Part 1. Nose Tip Detection
1. Dataloader. The dataset had 240 facial images of 40 persons and each person has 6 facial images in different viewpoints. We split the dataset into training (32) and test sets (8). First, we converted images into greyscale (so that the channel input in CNN would be 1), and normalized float values. We also resized images to (80,60).



2. CNN Architecture. For my final model I used 3 convoluational layers, changing the kernel sizes from (2,2) and (5,5) with the consistent padding (2,2). All of them were followed by ReLU and maxpooing of size (2,2). I used MSE loss function and Adam optimizer with the learning rate of 0.0005, trained on 25 epochs.
- Conv1: Conv2d(1, 12, kernel_size=(2, 2), stride=(1, 1), padding=(2, 2))
- Conv2: Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
- Conv3: Conv2d(12, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
- Fc1: Linear(in_features=1120, out_features=200, bias=True)
- Fc2: Linear(in_features=200, out_features=2, bias=True)
Here are the best results:


Here are the worst results that might have failed due to head rotations in the images and not standing in the middle of the images, on the majority of training samples it might have been the case that the noses were in the center:


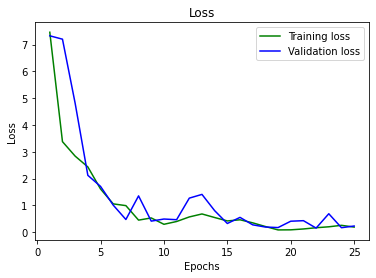
3. Training and Validation Accuracy. Loss on 25th epoch: 0.192(training), 0.232(validation).
Part 2. Full Facial Keypoints Detection
1. Dataloader. The dataset had 240 facial images of 40 persons and each person has 6 facial images in different viewpoints. We split the dataset into training (32) and test sets (8). First, we converted images into greyscale (so that the channel input in CNN would be 1), and normalized float values. We performed data augmentation on images in order to prevent the model from overfitting. More specifically, we used ColorJitter to enhance brightness, Rotation and Horizontal Flip with converted landmarks respectively.



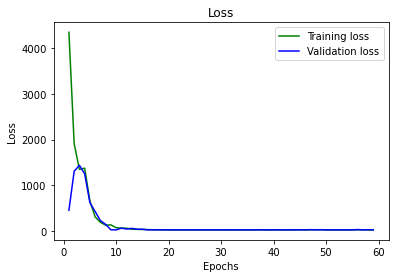
2. CNN Architecture. For my final model I used 6 convoluational layers, changing the kernel size (2,2) with the consistent stride (1,1). All of them were followed by ReLU (non-linearity), and the majority of the layers were followed by maxpool (2,2) except for the last and first layers. We trained on 60 epochs, using MSE loss function and Adam optimizer with the learning rate of 0.05.
- Conv1: Conv2d(1, 16, kernel_size=(2, 2), stride=(1, 1))
- Conv2: Conv2d(16, 16, kernel_size=(2, 2), stride=(1, 1))
- Conv3: Conv2d(16, 32, kernel_size=(2, 2), stride=(1, 1))
- Conv4: Conv2d(32, 128, kernel_size=(2, 2), stride=(1, 1))
- Conv5: Conv2d(128, 128, kernel_size=(2, 2), stride=(1, 1))
- Conv6: Conv2d(128, 32, kernel_size=(2, 2), stride=(1, 1))
- Fc1: Linear(in_features=96, out_features=500, bias=True)
- Fc2: Linear(in_features=500, out_features=116, bias=True)p2-
Here are the best results:


Here are the worst results that might have failed due to head rotations in the images and also facial shifts to the left/right. It might be worth to perform data augmentation in the future.


3. Learned Filters. Row one: layers 1-3, row two: layers 4-6.
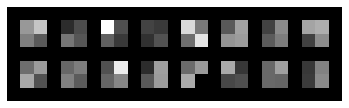
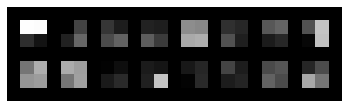
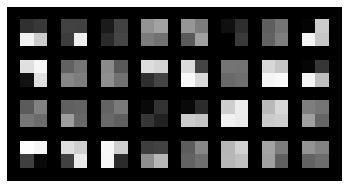



Part 3. Larger Training Set
1. Dataloader. The dataset needed a croppping around bounding boxes and resize to that scale so that the training would be performed on those images. We have also needed to update facial keypoints. I had errors on downloading class images, so worked with the same dataset that i found online.



2. CNN Architecture. Training on 6666 images, here we used ResNet18 CNN architecture and Google Collab GPU. I used MSE loss and Adam optimizer with the learning rate 0.0001. Modified the first layer, so that the input channel would be 1 bc of greyscale images.

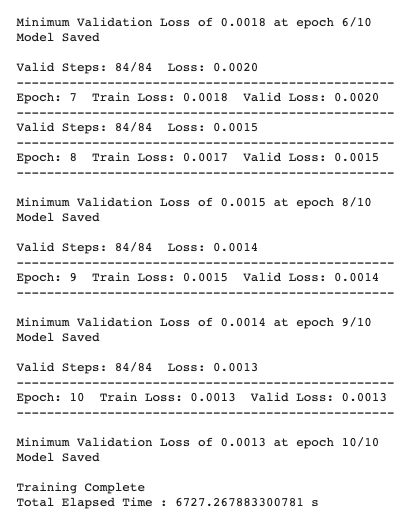
Here are the results:
