Part 1: Nost Tip Detection
Here are the two sampled image from my dataloader visualized with ground-truth keypoints.
|

|
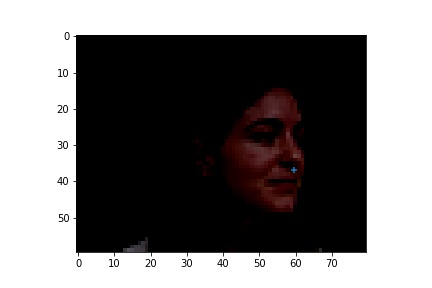
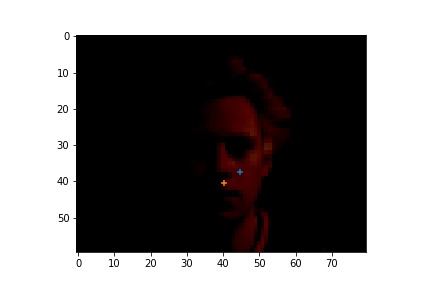
Cases where the classifier detects wrong nose points. I noticed that they have one feature in common that the classifier classifies the nose tip to be on the side of the ala. I think the major problem here is we don't have enough training data to train the classifier to distinguish between the side of ala has some similarities as the nose tip since they do have similarities.
|
|
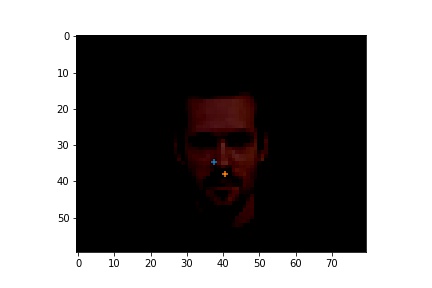
Here are the cases where the classifier did a good job.
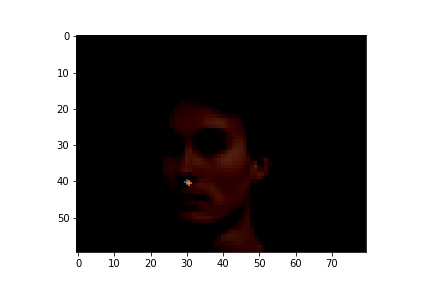
|
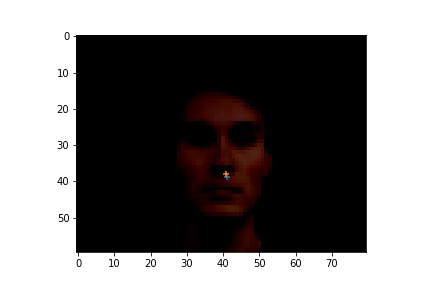
|
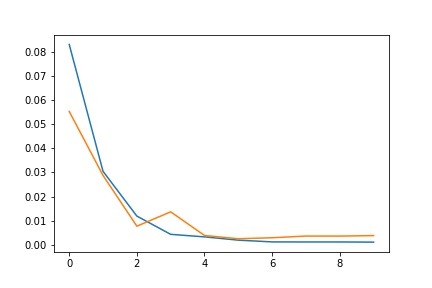
I played around with the learning rate and number of epoches. Because the training set was pretty small, it would easily lead to overfitting, and we can see the training and validation loss fluctuates a lot with 1e-3 as the learning rate. So I tried to decrease the learning rate by 10, and the loss didn't seem to fluctuate that much. I used a batch size of 12 and trained for 10 epoches.
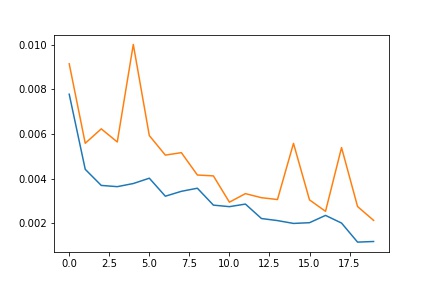
|
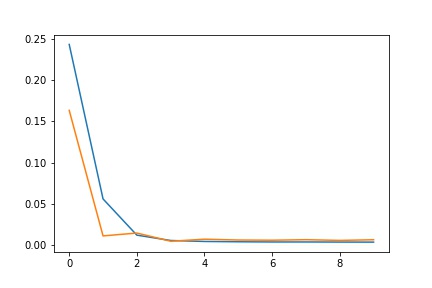
|
Full Facial Keypoints Detection
Here are the two sampled image from my dataloader visualized with ground-truth keypoints.

