CS 194-26 Project 5
Kyle Hua, CS194-26-AGX
Facial Keypoint Detection with Neural Networks
For this project, I implemented a CNN to detect facial feautures of various images.
Part 1 Nose Tip Detection:
Dataloader
In the first part, we want to design a CNN that detects the noses of faces from the IMM Face database. There are a total of 40 people. The faces have 6 images each, for the test set we use the first 32 faces for a total of192 images. The last 8 people will be used for the test set for a total 48 images. I implemented a dataloader to load in the return each image and their corresponding nose point. The dataloader resizes the images into a smaller size (80x60), grays them, and then normalizes the pixels from 0-255 into 0-1. Here are the results of the dataloader.
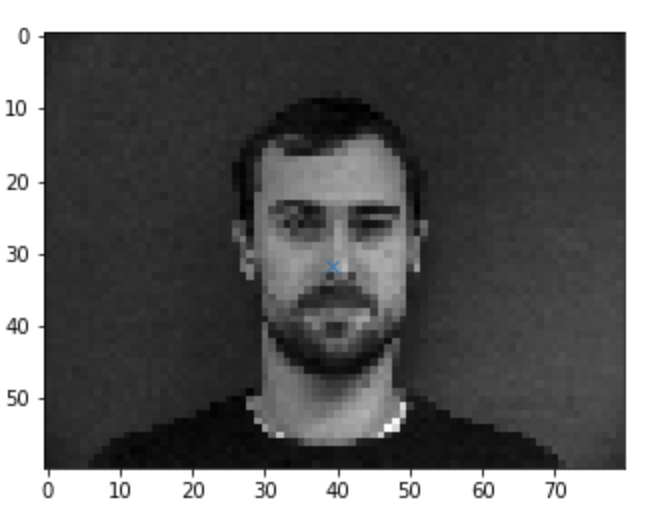

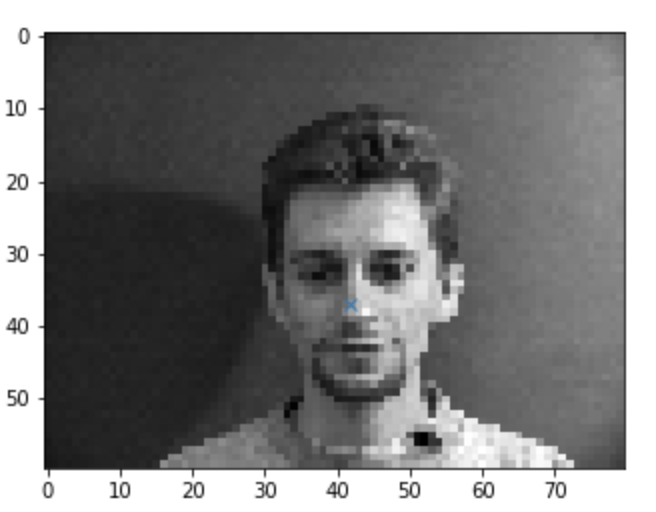
CNN
With the dataloader set, I then designed a CNN to detect the nosepoints. For the CNN, I used three convolutional layers. 12 7x7, 16 5x5, 32 3x3 for each conv layer respectively. Then after the conv layers, there are two linear layers with the first having an input size of 896 and the second with an input size of 256. Every conv layer is followed by a ReLU followed by a maxpool. Only the first linear layer has ReLu applied to it.
The specifications are below:
Net(
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(12, 16, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=896, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=2, bias=True)
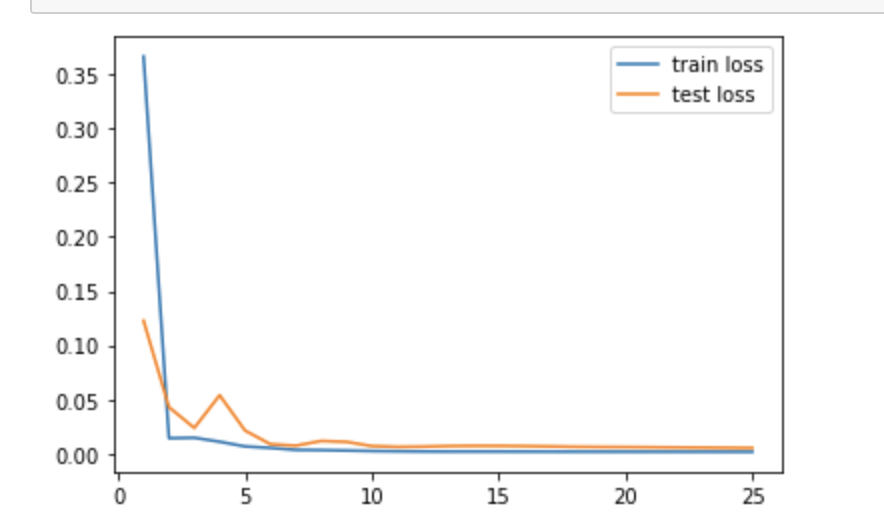
)The results of the training are below after running for 25 epochs with a learning rate of .001:
Here are the examples of images that work:



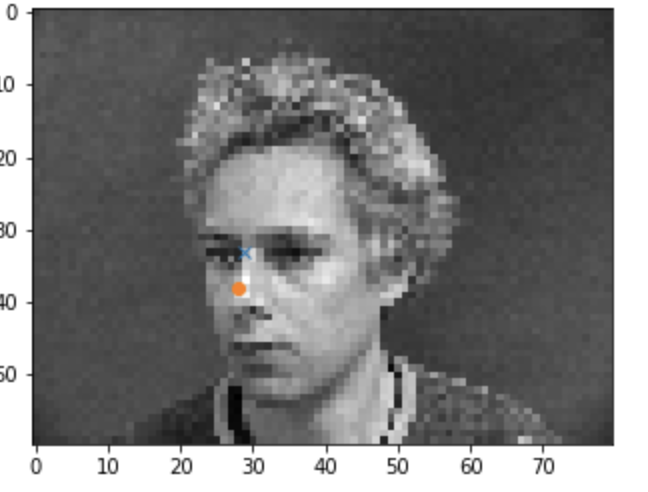
Examples of images where it doesn't work well:

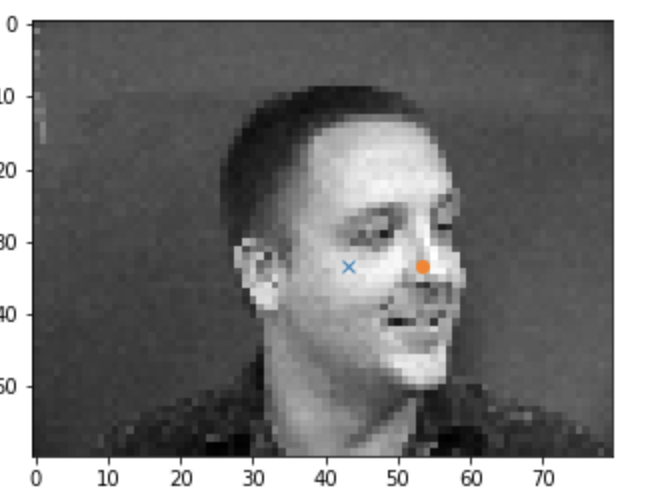
The poor nose recognition is probably the result of randomness of the dataloader and images. The lighting or direction of the faces would also affect it.
Part 2 Full Facial Keypoints Detection:
In the next part, we expand from just detecting nose points to a more complete facial points.
Dataloader
This part still uses the same faces as part 1. The dataloader will return all 58 facial points for each face. However since there are not a lot of faces in the dataset, we will need to augment the images and points to provide more variety and information to the neural network.
I augmented the images by randomly changing the hue and saturation, rotating it, and shifting it. Below are some examples of the image augmentations:


Because the we are changing the the images, we need to adjust their corresponding facial points as well. This can be done by takeing the affine transformation matrix used to augment the images and multplying it with the corresponding points. Below are examples of points augmentation:

Of course after the images need to be grayed and resized (260x180):
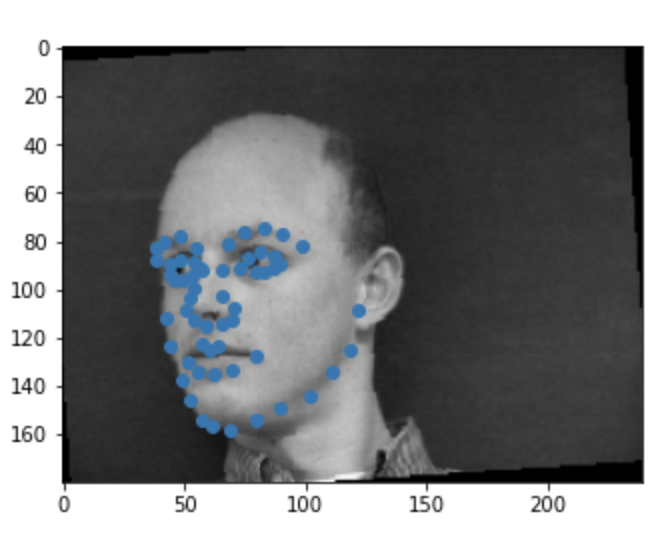
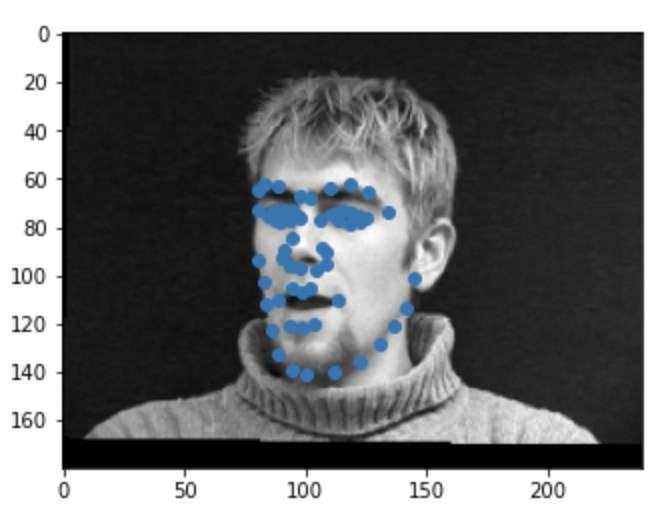
CNN
Because there are more points to detect, we need to use a bigger image size from last time (260x180) and a larger network. This time I used 5 conv layers: 8 7x7, 16 5x5, 24 5x5, 28 3x3, 35 3x3. Each conv layer is followed by Relu and a max pool except for the last whichdoesn't have the maxpool applied to it. Lastly, there are 3 linear layers taking in 2100, 512, and 256 inputs correspondly. The neural net outputs 116 elements to form 58 points.
The specifications are below:
fullNet(
(conv1): Conv2d(1, 8, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(8, 16, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(16, 24, kernel_size=(5, 5), stride=(1, 1))
(conv4): Conv2d(24, 28, kernel_size=(3, 3), stride=(1, 1))
(conv5): Conv2d(28, 35, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=2100, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=256, bias=True)
(fc3): Linear(in_features=256, out_features=116, bias=True)
)The results of the training are below after running for 25 epochs with a learning rate of .001:
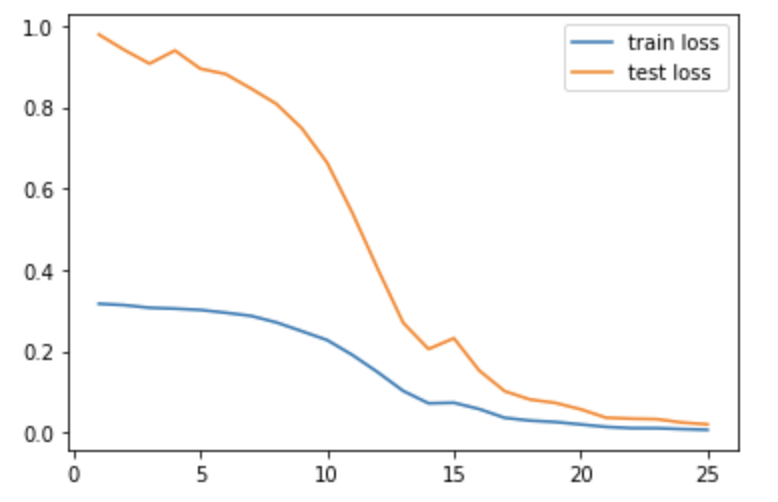
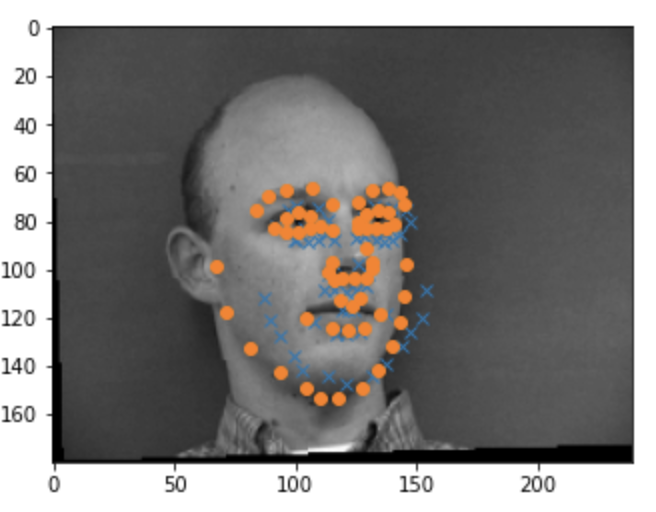
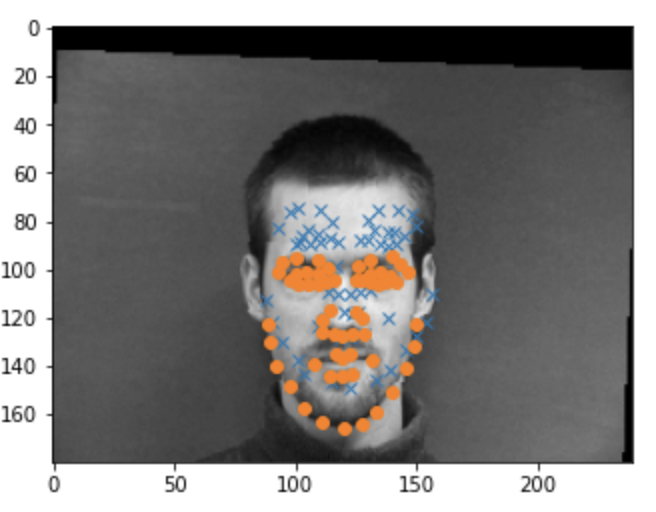
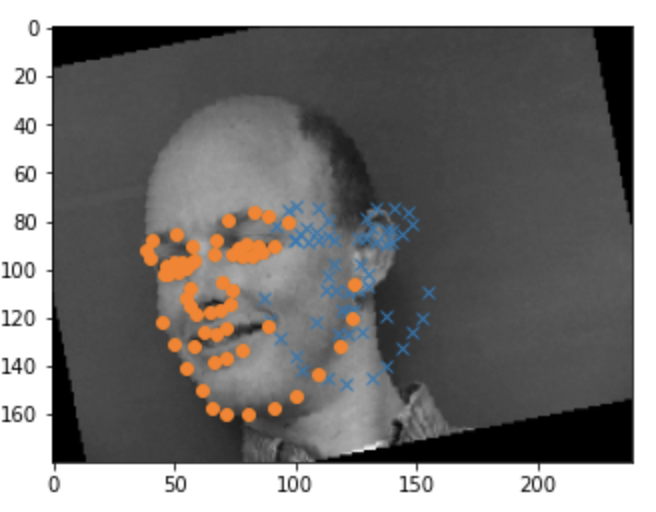
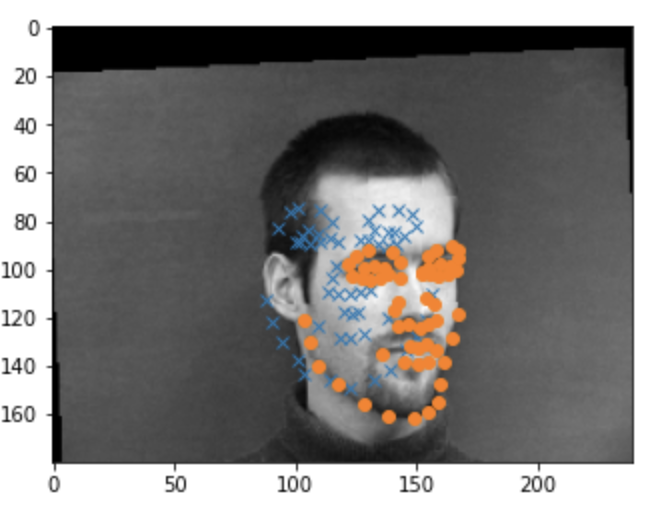
Overall the model did poorly and often ouputed very simliar points.
Filters for first layer (8 7x7):

Filters for second layer (16 5x5):

Filters for third layer (24 5x5):

Filters for fourth layer (28 3x3):

Filters for fifth layer (32 3x3):

Part 3
Did not attempt.