CS 194-26 Project 5: Facial Keypoint Detection with Neural Networks
Brian Zhu, brian_zhu@berkeley.edu
Part 1: Nose-Tip Detection
Ground Truth Keypoints
Samples from training set:

Samples from validation set:

Convnet Architecture
ConvNetPart1(
(conv_layers): Sequential(
(0): Conv2d(1, 16, kernel_size=(7, 7), stride=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=same)
(4): ReLU(inplace=True)
(5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=same)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(flatten)
(fc_layers): Sequential(
(0): Linear(in_features=1728, out_features=512, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=512, out_features=2, bias=True)
)
)Training and Results
Training parameters:
- Learning rate: 1e-3
- Batch size: 8
- Number of gradient steps: 1000
- Each image is individually normalized so pixels are from standard normal
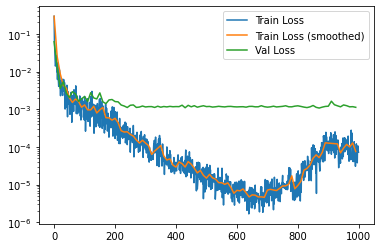
MSE Loss:
Validation set predictions:
Legend:
- Red: ground truth
- Green: predicted keypoint

We see that the model performs best when the face has a closed mouth and short hair:



But when there is something different (e.g. open mouth, unique hairstyle), the model has a hard time finding the nose tip:



The shape of the mouth and hairstyle are details that are not relevant to the model, yet the model picks up on these signals and it messes up the prediction. Combined with the MSE graph showing significantly lower training MSE than validation MSE, the model is overfitting to the training set and is relying on the hair, mouth, and possibly other unnecessary details to predict the position of the nose tip.
Hyperparameter Sweep
Sweeping across:
- Learning rate: 1e-2, 3e-3, 1e-3, 3e-4, 1e-4
- Batch size: 2, 4, 8
Constant parameters:
- Gradient steps: 1000
- Images normalized to standard normal
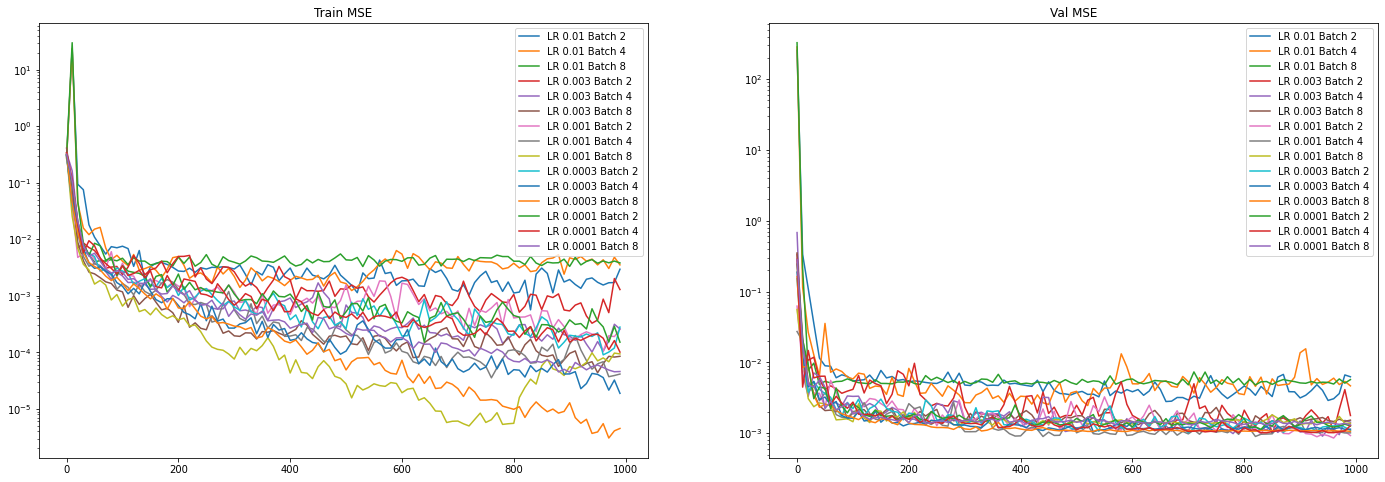
All runs together:
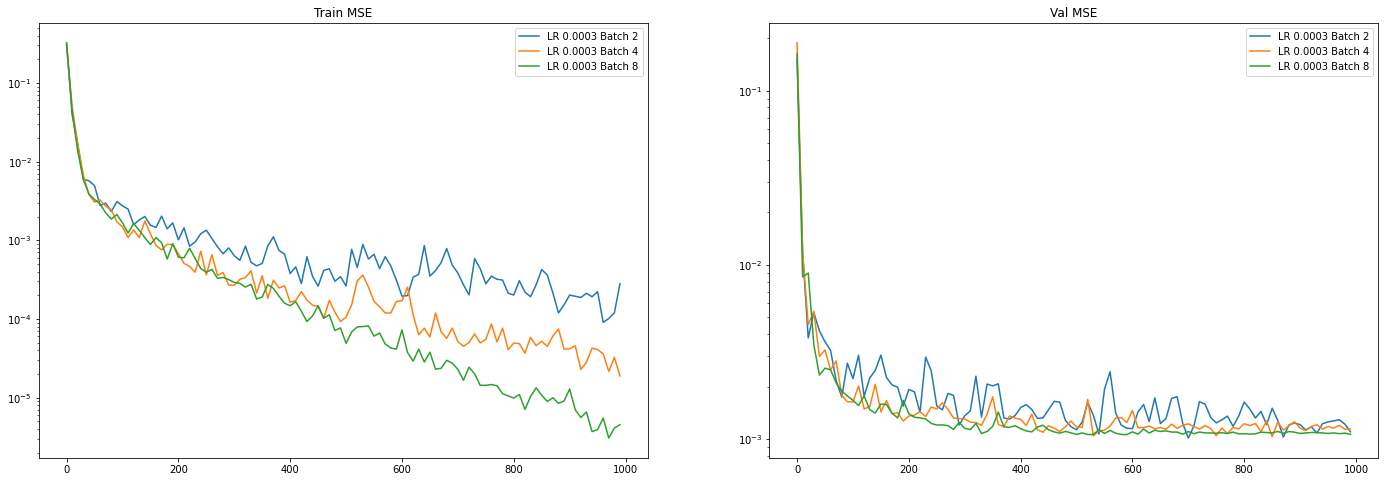
Holding learning rate constant at 3e-4:
Holding batch size constant at 8:
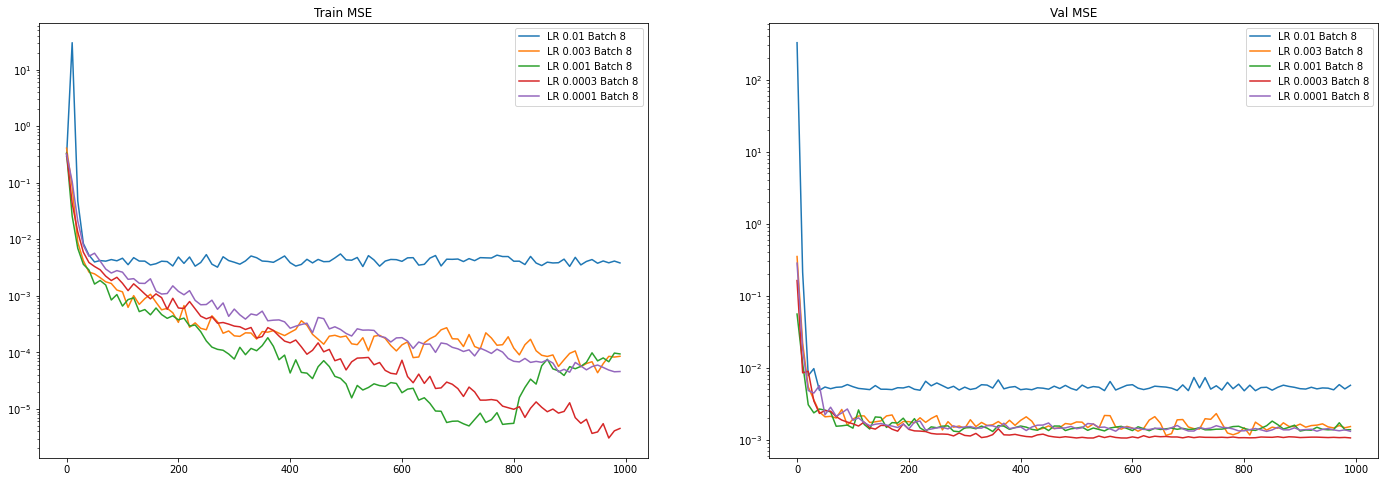
Trends:
- Increasing batch size makes training faster per step (not per epoch!). However, validation loss does not increase with larger batch size, so larger batch size means more overfitting. However, validation loss is more stable with a larger batch size.
- 3e-4 is the sweet spot as it has the best validation loss. 1e-3 is fast, but very infrequently suffers from training instability, as found in these plots
Part 2: Full Facial Keypoints Detection
Data Augmentation
Parameters:
- Rotation (degrees): Sampled from N(0, 3)
- Translation in x and y: Independently sampled from N(0, 5)
- Color Jitter:
- Brightness factor: uniformly sampled from [0.9, 1.1]
- Saturation factor: uniformly sampled from [0.9, 1.]
Samples with ground truth keypoints:

Convnet Architecture
ConvNetPart2(
(conv_layers): Sequential(
(0): Conv2d(1, 64, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 128, kernel_size=(5, 5), stride=(1, 1), padding=same)
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=same)
(7): ReLU(inplace=True)
(8): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=same)
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=same)
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(flatten)
(fc_layers): Sequential(
(0): Linear(in_features=8960, out_features=3072, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=3072, out_features=116, bias=True)
)
)Training and Results
Parameters:
- Learning rate: 1e-3
- Batch size: 16
- Number of gradient steps: 2000
- Images normalized to standard normal
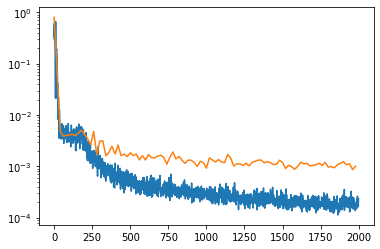
MSE Loss:
- Legend:
- Blue: Train Loss
- Orange: Validation Loss
Validation set predictions:
- Legend:
- Red: ground truth
- Blue: predicted keypoints

Just like in Part 1, the model is overfitting to the training set and has a hard time generalizing to unseen details, such as hairstyle, smiling/open mouth, hands in the image.


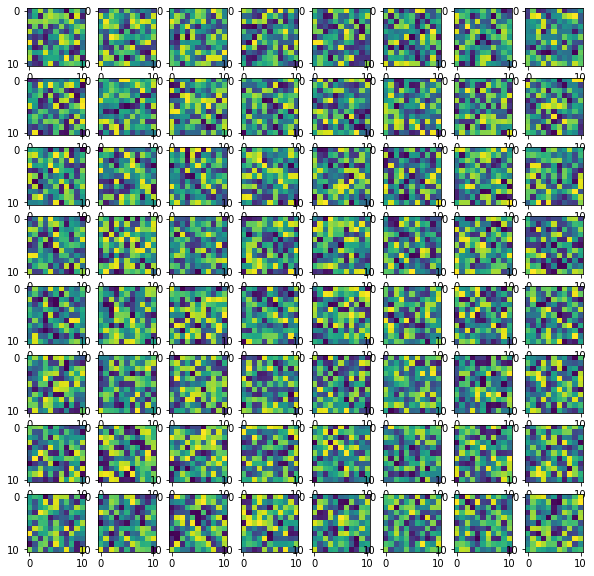
Learned filters from the first convolution layer:
Part 3: Train With Larger Dataset
Convnet Architecture:
Used pretrained Resnet18 and modified for grayscale images
- To modify for grayscale images: average the filter weights in
Conv1across the channel dimensionConv1filter weights size: (C_out, 3, K, K)
- After averaging across input channels: (C_out, 1, K, K)
- Parameters in
layer3,layer4, andfcmodules are unfrozen
- The
fclayer is reinitialized with an output dimension of 136 instead of 1000
Detailed Architecture
Resnet18IBUG( (resnet18): ResNet( (conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (flatten) (fc): Linear(in_features=512, out_features=136, bias=True) ) )
Training and Results
Parameters:
- Learning rate: 1e-4
- Batch size: 64
- Number of gradient steps: 10k
- Images augmented following the same procedure from Part 2
- For normalization, I followed the recommended mean and standard deviation from Pytorch documentation:
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])- However, since this is for RGB images, and I need to normalize for grayscale images, I just averaged the means and standard deviations together:
normalize = transforms.Normalize(mean=[(0.485 + 0.456 + 0.406)/3],
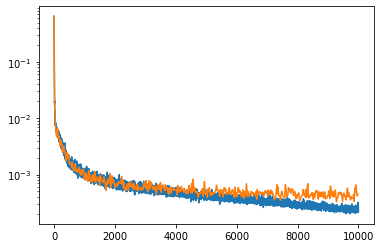
std=[(0.229 + 0.224 + 0.225)/3])MSE Loss:
- Legend:
- Blue: Train Loss
- Orange: Validation Loss
MAE on test set:

Validation set predictions:
- Legend:
- Red: ground truth
- Blue: predicted keypoints

Test set predictions:
