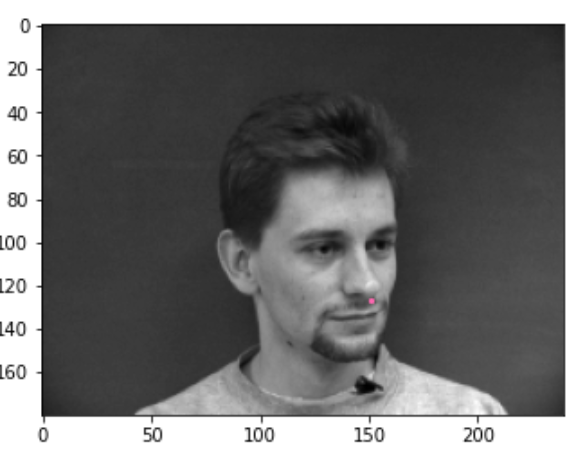
1) Nose keypoint detection
Sampled image from your dataloader visualized with ground-truth keypoints
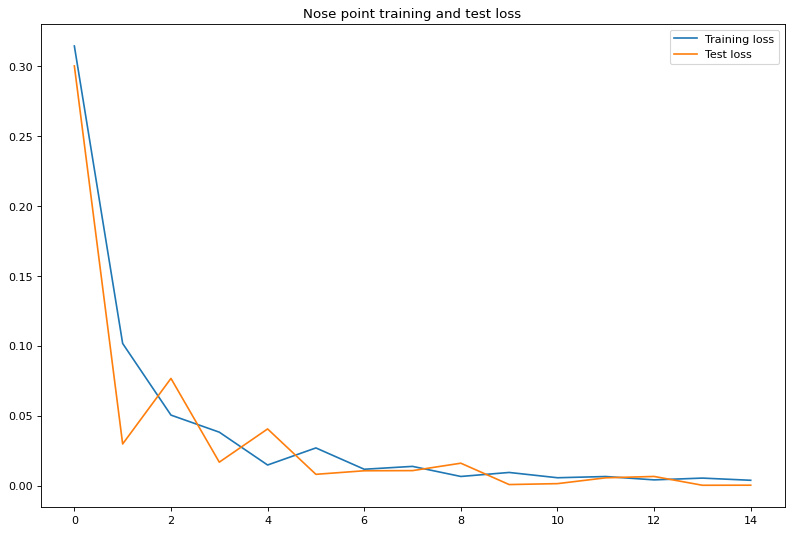
Train and validation MSE loss during the training process
2 facial images which the network detects the nose correctly
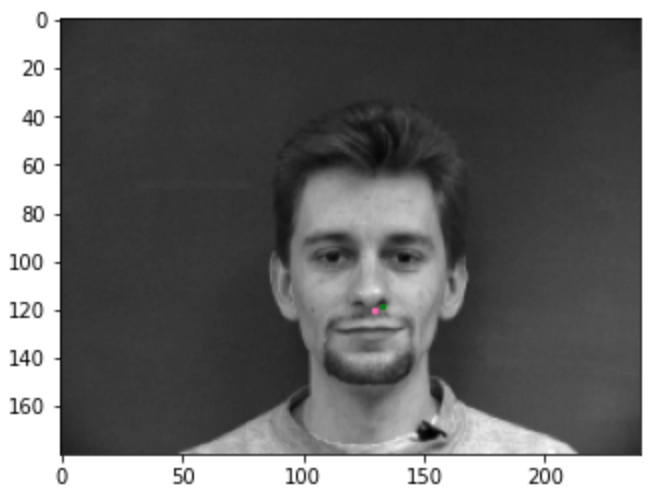
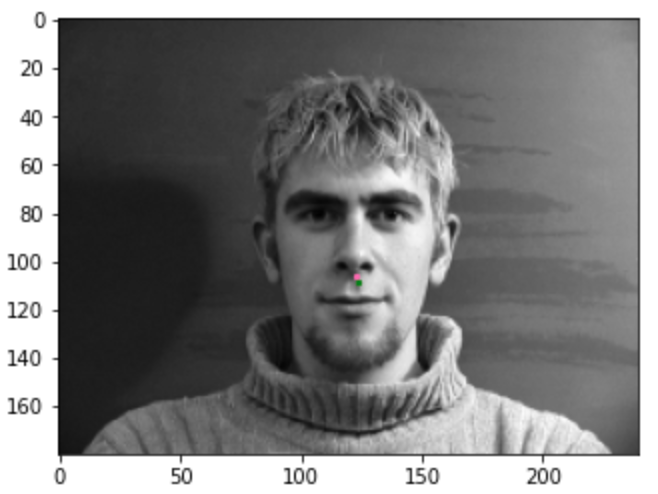 Here, we can see that it performs well on both.
