CS194-26: Project 5 - Sean Chen
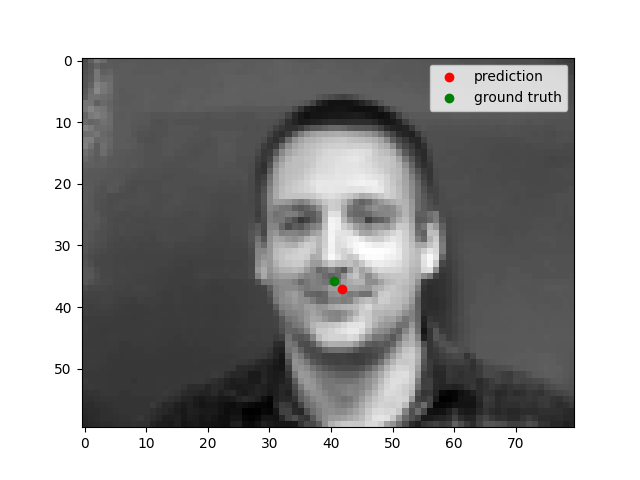
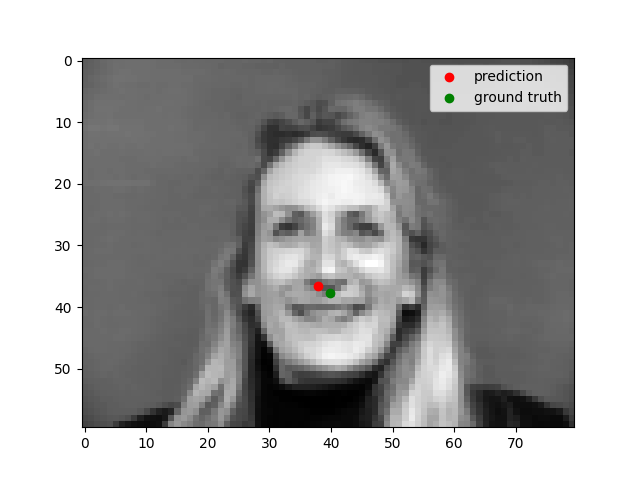
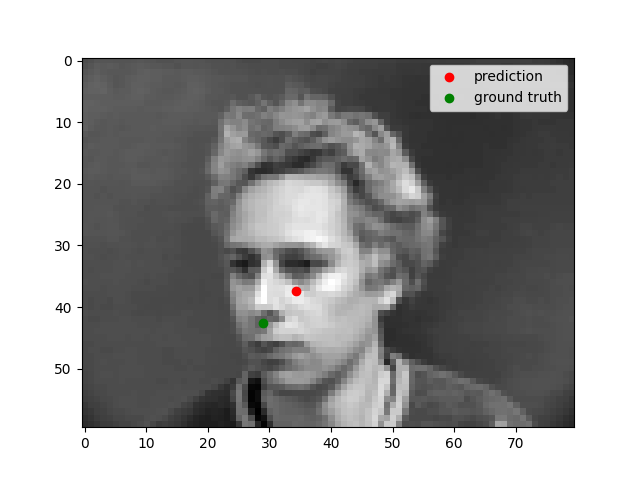
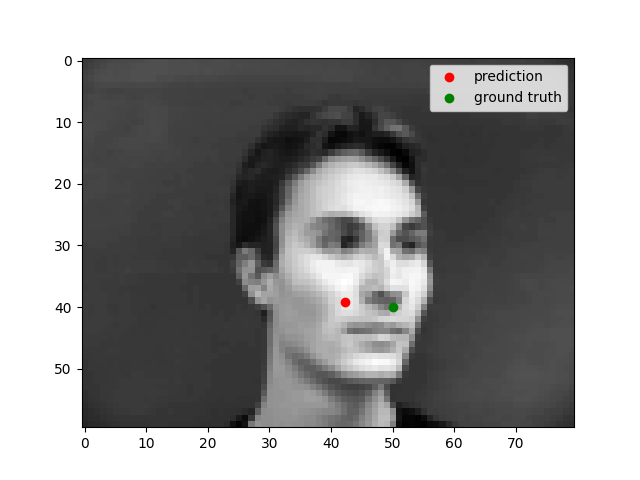
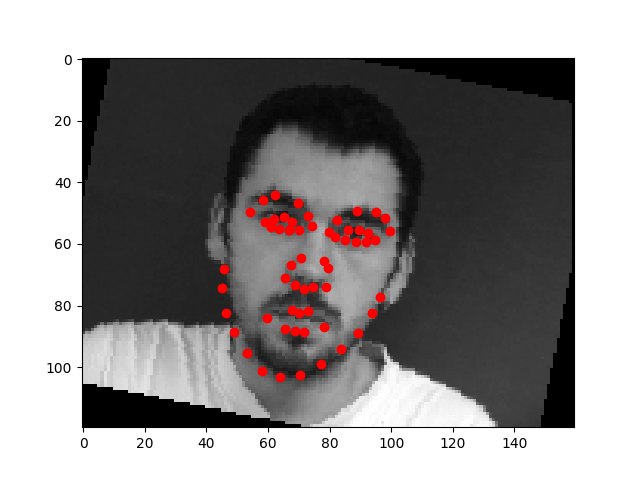
Nose Detection
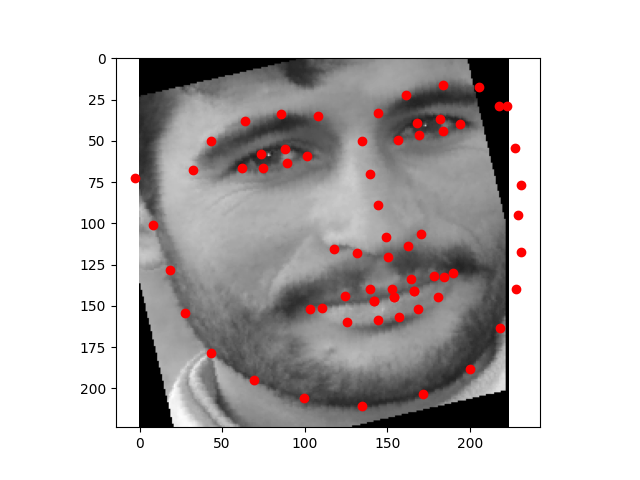
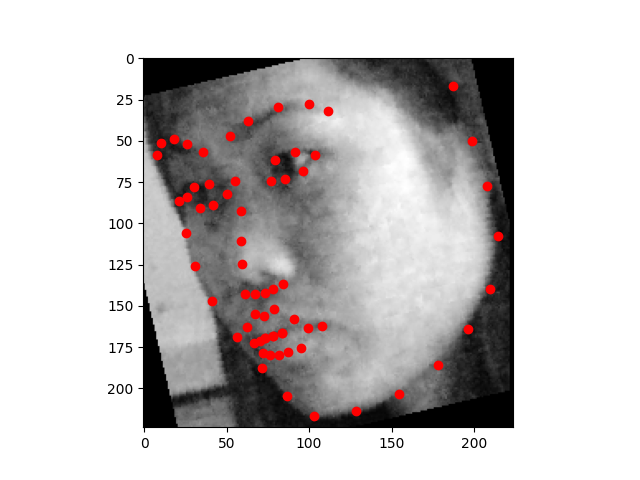
We can see that the model performs well for centered images but does not perform well for images where the person faces to one side. This could be because there is less features in the photo when the person's face is not centered.
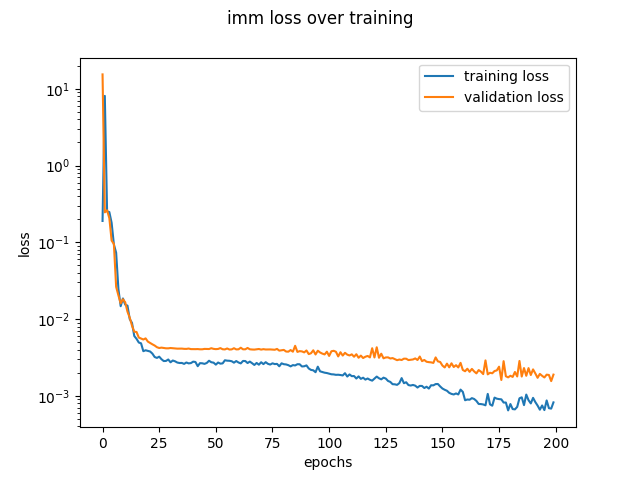
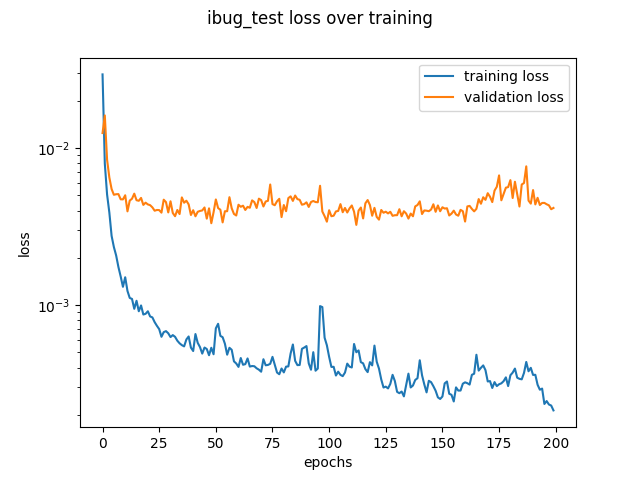
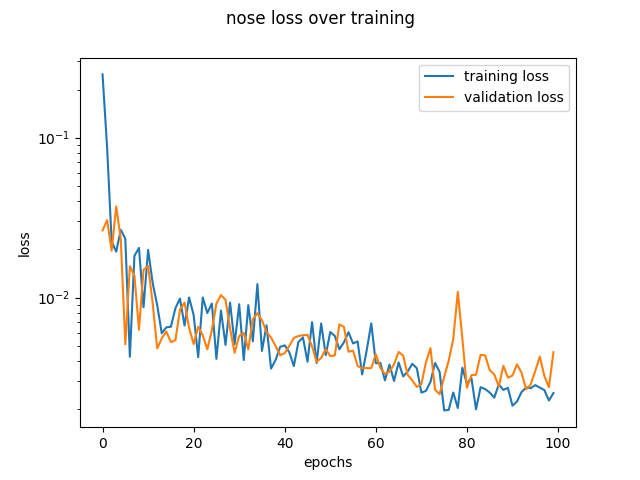
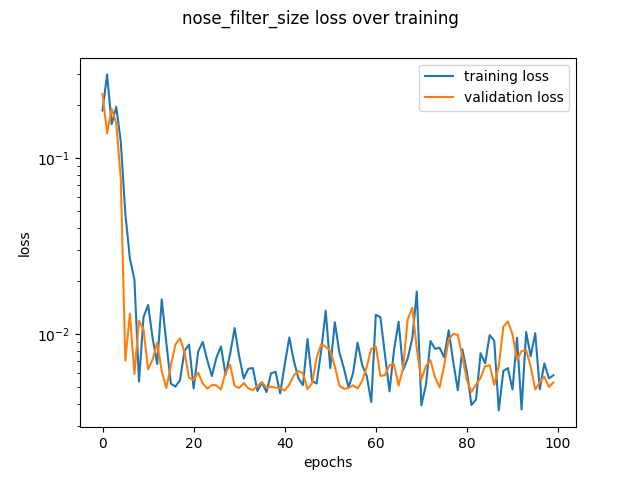
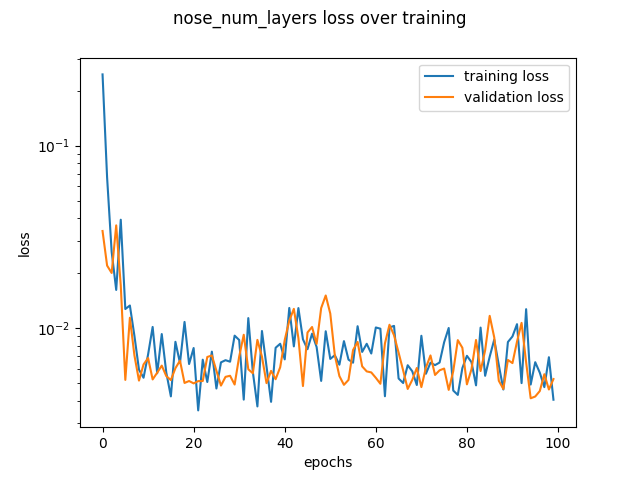
My default model used filter size of 3, maxpooling of size 2, 32 channels, 4 layers. I tested a filter size of 5 and 6 layers. These got similar results on the loss curves.
