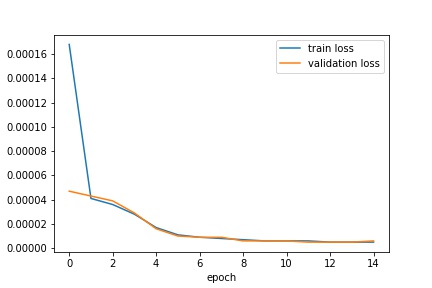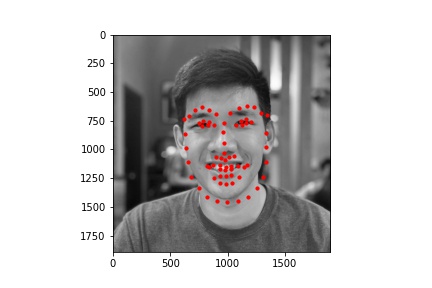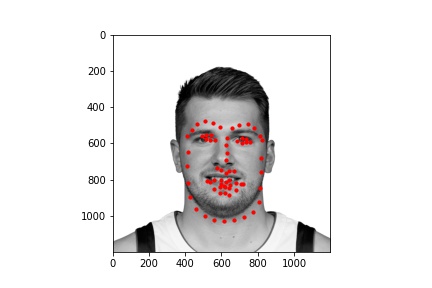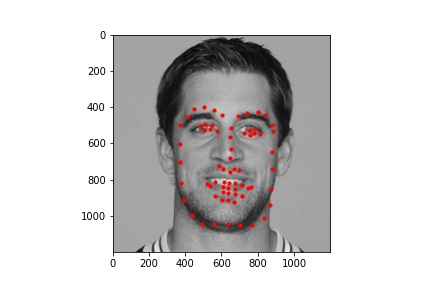
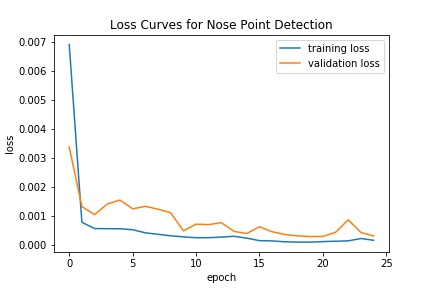
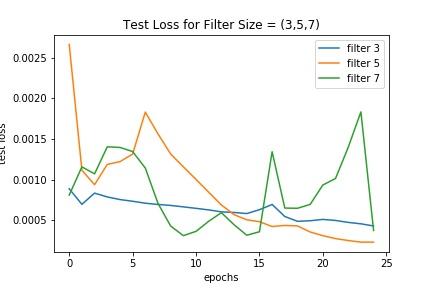
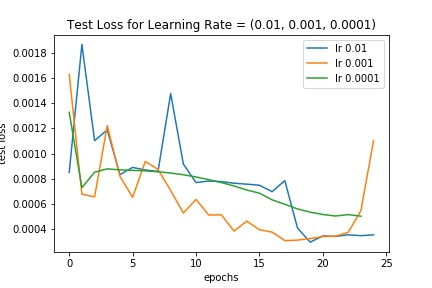
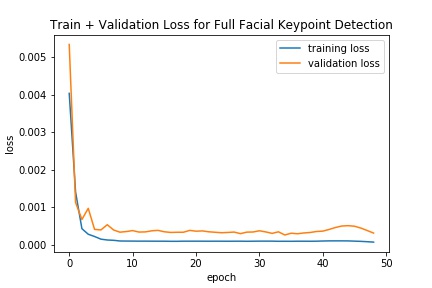
We see that the various hyperparameters don't seem to have a significant effect on results
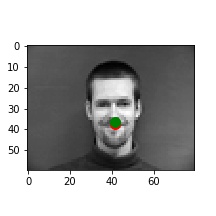
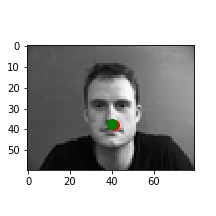
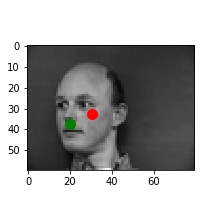

For the architecture, I used the following base layers:
Net( (conv1): Conv2d(1, 16, kernel_size=(7, 7), stride=(1, 1)) (conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1)) (conv3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1)) (conv4): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1)) (conv5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=1120, out_features=256, bias=True) (fc2): Linear(in_features=256, out_features=128, bias=True) (fc3): Linear(in_features=128, out_features=116, bias=True) )
Between each of the convolution layers, I used a ReLU layer followed by a 2x2 max pooling layer. After the last convolution layer, I flatten the output, and pass into a feed forward network with 3 layers, with ReLU between the fully connected layers (but not after the output).
I trained with batch size 32, learning rate 0.001, for 30 epochs using the Adam optimizer and MSE loss.
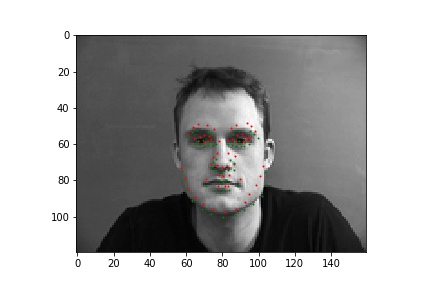
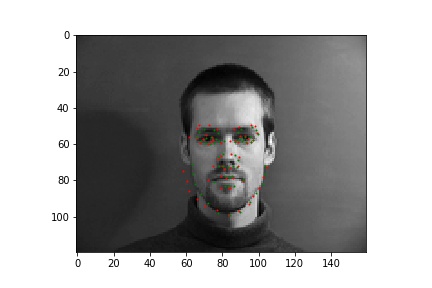
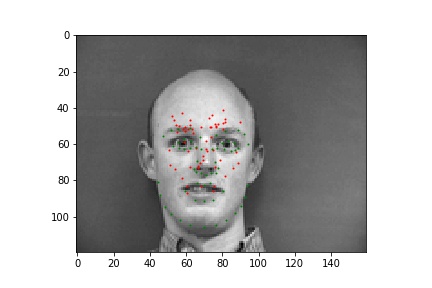
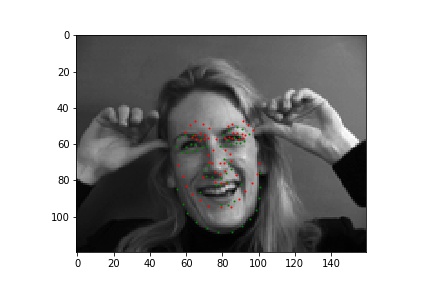
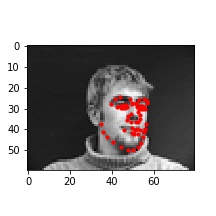
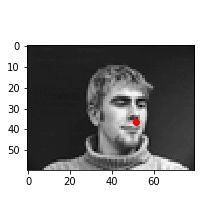
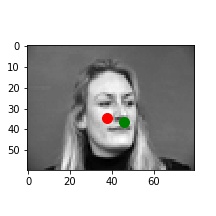
In these cases, it's possible the bald man's head is missing relevant features (i.e. hair). For the picture of the woman, it seems like her hands are up, which might add out of distribution features int othe mage
I used a ResNet-50, and trained on a compute cluster with 4 GPUs using nn.DataParallel. I used a batch size of 128, and a learning rate of 0.001, and trained for 15 epochs.
For data augmentation on the training set, I rotated images -15 to 15 degrees before evaluating, rotating keypoints in the same way.