Here, we can see that it performs well on both.
2 more images where it detects incorrectly.


Explain why you think it fails in those cases.
I think that the smiling and the looking away images are harder for the network to fit to, because the network will struggle as it doesn't have enough data in the test set, which is where augmentation will help.
Changing the learning rate to 1e-4
I changed the learning rate to be much lower, and I got the following image
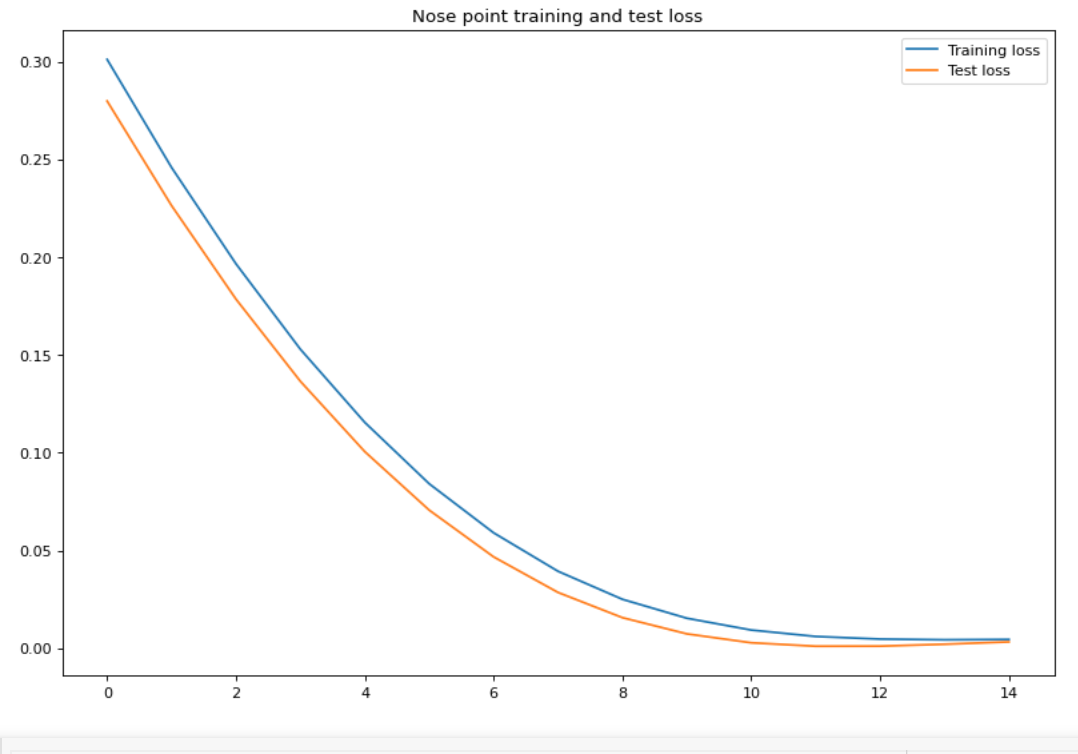
Then I increased the kernel size to 7, which made it decline very steeply in loss.

2) Full Facial Keypoints Detection
Sampled image from your dataloader visualized with ground-truth keypoints.

Model architecture
For this one, I used a simple model. I used the following model:
Net(
(conv1): Conv2d(1, 8, kernel_size=(7, 7), stride=(1, 1), padding=same)
(conv2): Conv2d(8, 15, kernel_size=(5, 5), stride=(1, 1), padding=same)
(conv3): Conv2d(15, 22, kernel_size=(5, 5), stride=(1, 1), padding=same)
(conv4): Conv2d(22, 28, kernel_size=(5, 5), stride=(1, 1), padding=same)
(conv5): Conv2d(28, 35, kernel_size=(3, 3), stride=(1, 1), padding=same)
(fc1): Linear(in_features=5775, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=116, bias=True)
)
I used a learning rate of 1e-3, and a batch size of 8.
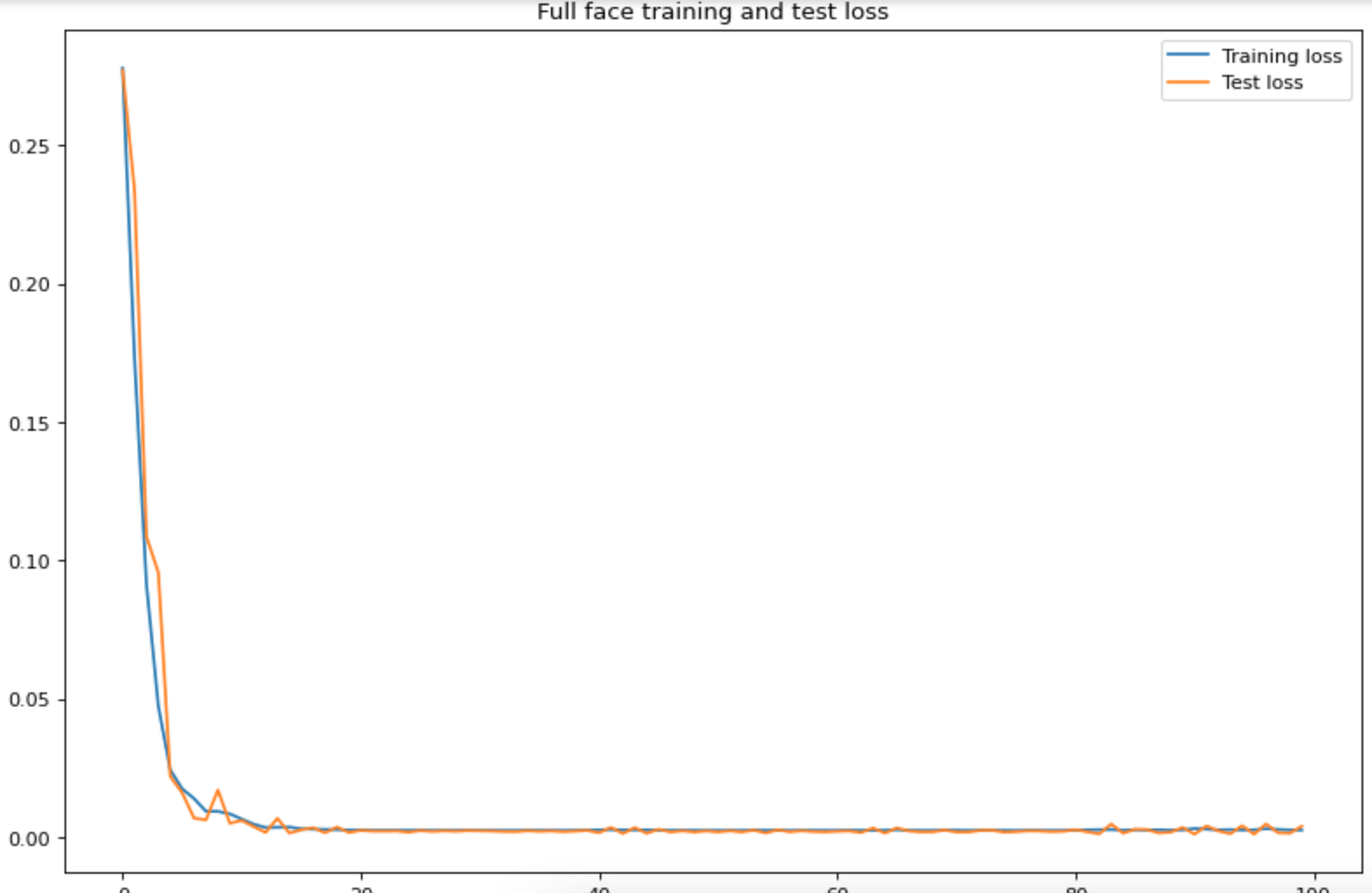
Training and validation loss
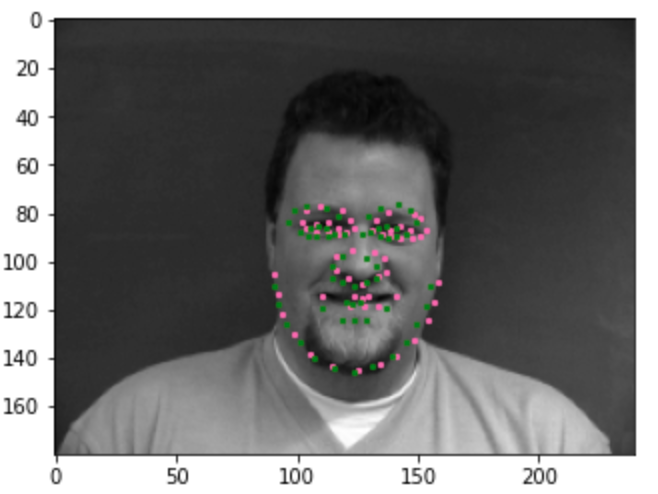
Show 2 facial images which the network detects the face correctly
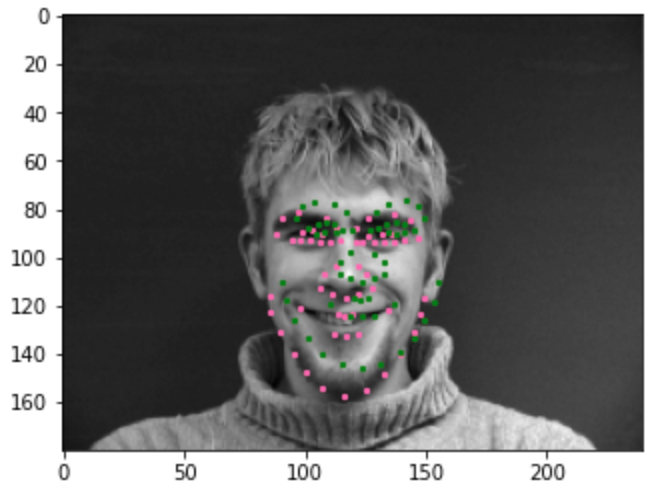
2 more images where it detects incorrectly
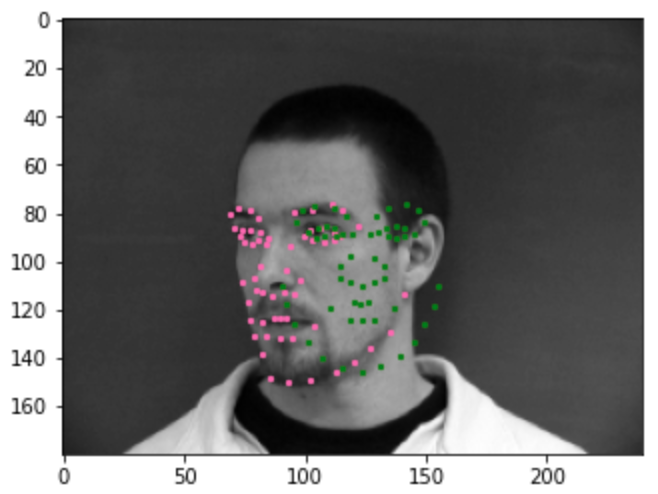
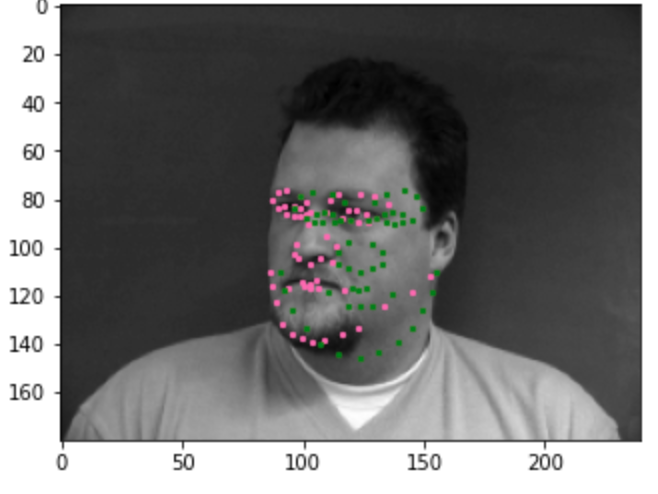
Why did it fail?
It underfits and predicts the average face, it isn't able to fit the images. I think there aren't enough images too, so it isn't able to fit these side turned images. My model is probably not deep enough as well and it is underfitting. I also should train it more.
Visualize the learned filters
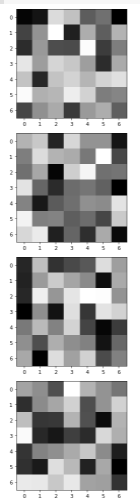
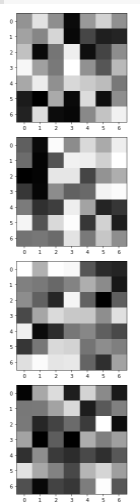
Now let's do some augmentations, let's see the network perform on these. Here are some good examples.
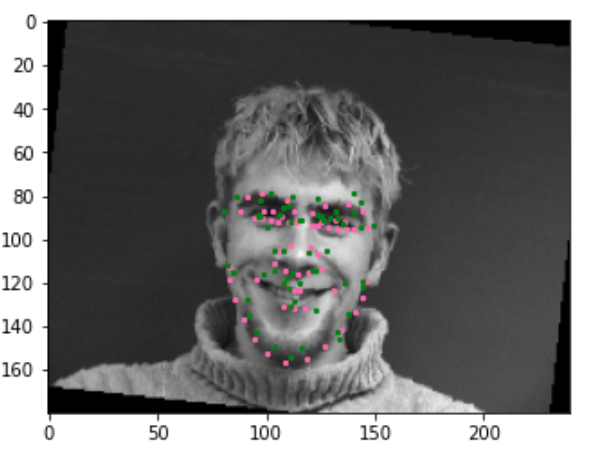
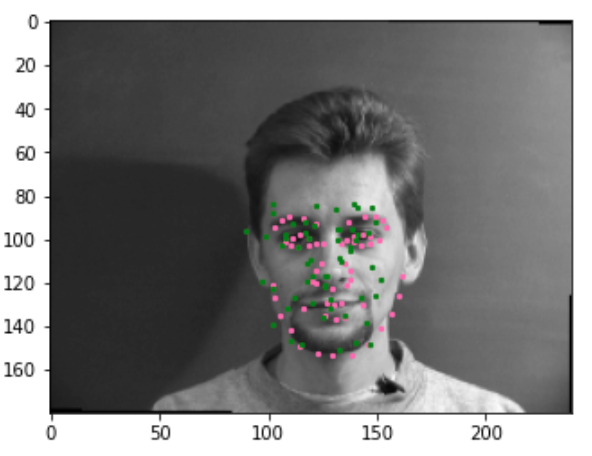
Here are some bad examples.
