Project 5: Abel Yagubyan
Nose Tip Detection: Dataloader Samples
I wrote my own Dataloader that took in the images and the corresponding nosepoints, which initially changes the image into grayscale and normalize to a float value between -0.5 and 0.5. After that, we resize the image to 80x60 resolution and use the Dataloader to load in the images and visualize the nosepoints:



Architecture
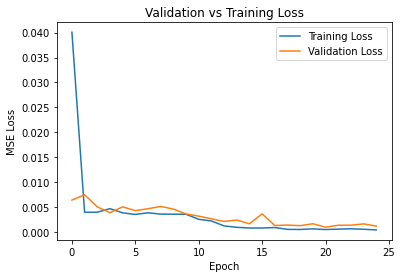
The CNN that I used ran 25 epochs using MSE via the Adam optimizer with learning rate of 1e-3. Here is the architecture for the CNN that I used: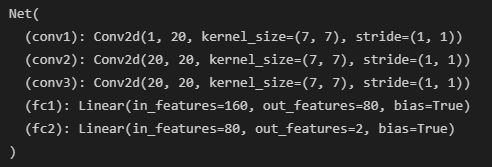
Changing hyperparameters
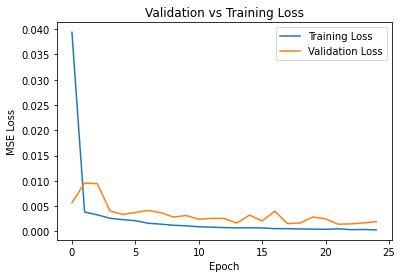
I varied the kernel size to 5x5 and also varied the learning rate to 1e-4, for which the differences are displayed below, respectively (left to right).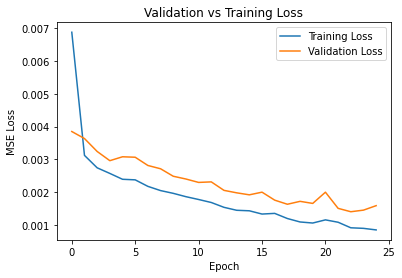
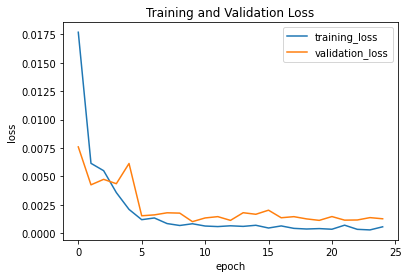
Other than a slight difference in how the validation and training losses are, they are quite similar to each other. I ended up using a 7x7 Kernel with a 1e-3 learning rate. Here is how the loss graph looked like:
Nosetip Results
After having trained our model, here are the 2 nice and 2 bad predictions (top 2 are good, bottom 2 are bad).
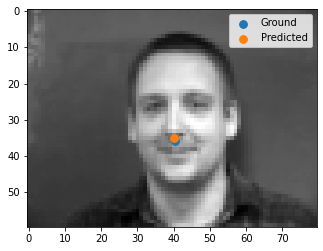

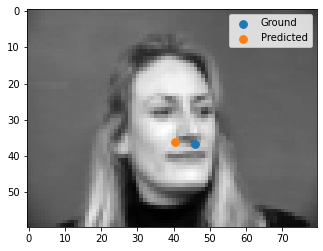
It's obvious that the images with the individuals facing away is what causes a bad prediction, otherwise the predictions pretty good!
Facial Keypoints Detection: Dataloader Samples
I wrote my own Dataloader that took in the images and the corresponding 58 keypoints, which initially changes the image into grayscale and normalize to a float value between -0.5 and 0.5. After that, we resize the image to 240x180 resolution, tilt the image randomly by +-15 degrees and use the Dataloader to load in the images and visualize the keypoints:



Architecture
The CNN that I used ran 25 epochs using MSE via the Adam optimizer with learning rate of 1e-3 (batch size 1). Here is the architecture for the CNN that I used: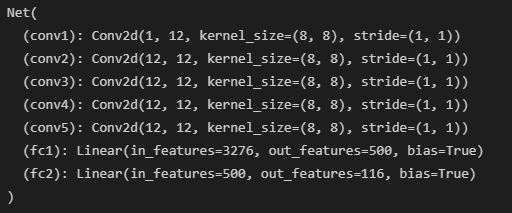
Facepoints Results
After having trained our model, here are the 2 nice and 2 bad predictions (top 2 are good, bottom 2 are bad).



As the first part, it's obvious that the images with the individuals facing away is what causes a bad prediction, otherwise the predictions pretty good!
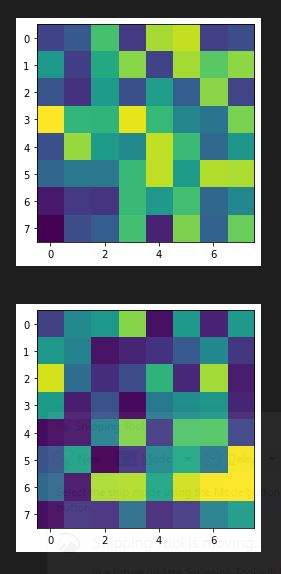
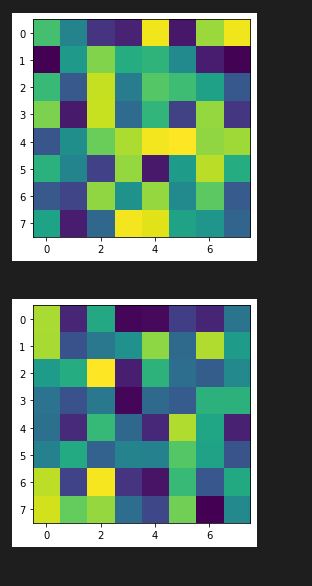
Learned Features
Here are some of the learned features from the CNN model (from conv1, conv2, and conv3):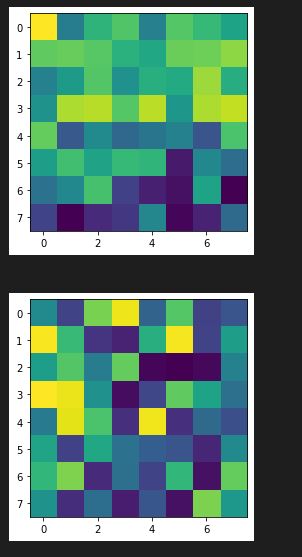
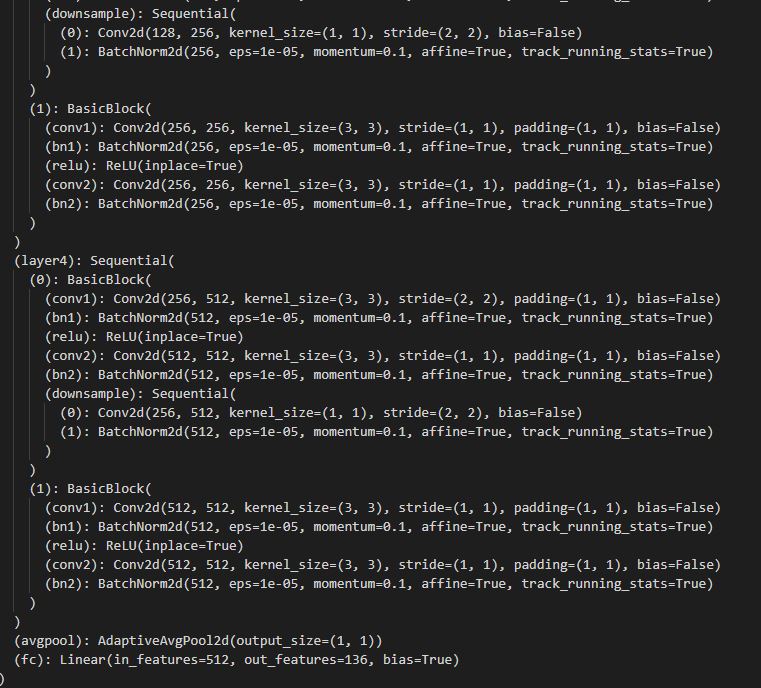
Larger Sample: Architecture
The CNN that I used was ResNet18 which used 10% of the dataset as validation, and the remainder for training. Moreover, I had to modify ResNet18's first layer of the network since it didn't work with Grayscale images, then I changed the output of the network to be the 136 points flattened out along with a new linear layer. I ran this for 5 epochs using MSE via the Adam optimizer with learning rate of 3e-4 (batch size of 64). Here is the architecture for the CNN that I used: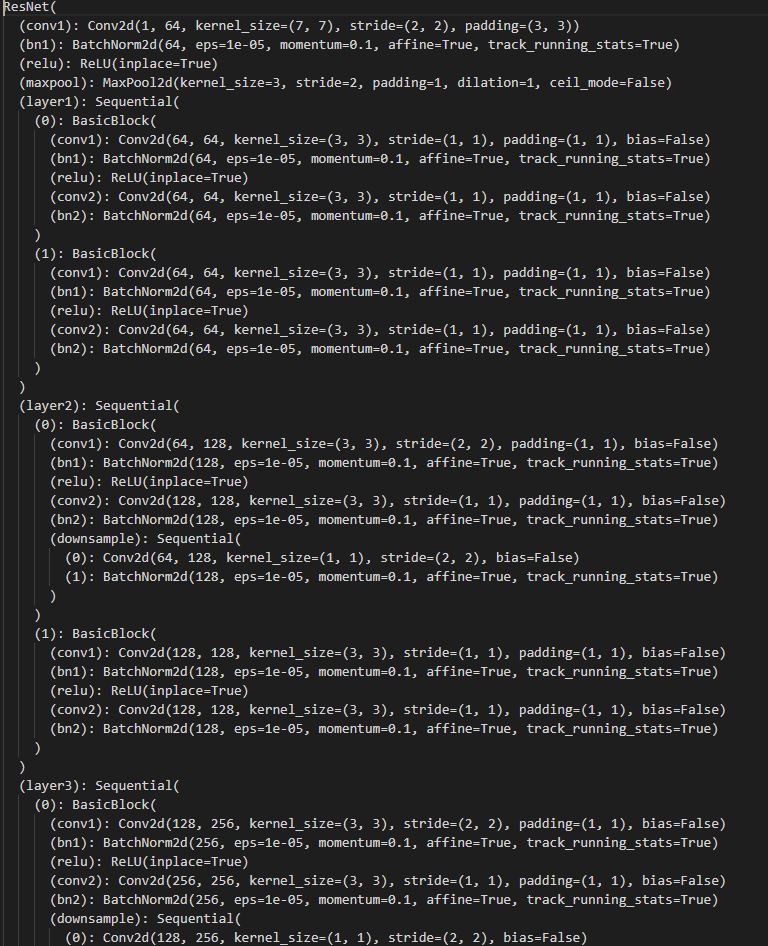
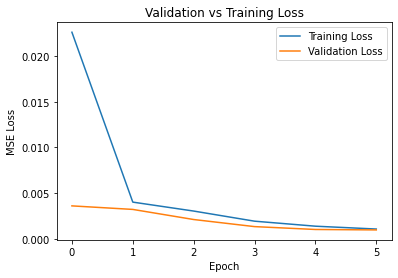
Facepoints Results
After having trained our model, here are some results on the test set.
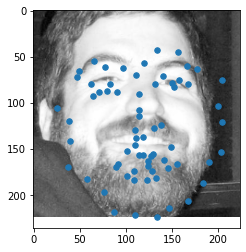


Lastly, here are some images on my own photos (decided to go with the Danes collection images):



Bells and Whistles
Using our automatic facial keypoints detection, I integrated these automatic detections onto my Project 3 code, where I automatically morphed individuals from the Danes collection using our CNN models. Here is a final output GIF of how it looks like (link attached due to large size).VIDEO HERE