|

|
Cases where the classifier detects facial features incorrectly. I noticed that if the face is not looking directly towards the camera, the classifier has a high possiblility of detecting wrong features. This might be a lack of data in images of people looking away. To solve this problem, I could try to perform extra data augmentation on original images that looks away.
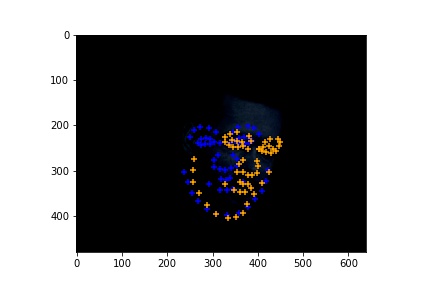
|
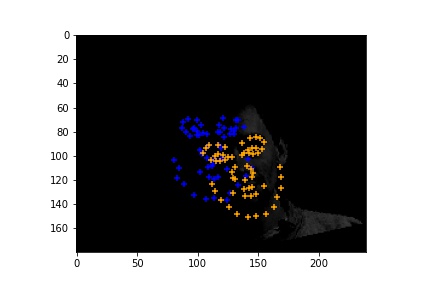
|
Here are the cases where the classifier did a good job.
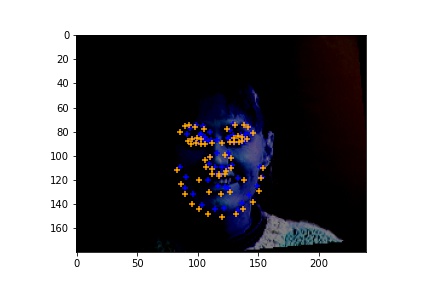
|
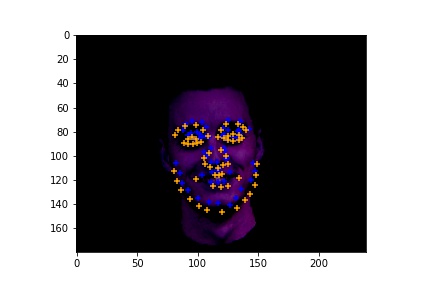
|
The network structure that I used
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(24, 32, kernel_size=(5, 5), stride=(1, 1))
(conv4): Conv2d(32, 48, kernel_size=(5, 5), stride=(1, 1))
(conv5): Conv2d(48, 96, kernel_size=(5, 5), stride=(1, 1))
(fc2): Linear(in_features=288, out_features=180, bias=True)
(fc3): Linear(in_features=180, out_features=116, bias=True)
For the hyperparameters, I used a learning rate of 1e-3 and 20 epoches at first, I then realized that the model converges at around epoch 10, so I changed the epoch to 10. I used the Adams optimizer. The batch size was 24.
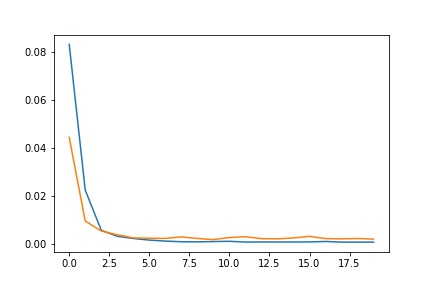
|
|
Part 3: Train with Larger Dataset
Here is the complete structure of my neural network. It is basically ResNet18 with small modifications in the number of in and out kernels.
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
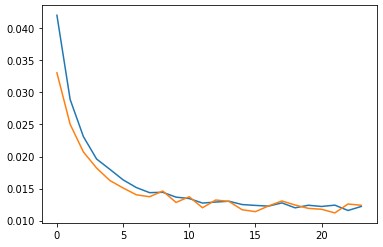
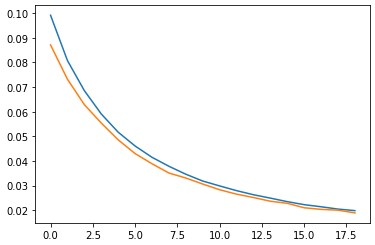
I used adams optimizer with pytorch's cyclic learning rate optimizer. I tried applying the base learning rate as 1e-3, and the max learning rate as 5e-3 with batch sizes of 64 and trained for 25 epoches. However, it turns out that the model would just go overfitting and perform badly on the test set. Therefore, I decreased the learning rate to [1e-4] to [1e-3] and trained the model for 25 epoches.
|
|
Cases where the classifier detects facial features incorrectly. The classifier make mistakes when the face is not located in the center of the image.
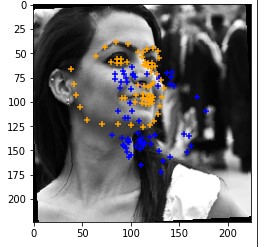
|
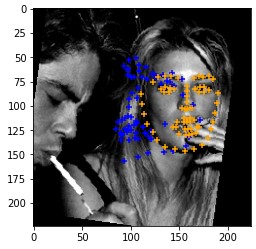
|
Here are the cases where the classifier did a good job.
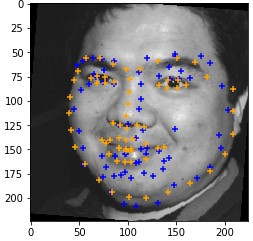
|
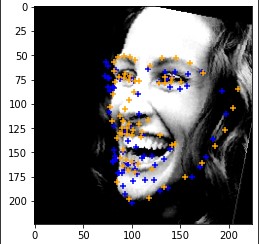
|
Here are the results of applying the model to test images.
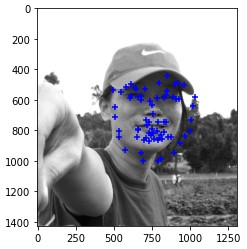
|
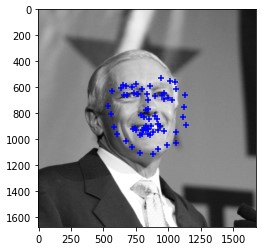
|