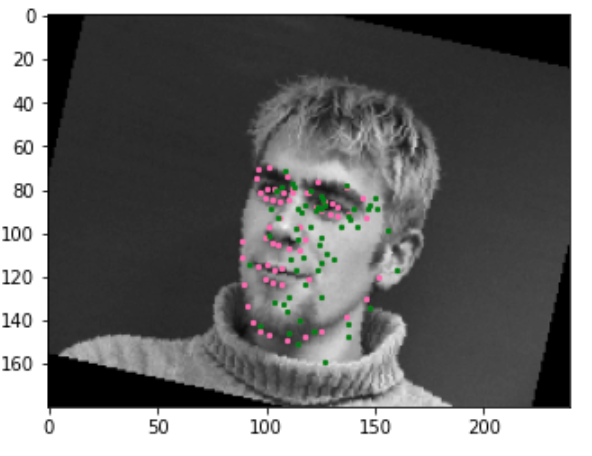
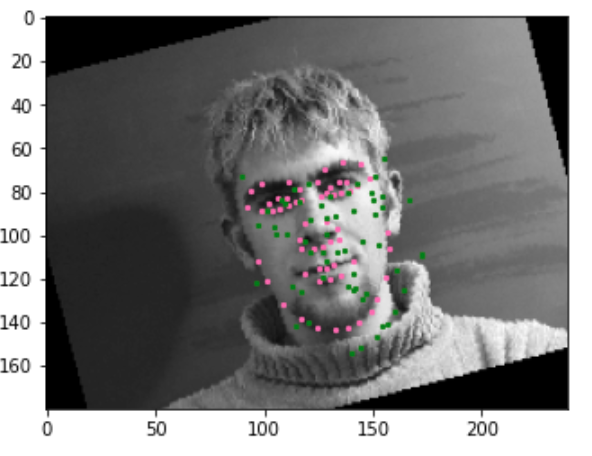 On some rotations, this obviously doesn't perform very well. Overall, it performs better with teh augmentation, but the model probably isn't deep enough to capture the rotations well.
On some rotations, this obviously doesn't perform very well. Overall, it performs better with teh augmentation, but the model probably isn't deep enough to capture the rotations well.
Some common issues with these models I think are tehre
I think that L2 loss will incentize an average face, which is annoying, and hard to get around. Maybe an L1 loss?
3) Train With Larger Dataset
I did horrible on the kaggle competition, and my name on it was Michael Jayasuriya. I got around 80, which was close to the bottom for MSE. I used the ResNet-18 without pretraining,
and I trained it with a learning rate of 1e-3, and a batch size of 256. I changed the input layer to have 1 input channel, and the last layer to have 136 instead of 512 output parameters.
Visualize some images with the keypoints prediction in the testing set
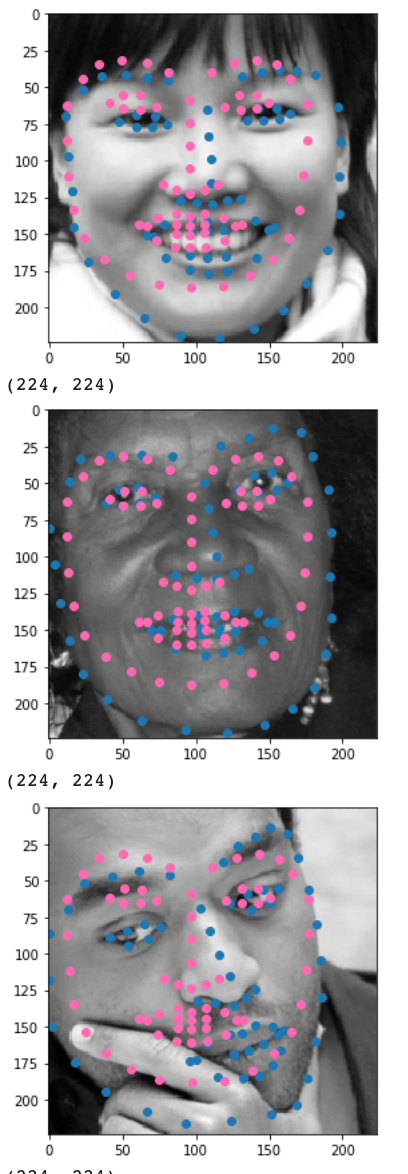
Trained model on no less than 3 photos from your collection