 |
 |
 |
| default |
larger filter size |
more layers |
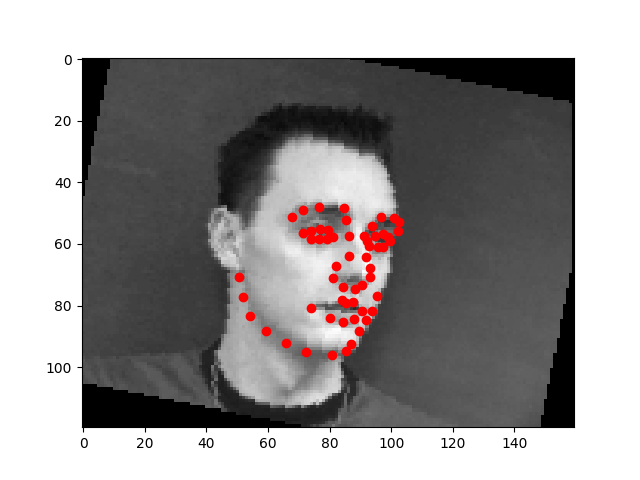
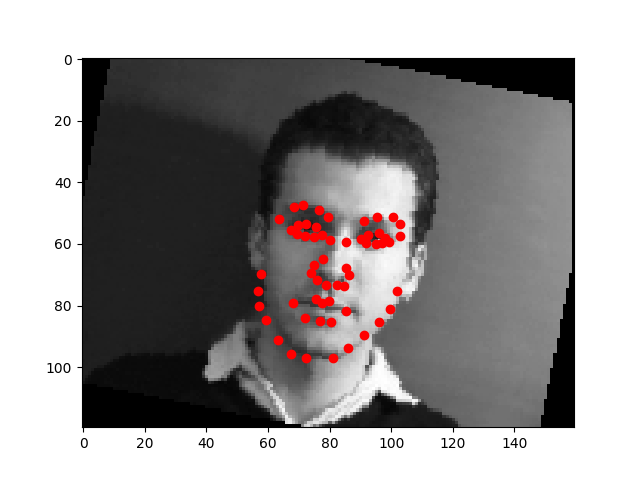
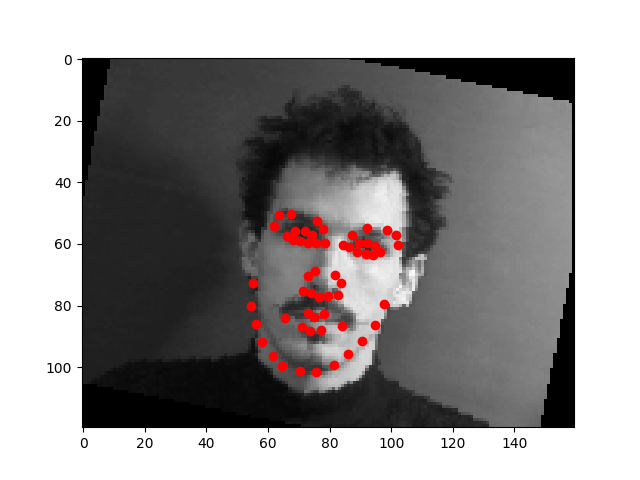
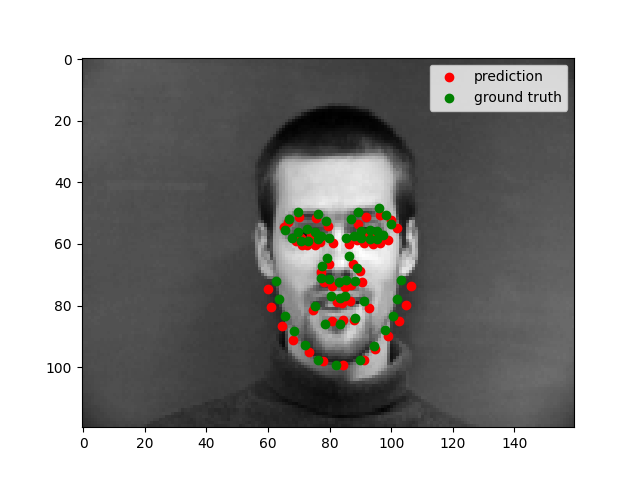
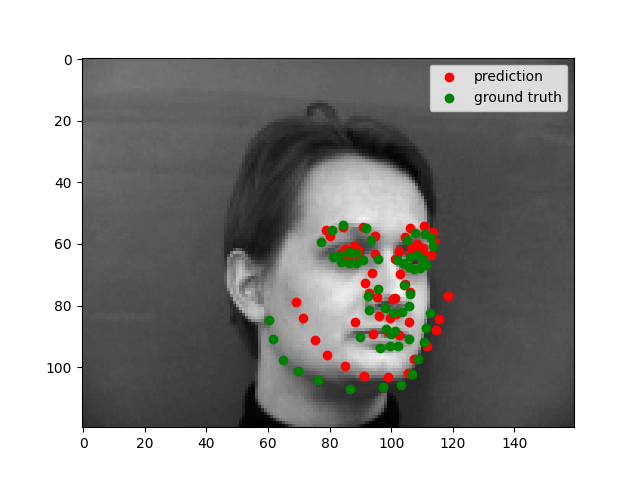
Full Face Feature Detection
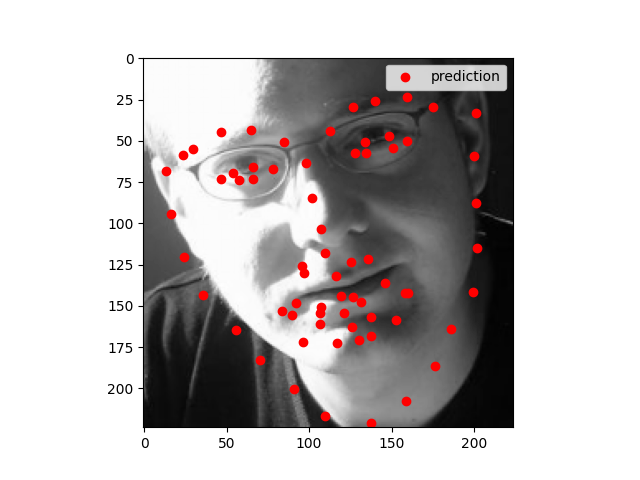
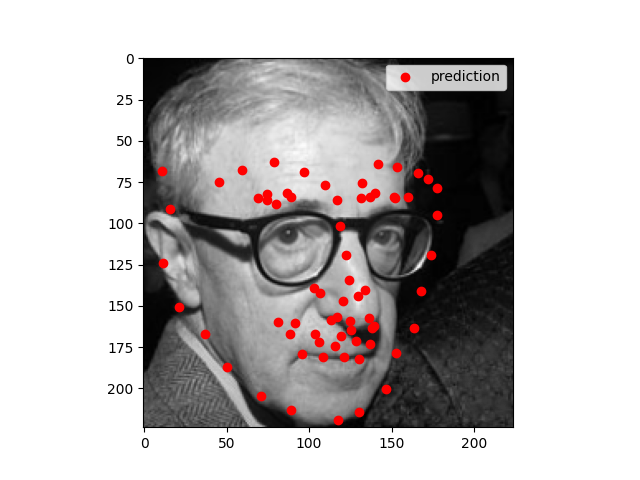
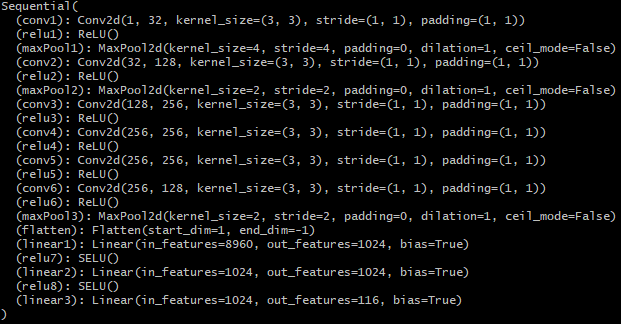
My model architecture is shown below as by its print statement. I still trained with same learning rate as before (1e-3) and with Adam optimizer. Notable choices that seemed to help were to use SELU for the linear layers, and to copy the pooling choices of AlexNet. We still see that the model performs well for centered images but does not perform well for images where the person faces to one side.
If we look at the individual channel outputs from the first convolutional layer, we see that the kernels learn a variety of edge detection, lighting modification, and change in camera intrinsics. The difference between some channels is subtle.

Train With Larger Dataset
My Kaggle username is Sean Chen. the MAE I achieved was 14.9.
My model architecture is shown below as by its print statement. It is simply the ResNet18 architecture with the final linear layer replaced with one that outputs size 136.

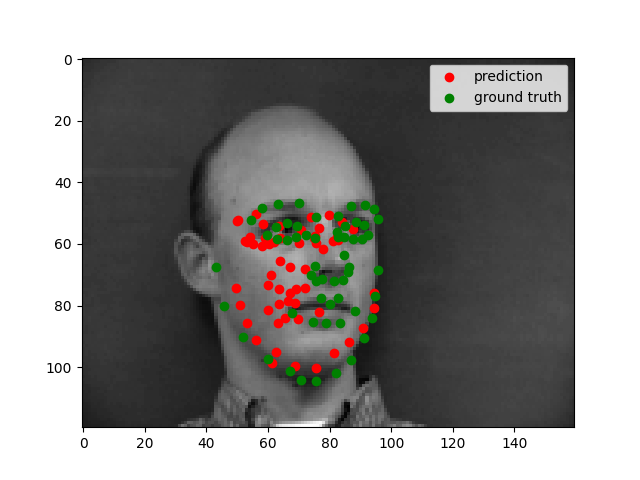
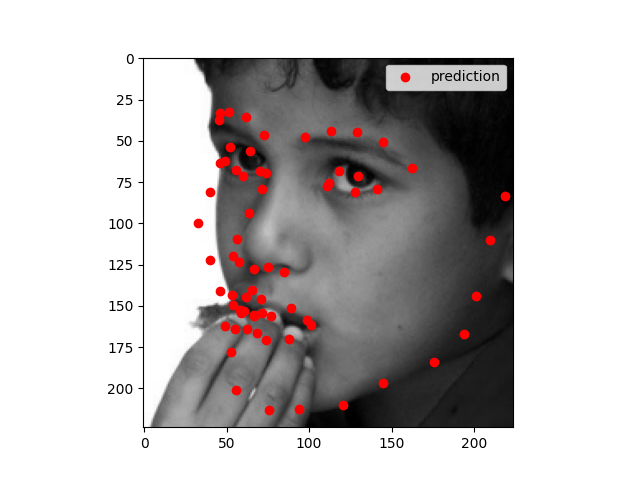
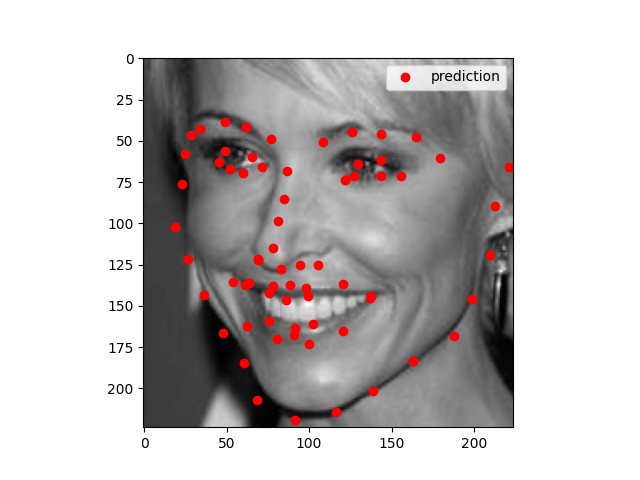
The model works well when all the facial features are prominent. It does not work well when the person is wearing glasses
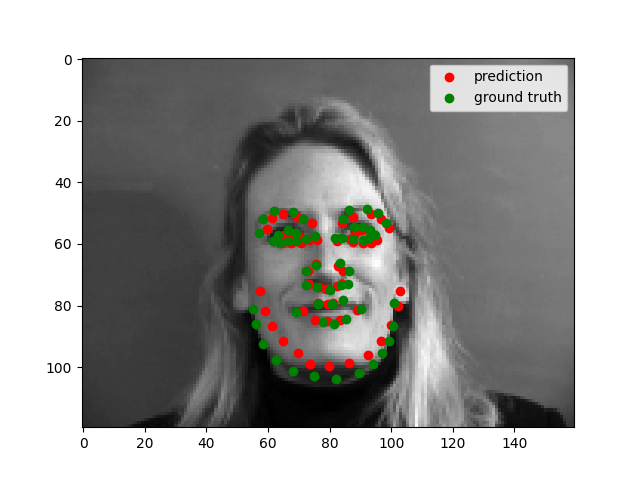
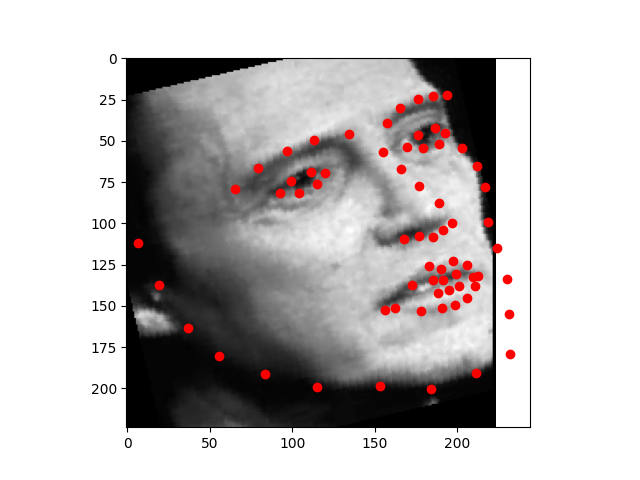
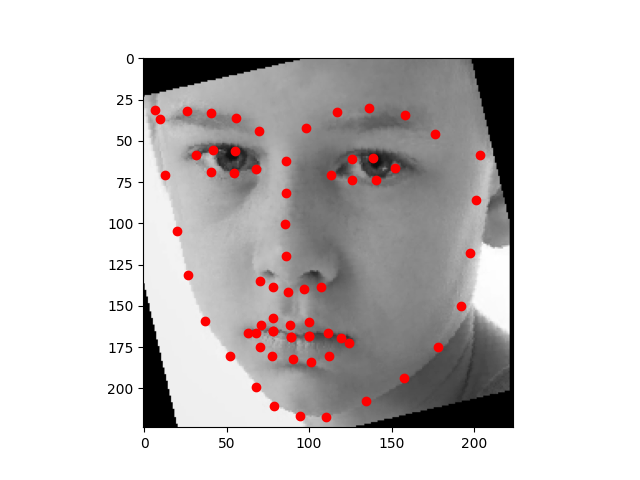
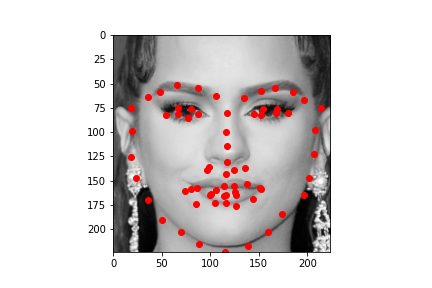
Using the photos from the third homework. The photo where the face is front and center, the model does very well on. But the photos where the face takes less of the area, the model does not do as well
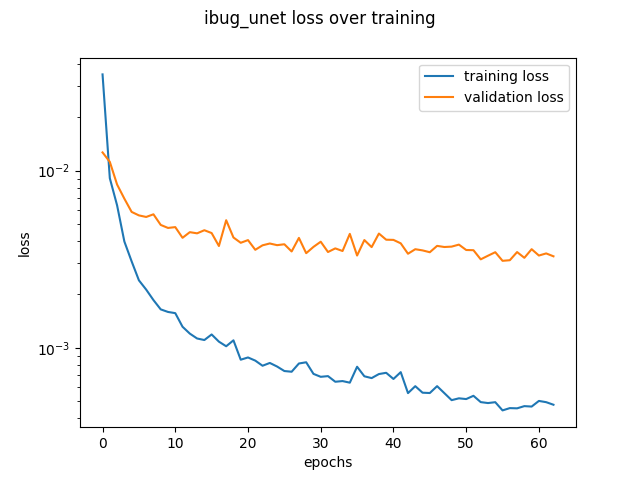
Training with UNet
I tested using the popular brain segmentation unet model on torch hub. The model was trained by using a heatmap for probability of feature points. the points were softened by surrounding them with a gaussian. I used a standard deviation and gaussian kernel such that the non-zero probability rate on the heat map was about .2. Unfortunately, the performance was not better than ResNet18, and the data loading for the heat map was a lot more expensive.