Nose Tip Detection
Sampled image from the dataloader visualized with ground-truth keypoints:






Plot the train and validation MSE loss during the training process:

Facial images which the network detects the nose correctly:






Facial images which the network detects the nose correctly:



While the front-on images resulted in more correct keypoint detection (considering that there were more consistent/uniform front images), the keypoints tended to detect incorrectly when the input image was expressive or turned. These are less likely to be consistent/uniform and less common within the dataset.
Facial Keypoints Detection
Sampled image from the dataloader visualized with ground-truth keypoints:






The architecture of my model:
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(12, 18, kernel_size=(6, 6), stride=(1, 1))
(conv3): Conv2d(18, 24, kernel_size=(5, 5), stride=(1, 1))
(conv4): Conv2d(24, 28, kernel_size=(4, 4), stride=(1, 1))
(conv5): Conv2d(28, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=4032, out_features=300, bias=True)
(fc2): Linear(in_features=300, out_features=116, bias=True)
features = nn.Sequential(
net.conv1, nn.ReLU(), nn.MaxPool2d((2, 2)),
net.conv2, nn.ReLU(),
net.conv3, nn.ReLU(), nn.MaxPool2d((2, 2)),
net.conv4, nn.ReLU(),
net.conv5, nn.ReLU(), nn.MaxPool2d((2, 2)))
Additionally, I added data augmentation to prevent the trained model from overfitting by shifting the image at random points by a range of (0, 15) pixels.
Plot the train and validation MSE loss during the training process:

Facial images which the network detects the facial keypoints correctly:




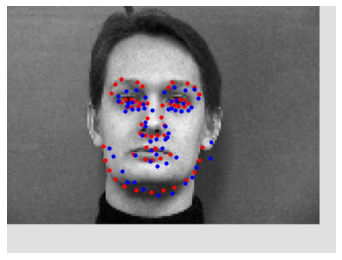

Images where it detects incorrectly:



These images also featured turned faces, photos that were overall darker/lower contrast than the rest of the dataset, and faces that featured expressions. These are characteristics that, as previously found in the nose point detection, are less common within the dataset.
Learned filters:
