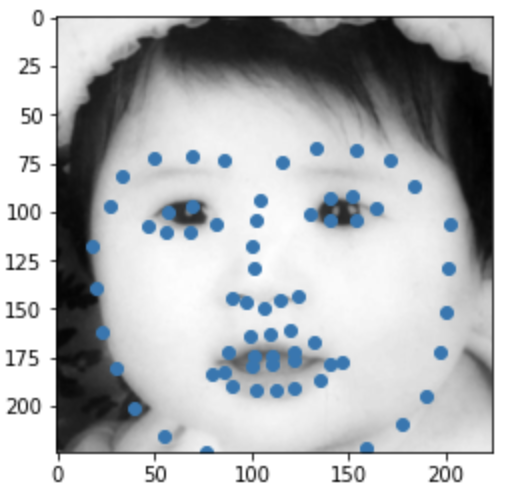
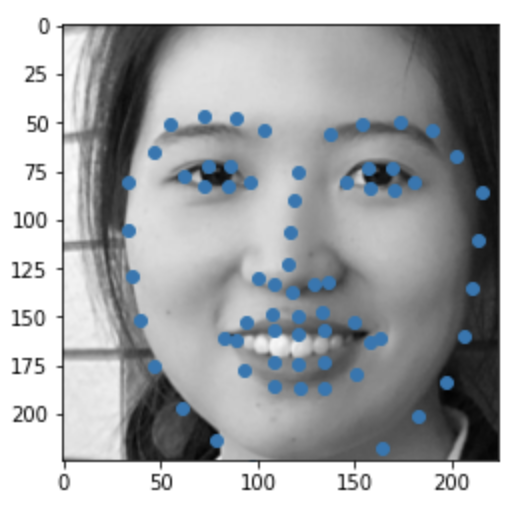
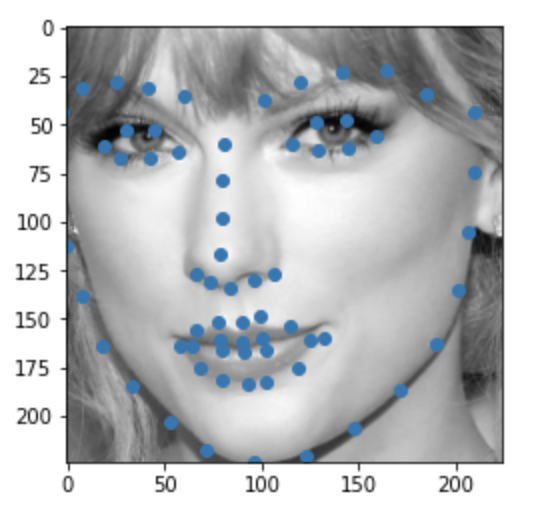
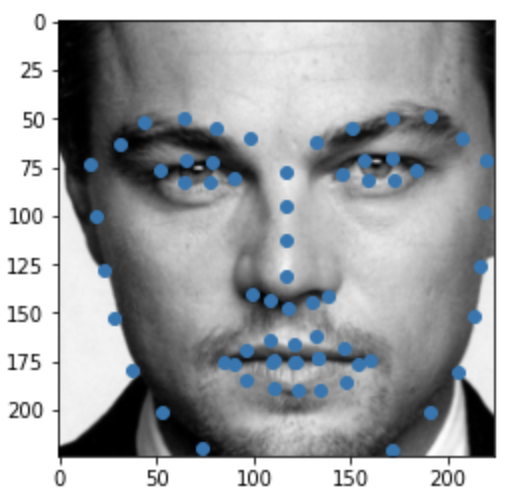
The prediction generally performs very well. For the first two photos, the predicted contour of the jaw is a little bit off. The prediction on first, the infant photo is the worst of the four, make slightly off prediction on face contour and eyebrow place, probably due to over brightness of the photo.
Also, I found that changes of the crop box greatly impact how good the prediction is.
|
|
|
|
Bells & Whistles
Then I tried to combine the facial keypoints detector with the face morphing in project 3. First give reasonable bboxes for all images, and run model on them, get following prediction:
Then recrop the original images to get RGB-colored cropped image with face in middle. And make changes to the keypoints correspondingly

Then use project 3 code and generate the following results:

