Overview
In this project I used convolutional neural networks to try to detect facial keypoints on a dataset of images.
Part 1
Nose Tip Detection
For this project, I used the IMM Face Database, which contained 240 facial images of 40 people. For each person there were 6 images takeen from different viewpoints. I created a convolutional neural network to detect the tip of people's noses.
First, I created a custom dataloader. I began by first resizing the images to be in dimensions 80x60, converting them to black and white, and normalizing to reduce variation between images. My dataloader loaded both the image and nose keypoint for each facial image.
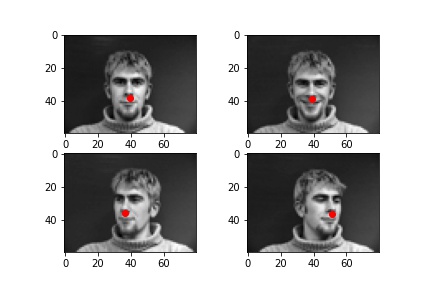
|
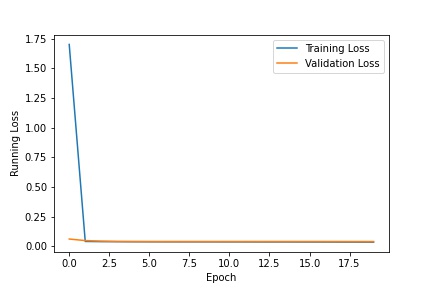
Then I wrote a convolutional neural network. My network has 3 convolutional layers followed by 2 fully-connected layers. I used a BATCH_SIZE = 25, NUM_EPOCHS = 10, and LEARNING_RATE = 0.001. I plotted the training vs. validation rates below.
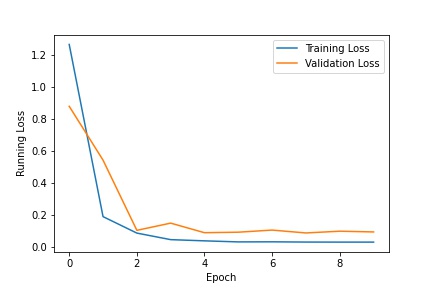
|
Some of my results are displayed below. My CNN performed fairly well on images where the subject was facing forward, but not as well for images where the subject was turned toward the side. I think it is because there is more data of the subjects facing the camera straight-on then there is of them in other poses.
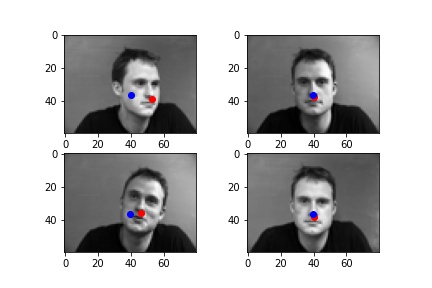
|
Part 2
Full Facial Keypoints Detection
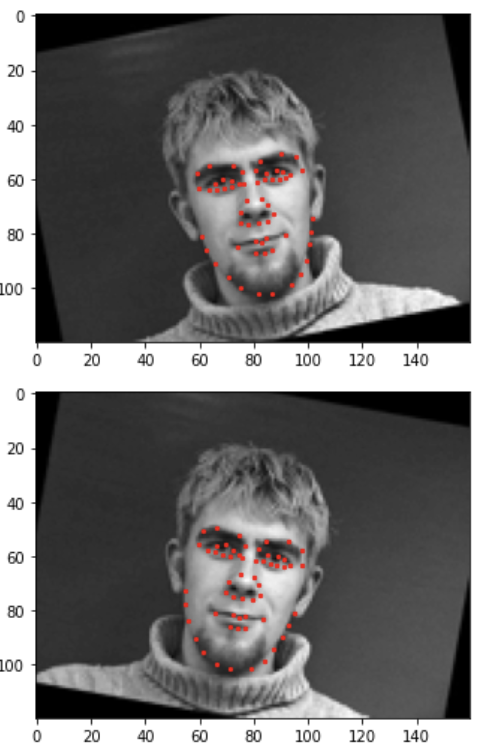
For Part 2 of the project, I expanded upon my nose-detection network to detect all 58 facial keypoints. Below are a couple sample images with all 58 ground-truth keypoints.
