
In this part of the project, we used Pytorch to build a neural network to detect the nose tip location on a face. We trained on the IMM Face Dataset, which contained many images of faces and their corresponding facial keypoint locations. We had to write a custom dataloader, convolutional neural network, and network training/validation code.
Samples from dataloader, with nose tip annotated (images were converted to grayscale, normalized, and resized to (80, 60)):
I divided my data into a training and validation set, using the images of the first 32 people in the dataset as training and the images of the remaining 8 people as validation.
For my final network, I used three convolutional layers (all outputting 16 channels), each of which was followed by a relu and a max pooling layer. At the end, I had two linear layers, which were size (1120, 256) and (256, 2). After the second convolution layer, I also added a dropout layer with p = 0.3, to reduce overfitting.
Below, I show the training/validation loss graphs for few different sets of hyperparameters I tried, in order to choose my final model:
Test 1: Learning rate = 1e-2, num_epochs = 25, batch_size = 10, filter_size = 3, dropout = 0.3:
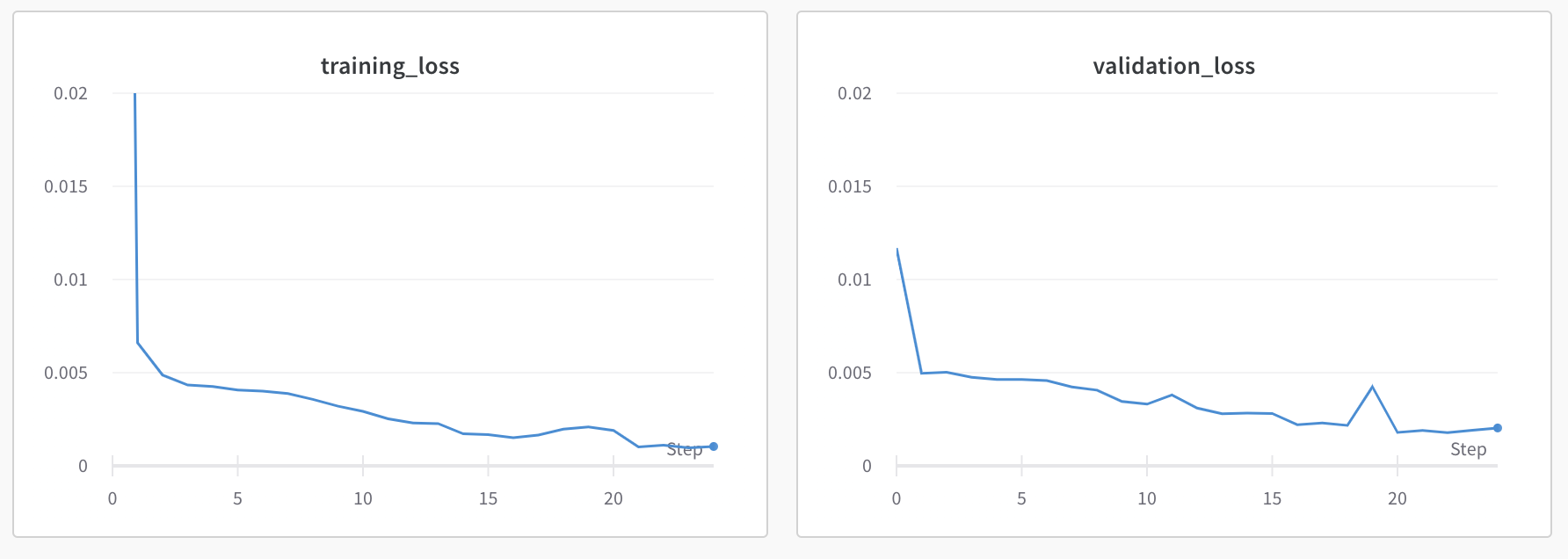
This seems pretty good, so I increased the learning rate to see if it could learn even faster.