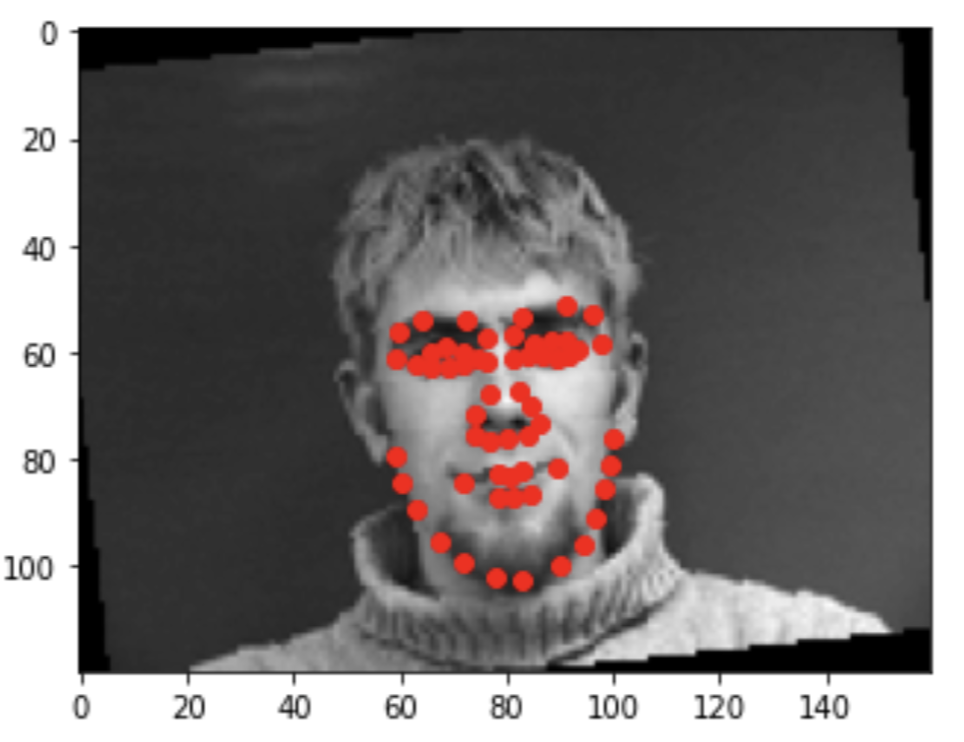
|
In order to get more data, I used data augmentation to create "new" data by making minor alterations to my dataset. For every input image from the original dataset, I created 5 new images, each rotated randomly by some amount of degrees in [-15, 15]. I also increased my image size from 80x60 to 160x120. Here are some samples of my augmented dataset.
|
With a larger image size, I needed to change the design of my neural network. I increased it to have 5 convolutional network layers, and kept the 2 fully connected layers. I tried adjusting batch size, epoch size, learning rate, and the inputs/outputs of my convolutional layers. I decided on BATCH_SIZE = 10, NUM_EPOCHS = 20, and LEARNING_RATE = .0001.
|
Here are some of my better results.
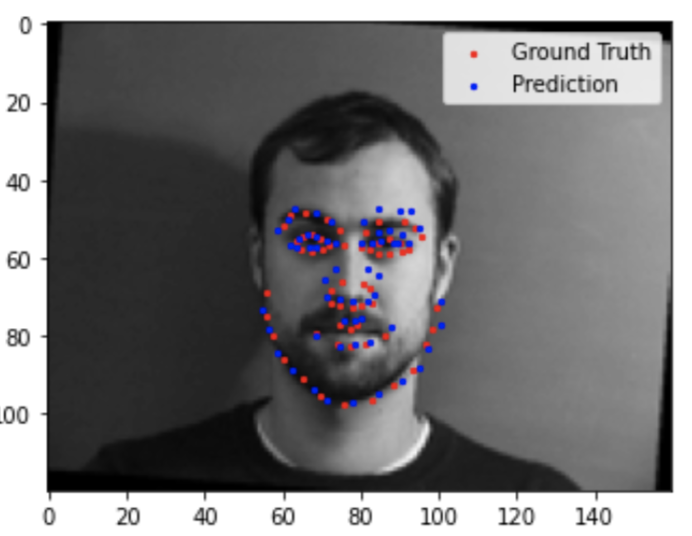
|
|
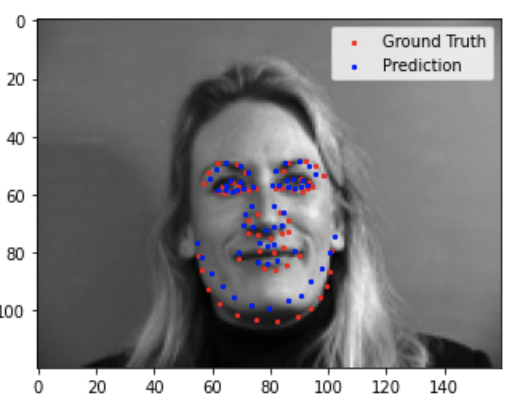
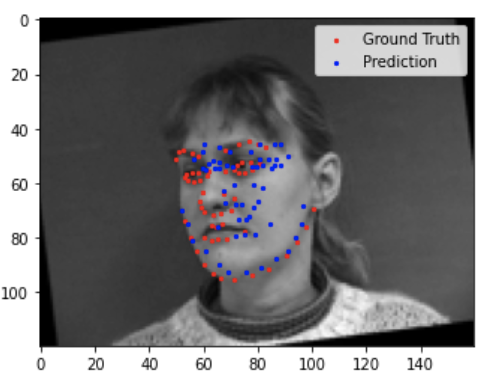
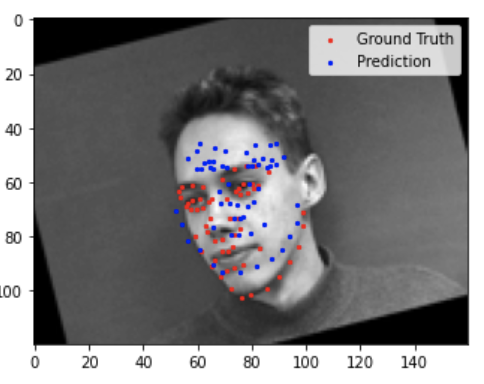
Here are some of my not-as-good results.
|
|
Similar to the previous part, the neural network performed poorly for images where the subject was turned away from the camera, or more offset from the center of the image.
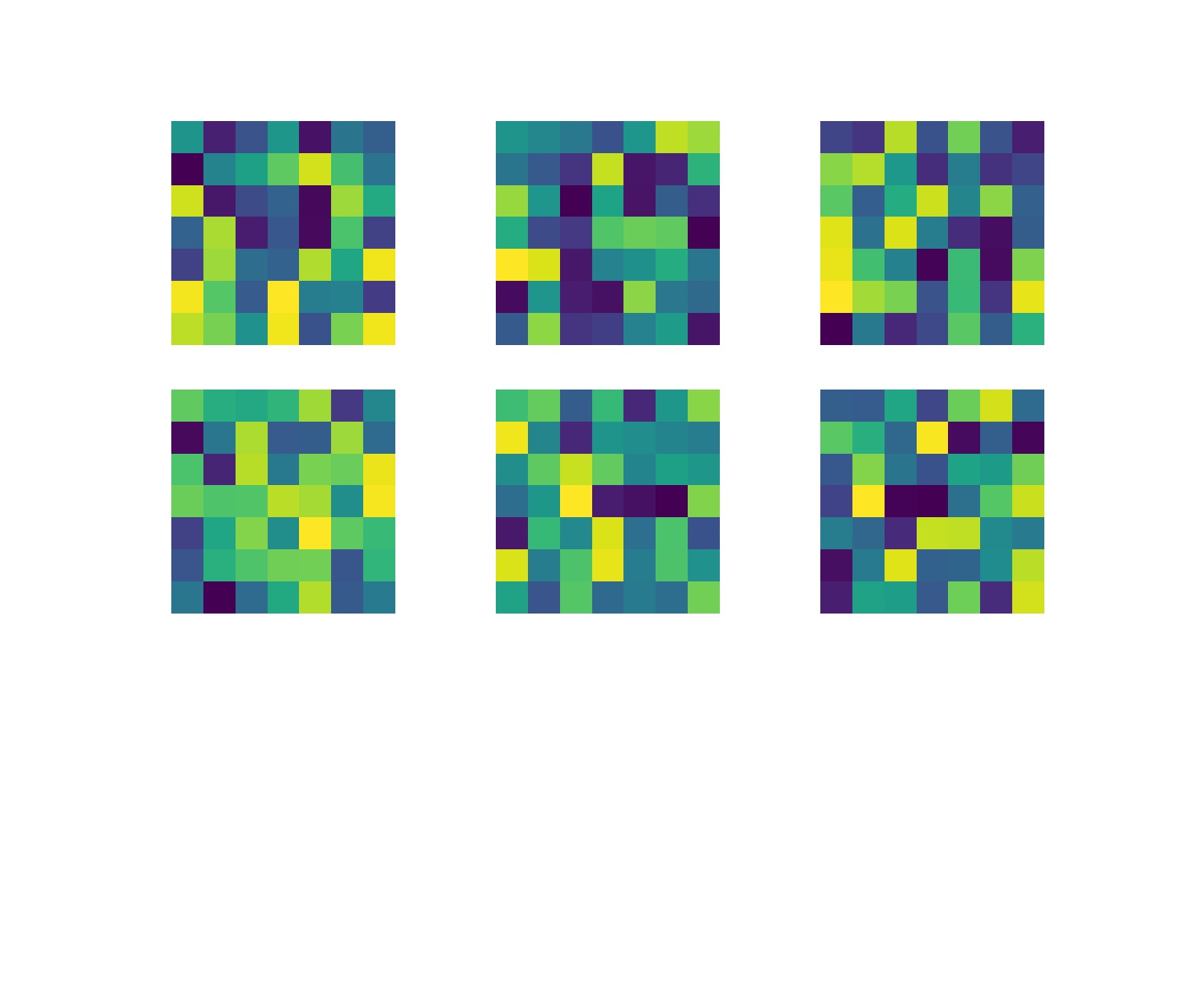
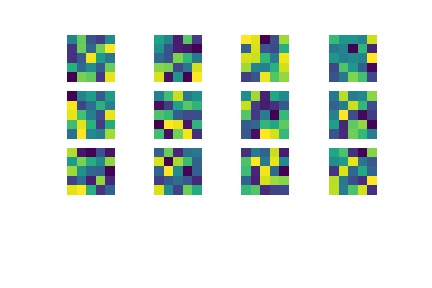
Here is a visualization of my convolutional layers:
|
|
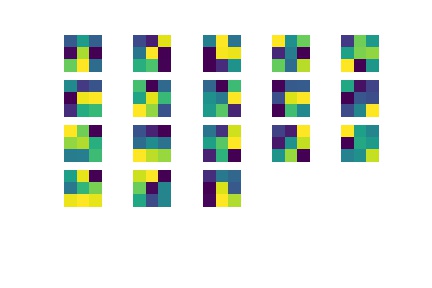
|

|
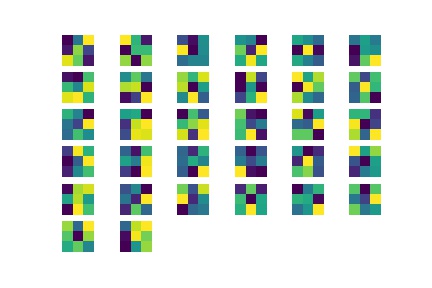
|
I really struggled to get results I was happy with for this part. I tested tried adding more layers, tried increasing and decreasing the learning rate, adjusted batch size, and the size of the convolution layers. If I had more time, I woudl have liked to try more methods to improve my results. I'd like to try more data augmentation approaches including shifting images and adjusting the colors. I'd also like to try implementing an adaptive learning rate. I'd have liked more time to further tune my parameters and try more methods of increasing the quality of my predictions, but I did the besst that I could.