Test 2: Learning rate = 1e-3, num_epochs = 25, batch_size = 10, filter_size = 3, dropout = 0.3:
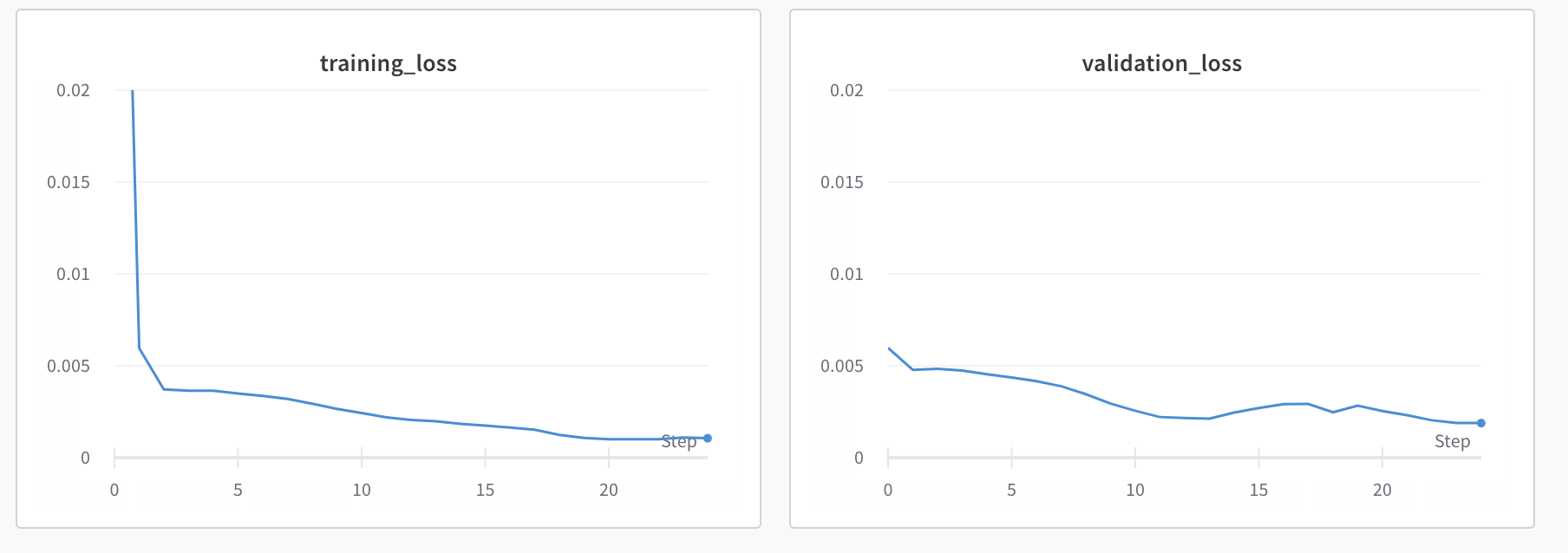
The final validation loss improved slightly. Next, I tried increasing the filter size for my convolutions to see if I could get the overall training/validation loss to go down (prevent underfitting).
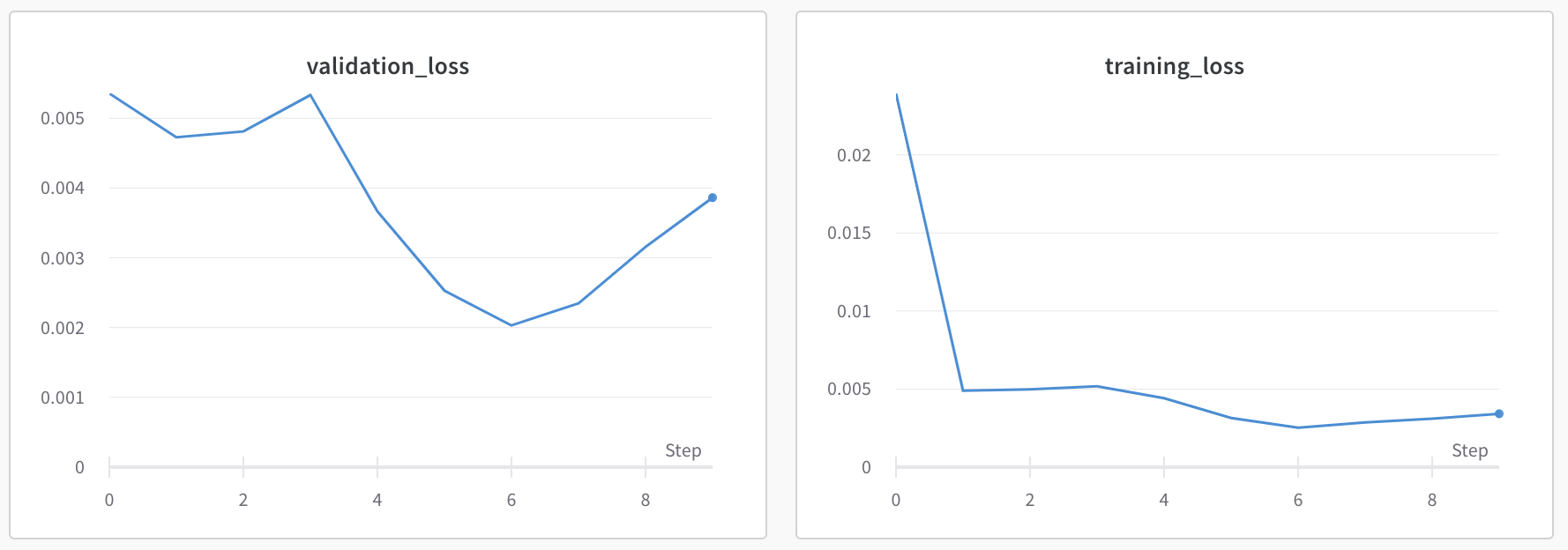
Test 3: Learning rate = 1e-3, num_epochs = 25, batch_size = 10, filter_size = 5, dropout = 0.3:
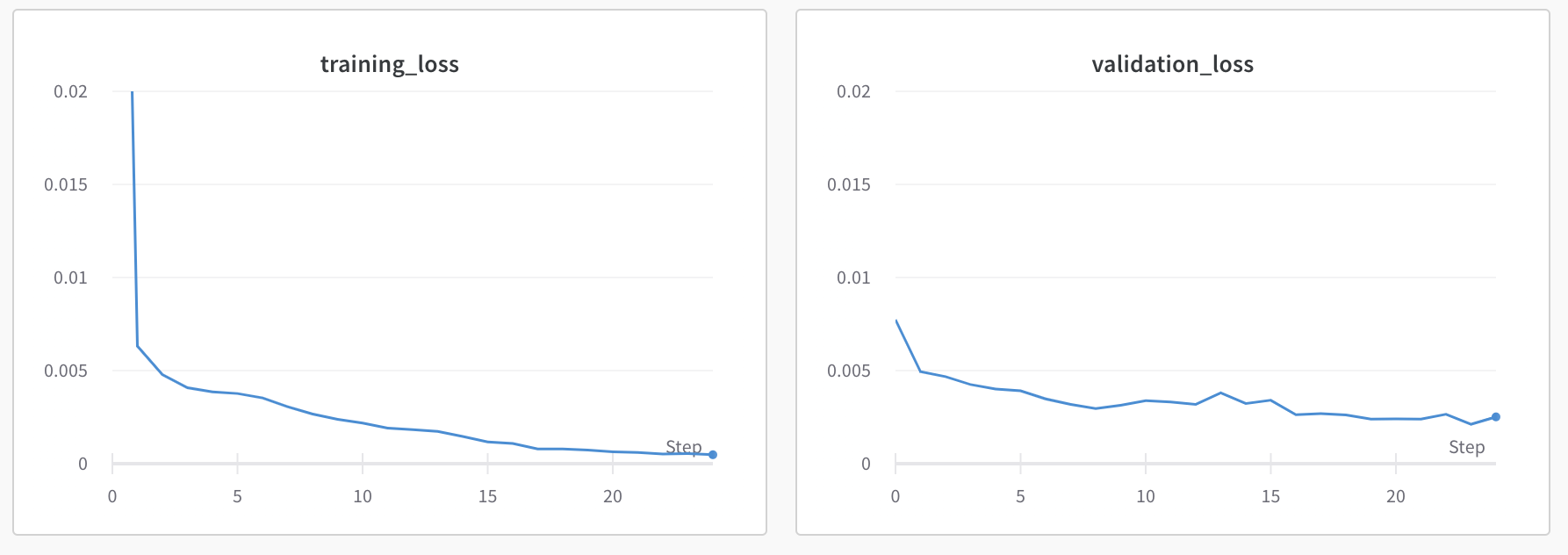
This resulted in some overfitting, and a higher validation loss. So, I went back to Test 2 but decreased the dropout to see if I could fix underfitting.
Test 3: Learning rate = 1e-3, num_epochs = 25, batch_size = 10, filter_size = 5, dropout = 0.1:
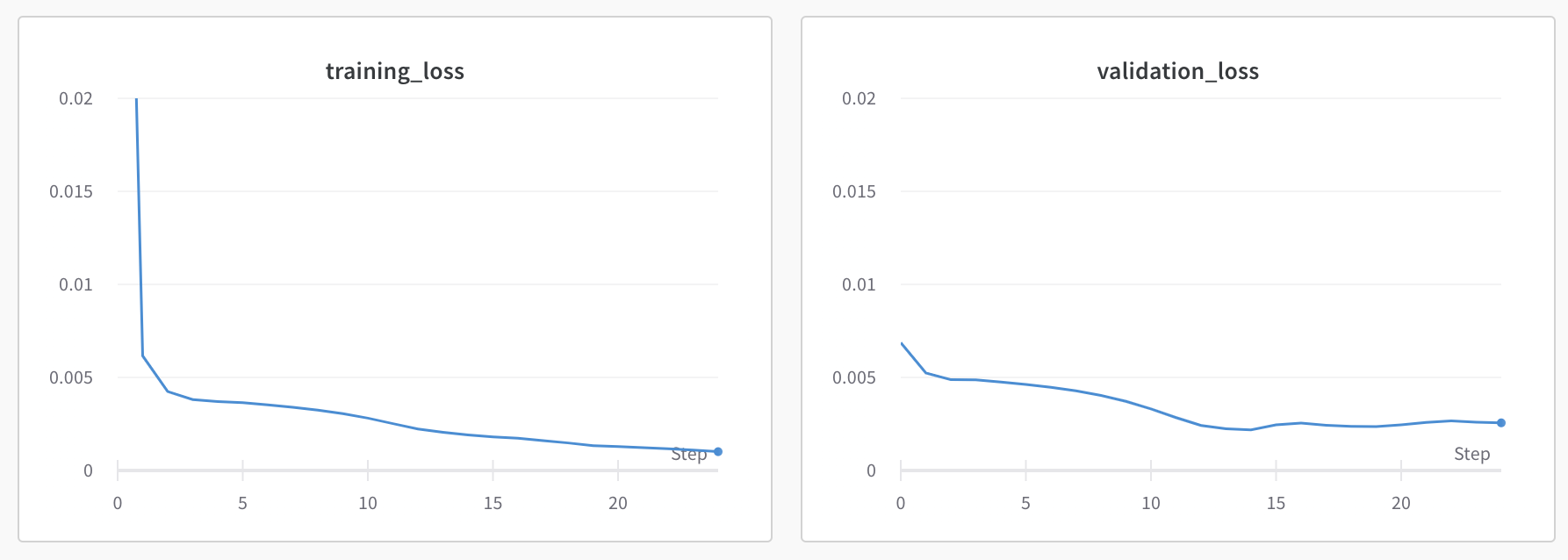
This did not decrease the training loss, and resulted in a higher validation loss.
I ended up choosing the parameters from Test 2 because they resulted in the lowest final validation loss.
Results on all validation images, with final model:

Some success cases:



Some failure cases:


The model failed on most images of this person, possibly because he has a different hair color/hairstyle than the other men in the dataset, or because his eyebrows are closer together than the other people in the dataset. I don't think it has to do with the face angle in the picture, surprisingly, because the model still failed even on an image of him looking directly at the camera. It seems like the model just couldn't generalize to this person's face shape.
In this part, we expanded the previous part to be able to detect 58 facial keypoints instead of just the nose tip.
For the dataloader, I added in augmentation (only for the training data) since we have a small dataset and don't want to overfit. For each image, I randomly rotated it between -15 and 15 degrees, and randomly shifted it vertically and horizontally by between -10 and 10 pixels. Below, I show some sample training data from the dataloader, with the facial keypoints annotated (images were converted to grayscale, normalized, and resized to (160, 120)).

For my model architecture, I used five convolutional layers, followed by 3 linear layers. The first two convolutional layers had a filter size of 5, while the remaining 3 had a filter size of 3. The number of output channels from the convolutional layers was 12, 24, 32, 64, and 128. Each convolutional layer was followed by a relu and a max pooling layer (filter size 2 by 2, stride 2). I also added two dropout layers, with p = 0.3, to reduce overfitting. The final output of the network is of size (batch_size, 116), because we want to detect the (x,y) locations of the 58 keypoints for each image. The detailed model architecture is shown below (note that the output shape column assumes an input of size (10, 1, 160, 120), where batch_size is 10):
========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== Part2Net -- -- ├─Conv2d: 1-1 [10, 12, 158, 118] 312 ├─ReLU: 1-2 [10, 12, 158, 118] -- ├─MaxPool2d: 1-3 [10, 12, 79, 59] -- ├─Conv2d: 1-4 [10, 24, 77, 57] 7,224 ├─ReLU: 1-5 [10, 24, 77, 57] -- ├─MaxPool2d: 1-6 [10, 24, 38, 28] -- ├─Conv2d: 1-7 [10, 32, 38, 28] 6,944 ├─ReLU: 1-8 [10, 32, 38, 28] -- ├─MaxPool2d: 1-9 [10, 32, 19, 14] -- ├─Dropout: 1-10 [10, 32, 19, 14] -- ├─Conv2d: 1-11 [10, 64, 19, 14] 18,496 ├─ReLU: 1-12 [10, 64, 19, 14] -- ├─MaxPool2d: 1-13 [10, 64, 9, 7] -- ├─Conv2d: 1-14 [10, 128, 9, 7] 73,856 ├─ReLU: 1-15 [10, 128, 9, 7] -- ├─MaxPool2d: 1-16 [10, 128, 4, 3] -- ├─Dropout: 1-17 [10, 128, 4, 3] -- ├─Linear: 1-18 [10, 1024] 1,573,888 ├─ReLU: 1-19 [10, 1024] -- ├─Linear: 1-20 [10, 1024] 1,049,600 ├─ReLU: 1-21 [10, 1024] -- ├─Linear: 1-22 [10, 116] 118,900 ========================================================================================== Total params: 2,849,220 Trainable params: 2,849,220 Non-trainable params: 0 Total mult-adds (M): 572.27 ========================================================================================== Input size (MB): 0.77 Forward/backward pass size (MB): 31.23 Params size (MB): 11.40 Estimated Total Size (MB): 43.39 ==========================================================================================
Overall, my hyperparameters for the final model were:
First two convolutions filter size: 5
Next three convolutions filter size: 3
Batch Size: 10
Learning rate: 1e-3
Num Epochs: 100
Dropout: 0.3
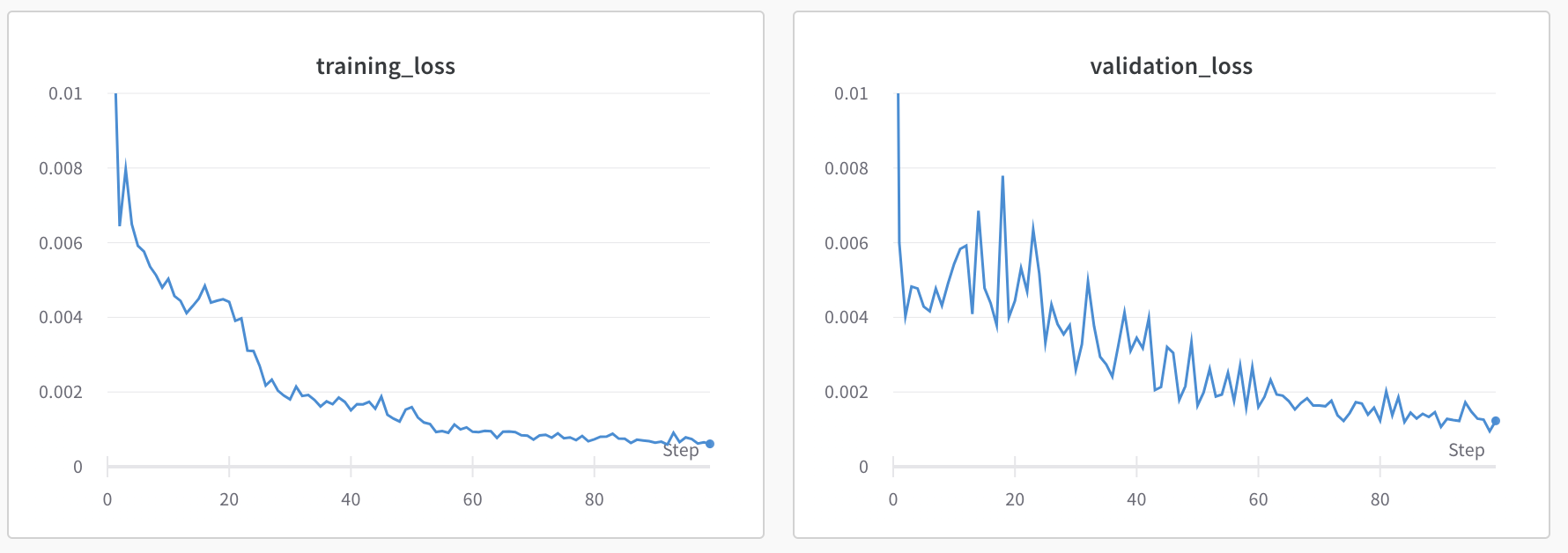
Below, I show training/validation loss for this model:
Results on all validation images, with final model (these results display the predicted keypoints on the converted to grayscale/normalized/resized images):

Some success cases:


Some failure cases:


I think it failed for these two images because they have different facial expressions than the other images (the first has a wide open mouth, and the second one has a slight head tilt, a large smile, and hands by the head). All of these factors make it hard for the model to generalize to these images, because it hasn't seen too many images like these.
Visualizing the learned filters:
These are the learned weights for the 12 convolutions in the first layer (these filter images are normalized to have values between 0 and 1).
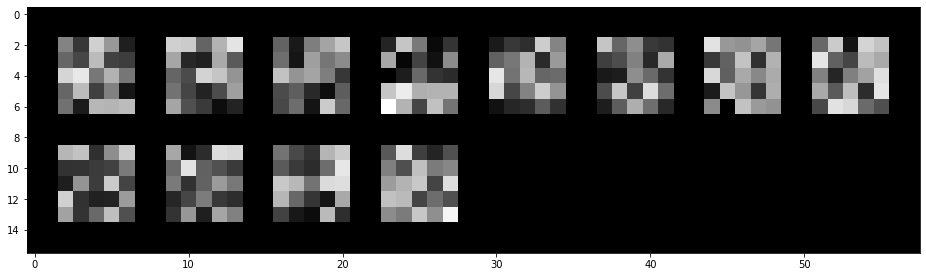
As a human, it is hard to interpret what these filters are doing, but I can see that they are all different from one another.
For this part, we wanted to do full facial keypoint detection, but training on a larger dataset (the ibug_300W_large_face_landmark_dataset). We were also provided with some test images from the same dataset.
I divided the training data into training and validation data, using a randomly selected 5500 images for training and another 1166 for validation. For the training data, I used the same data augmentation techniques as part 2 (randomly rotating and shifting the image). Also, I converted all the images to grayscale, normalized them, cropped them to their bounding boxes, and resized them to (224, 224). I made the bounding boxes 1.2 times their original height and width for the training and validation data, because I found that helped the model underfit less.
I used the resnet-18 model, but changed the input layer to take in an image with 1 channel instead of 3, otherwise keeping it the same, and I changed the final linear layer to output 136 values instead of 1000. The detailed architecture of my model is shown below (note that the output shape column assumes an input of size (64, 1, 224, 224), where batch_size is 64):
========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== ResNet -- -- ├─Conv2d: 1-1 [64, 64, 112, 112] 3,136 ├─BatchNorm2d: 1-2 [64, 64, 112, 112] 128 ├─ReLU: 1-3 [64, 64, 112, 112] -- ├─MaxPool2d: 1-4 [64, 64, 56, 56] -- ├─Sequential: 1-5 [64, 64, 56, 56] -- │ └─BasicBlock: 2-1 [64, 64, 56, 56] -- │ │ └─Conv2d: 3-1 [64, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-2 [64, 64, 56, 56] 128 │ │ └─ReLU: 3-3 [64, 64, 56, 56] -- │ │ └─Conv2d: 3-4 [64, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-5 [64, 64, 56, 56] 128 │ │ └─ReLU: 3-6 [64, 64, 56, 56] -- │ └─BasicBlock: 2-2 [64, 64, 56, 56] -- │ │ └─Conv2d: 3-7 [64, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-8 [64, 64, 56, 56] 128 │ │ └─ReLU: 3-9 [64, 64, 56, 56] -- │ │ └─Conv2d: 3-10 [64, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-11 [64, 64, 56, 56] 128 │ │ └─ReLU: 3-12 [64, 64, 56, 56] -- ├─Sequential: 1-6 [64, 128, 28, 28] -- │ └─BasicBlock: 2-3 [64, 128, 28, 28] -- │ │ └─Conv2d: 3-13 [64, 128, 28, 28] 73,728 │ │ └─BatchNorm2d: 3-14 [64, 128, 28, 28] 256 │ │ └─ReLU: 3-15 [64, 128, 28, 28] -- │ │ └─Conv2d: 3-16 [64, 128, 28, 28] 147,456 │ │ └─BatchNorm2d: 3-17 [64, 128, 28, 28] 256 │ │ └─Sequential: 3-18 [64, 128, 28, 28] 8,448 │ │ └─ReLU: 3-19 [64, 128, 28, 28] -- │ └─BasicBlock: 2-4 [64, 128, 28, 28] -- │ │ └─Conv2d: 3-20 [64, 128, 28, 28] 147,456 │ │ └─BatchNorm2d: 3-21 [64, 128, 28, 28] 256 │ │ └─ReLU: 3-22 [64, 128, 28, 28] -- │ │ └─Conv2d: 3-23 [64, 128, 28, 28] 147,456 │ │ └─BatchNorm2d: 3-24 [64, 128, 28, 28] 256 │ │ └─ReLU: 3-25 [64, 128, 28, 28] -- ├─Sequential: 1-7 [64, 256, 14, 14] -- │ └─BasicBlock: 2-5 [64, 256, 14, 14] -- │ │ └─Conv2d: 3-26 [64, 256, 14, 14] 294,912 │ │ └─BatchNorm2d: 3-27 [64, 256, 14, 14] 512 │ │ └─ReLU: 3-28 [64, 256, 14, 14] -- │ │ └─Conv2d: 3-29 [64, 256, 14, 14] 589,824 │ │ └─BatchNorm2d: 3-30 [64, 256, 14, 14] 512 │ │ └─Sequential: 3-31 [64, 256, 14, 14] 33,280 │ │ └─ReLU: 3-32 [64, 256, 14, 14] -- │ └─BasicBlock: 2-6 [64, 256, 14, 14] -- │ │ └─Conv2d: 3-33 [64, 256, 14, 14] 589,824 │ │ └─BatchNorm2d: 3-34 [64, 256, 14, 14] 512 │ │ └─ReLU: 3-35 [64, 256, 14, 14] -- │ │ └─Conv2d: 3-36 [64, 256, 14, 14] 589,824 │ │ └─BatchNorm2d: 3-37 [64, 256, 14, 14] 512 │ │ └─ReLU: 3-38 [64, 256, 14, 14] -- ├─Sequential: 1-8 [64, 512, 7, 7] -- │ └─BasicBlock: 2-7 [64, 512, 7, 7] -- │ │ └─Conv2d: 3-39 [64, 512, 7, 7] 1,179,648 │ │ └─BatchNorm2d: 3-40 [64, 512, 7, 7] 1,024 │ │ └─ReLU: 3-41 [64, 512, 7, 7] -- │ │ └─Conv2d: 3-42 [64, 512, 7, 7] 2,359,296 │ │ └─BatchNorm2d: 3-43 [64, 512, 7, 7] 1,024 │ │ └─Sequential: 3-44 [64, 512, 7, 7] 132,096 │ │ └─ReLU: 3-45 [64, 512, 7, 7] -- │ └─BasicBlock: 2-8 [64, 512, 7, 7] -- │ │ └─Conv2d: 3-46 [64, 512, 7, 7] 2,359,296 │ │ └─BatchNorm2d: 3-47 [64, 512, 7, 7] 1,024 │ │ └─ReLU: 3-48 [64, 512, 7, 7] -- │ │ └─Conv2d: 3-49 [64, 512, 7, 7] 2,359,296 │ │ └─BatchNorm2d: 3-50 [64, 512, 7, 7] 1,024 │ │ └─ReLU: 3-51 [64, 512, 7, 7] -- ├─AdaptiveAvgPool2d: 1-9 [64, 512, 1, 1] -- ├─Linear: 1-10 [64, 136] 69,768 ========================================================================================== Total params: 11,240,008 Trainable params: 11,240,008 Non-trainable params: 0 Total mult-adds (G): 111.04 ========================================================================================== Input size (MB): 12.85 Forward/backward pass size (MB): 2543.39 Params size (MB): 44.96 Estimated Total Size (MB): 2601.20 ==========================================================================================
My final hyperparameters for training were:
Learning rate = 1e-3
Num epochs = 10
Batch size = 64
Below is the graph of my training/validation loss when training the model.
It seems like I should have added more data augmentation, because the model is overfitting (validation loss is going up). Also, it seems like the training loss isn't going down fast enough either, so it might have been better to use a more complicated model.
Testing:
Before running my model on the testing images, I converted all the testing images to grayscale, normalized them, cropped them to their bounding boxes, and resized them to (224, 224). I made the bounding boxes twice their original height and width for the test data. Below, I show the results of my model on some of the test images, after applying the transformations described above.

The model did okay, but for some images the predicted keypoints aren't forming a clear picture of the facial features. This probably could have been fixed with more data augmentation (perhaps color jittering), but I didn't have enough time to try this.
Using my predictions on the testing set, I got a mean absolute error of 29.5087 on Kaggle! (under the name Bhavna Sud)
Finally, I show the results of my model on a few of my own test images (again after applying the cropping/normalization/resizing described above).

The model got all of these images wrong. The last one is likely because it's not even a human, and the first two may be incorrect because the faces are a different ethnicity than the model has seen before. Also, the first image has a mask, and I doubt there were images of masked people in the training set.