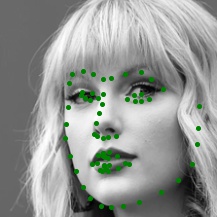
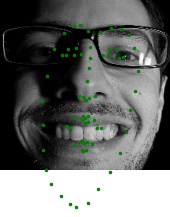
In this part, I am applying a simple CNN to the IMM face database to detect nosetip. The implementation mainly contains three major components: Dataloader implementation, CNN construction, and CNN training.
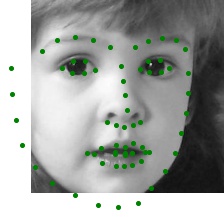
Here are some example results of my data loader:
Here is the first generation architecture of my NN:
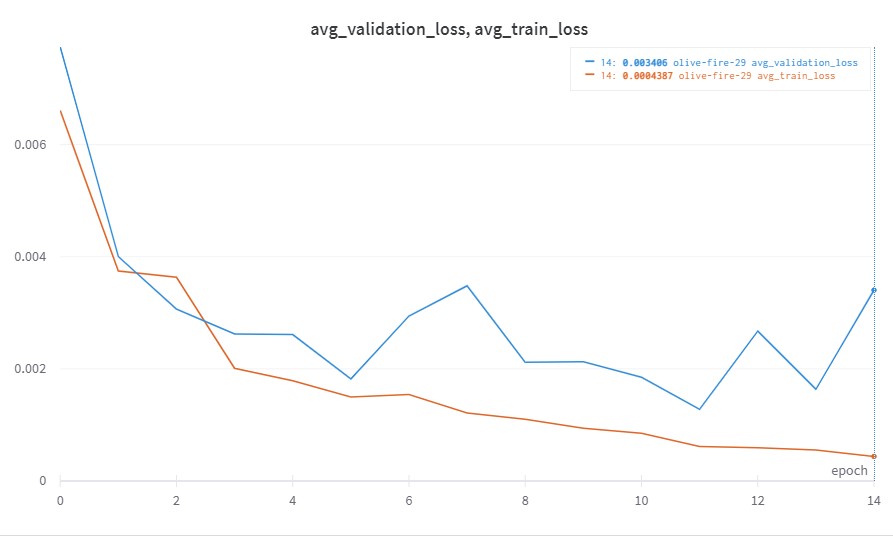
Initially I trained this NN with learning rate of 1e-3 on Adam optimizer with epoch equal to 15, but the result is not that good, as you can see the validation loss quite jumps a lot.
To optimize my NN, I updated into this second generation architecture (mainly modified the channel size of the Conv layers):
And in this interation, I also updated the learning rate to 1e-4 and added the number of epoch to 30, here is the loss function graph:


Here are two result that the NN failed to generate a nice result:






Since the job become a lot more complicated than nosetip prediction, I deepened the NN model on top of previous achitecture (added to 5 conv layer), here is the new one:
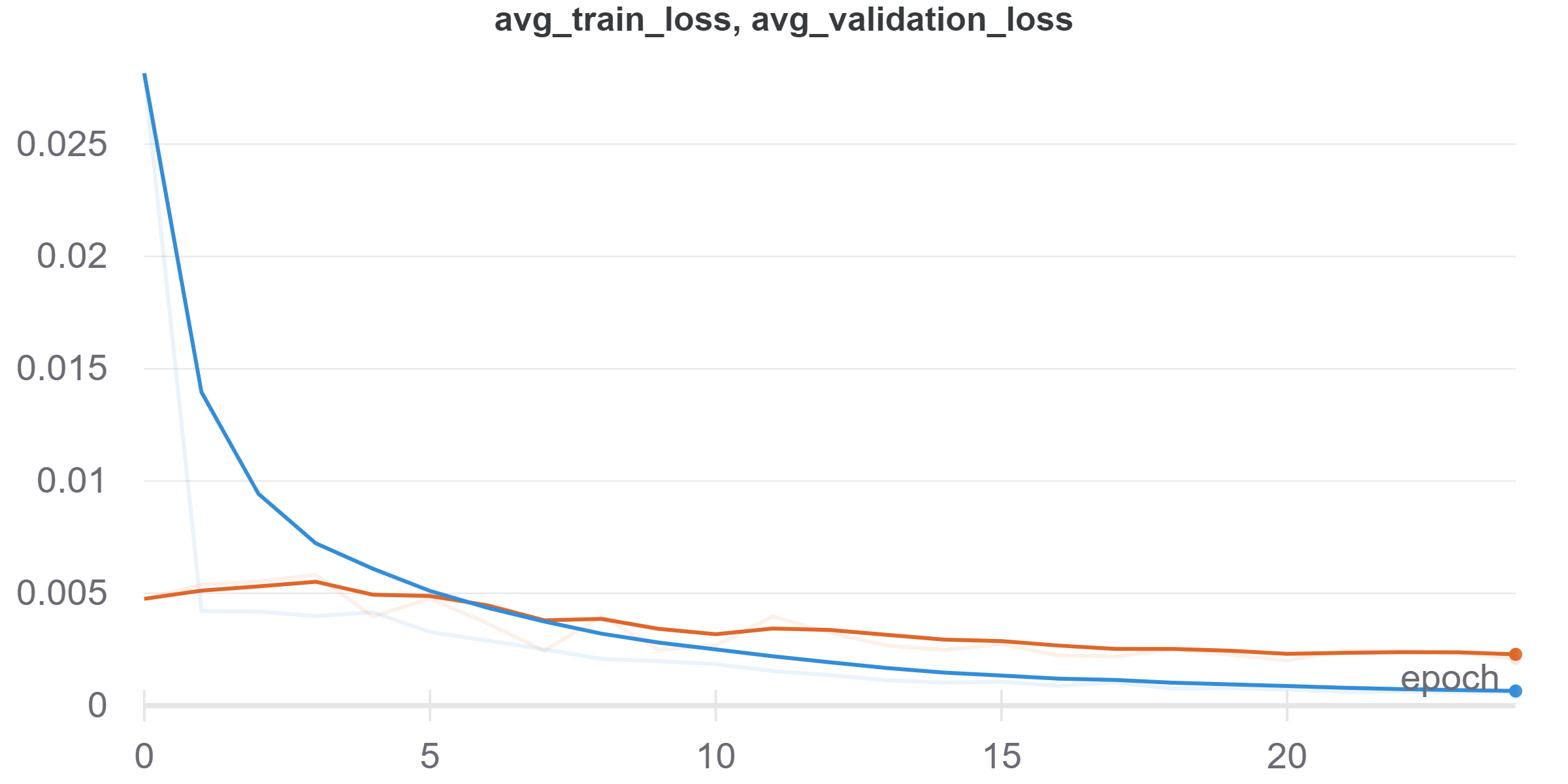
For this model, I picked MSELoss as evaluation method, and Adam optimizer with lr=0.0025. I trained the model for 100 epoches, during the optimization process I was mainly looking at the shapre of learning rate curve and compare it with the sample on 231n's website, and in the end I found 0,0025 might be the best one.
Here is the train loss and validation loss graph I got:
Here are success case I picked from the prediction result:




And here are the learned filters from my NN:



After the warm up, now in part 3 we are kind starts the real work: with large dataset and deep NN
The team name I used to submit for Kaggle competation is "Tiancheng Sun", and my public score (MAE) is 9.12399. At first, I really met some big trouble at first -> no matter how do I adjust my NN model, the network always cannot give good prediction. Therefore, I decided to use the debug method suggested by Prof. Kanazawa -> Use only one image and check if the NN can remember it. And it turns out, the problem is located within my dataloader! The data augumentation I applied is way too extreame so the NN simply give up and decided to output the average result all on the cental line.

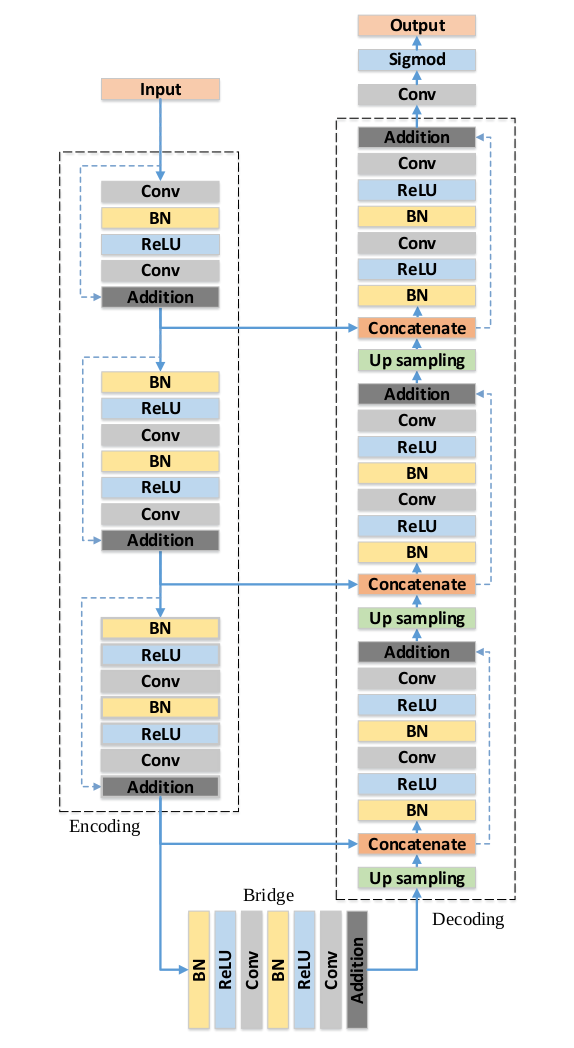
But also because of this process, I implemented a lot of NN architecture into this project, which includes Resnet18, Resnet50, Resnext50, and ResUNet. Since it will take too much space if I report all of their achitecture at here, I only post the ResUnet's architecture here since it is the NN I chose to use at the end:
Here is the three layers I added ontop:
(fc1): Linear(in_features=50176, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=512, bias=True)
(fc3): Linear(in_features=512, out_features=136, bias=True)
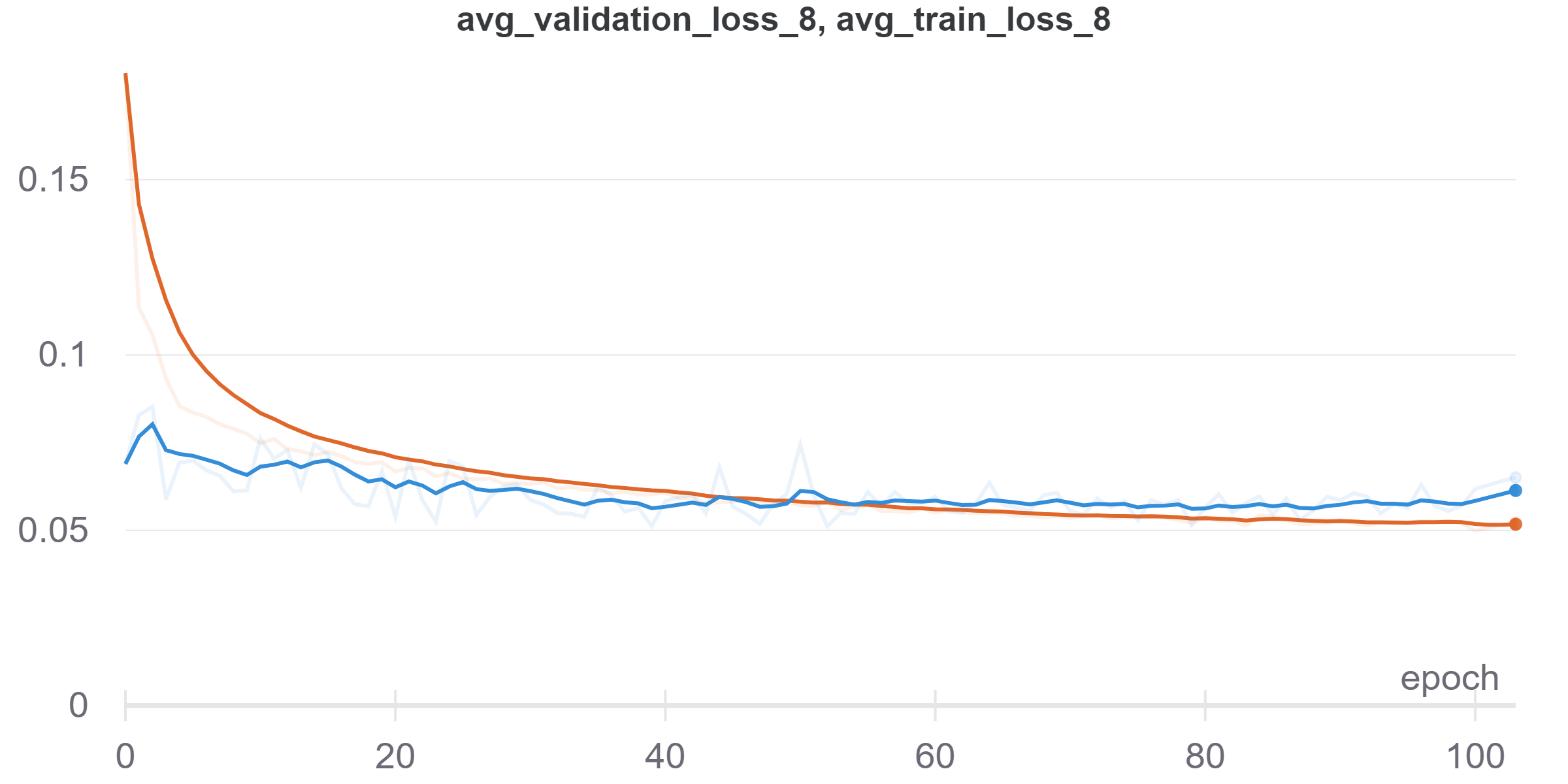
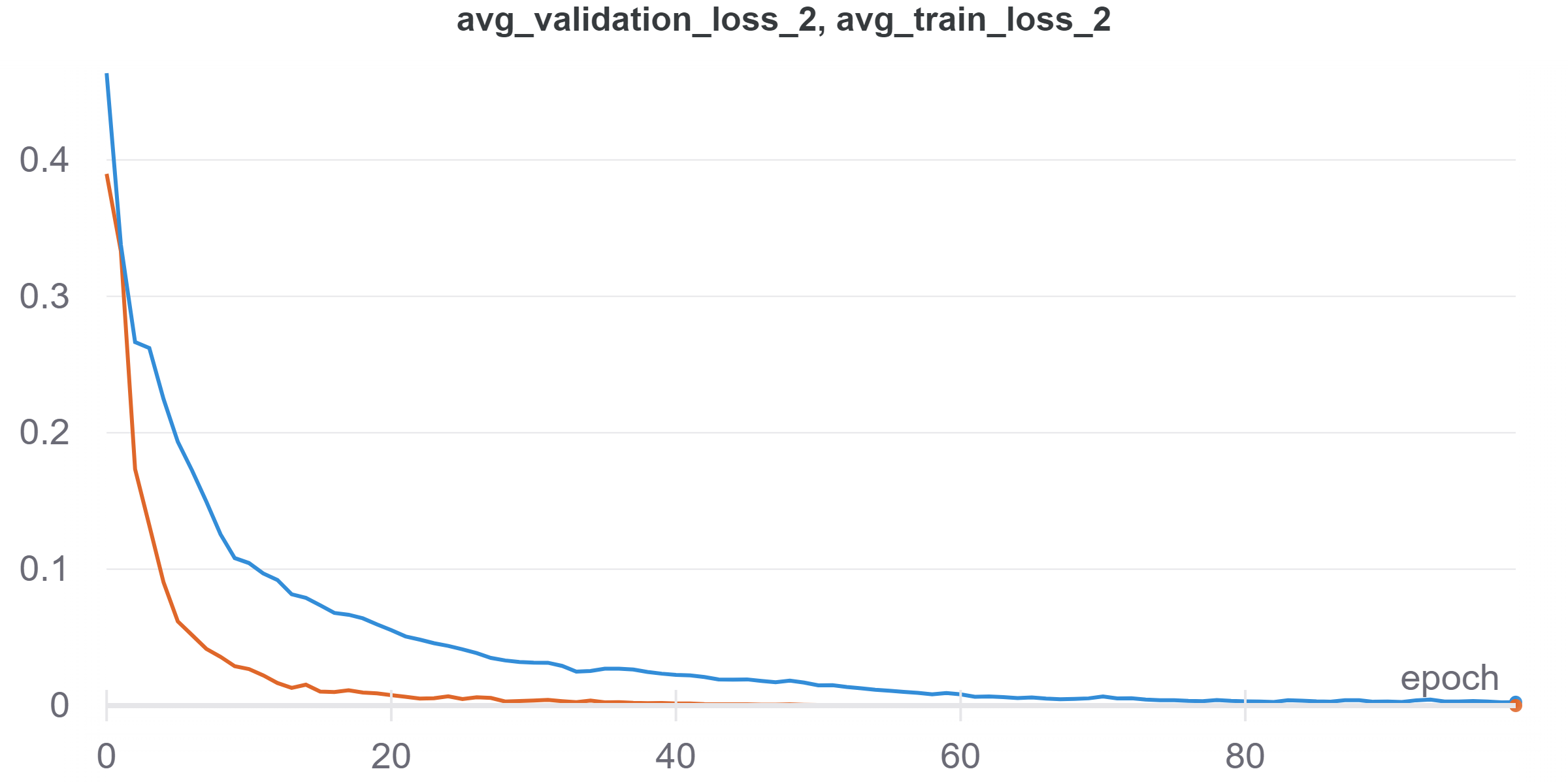
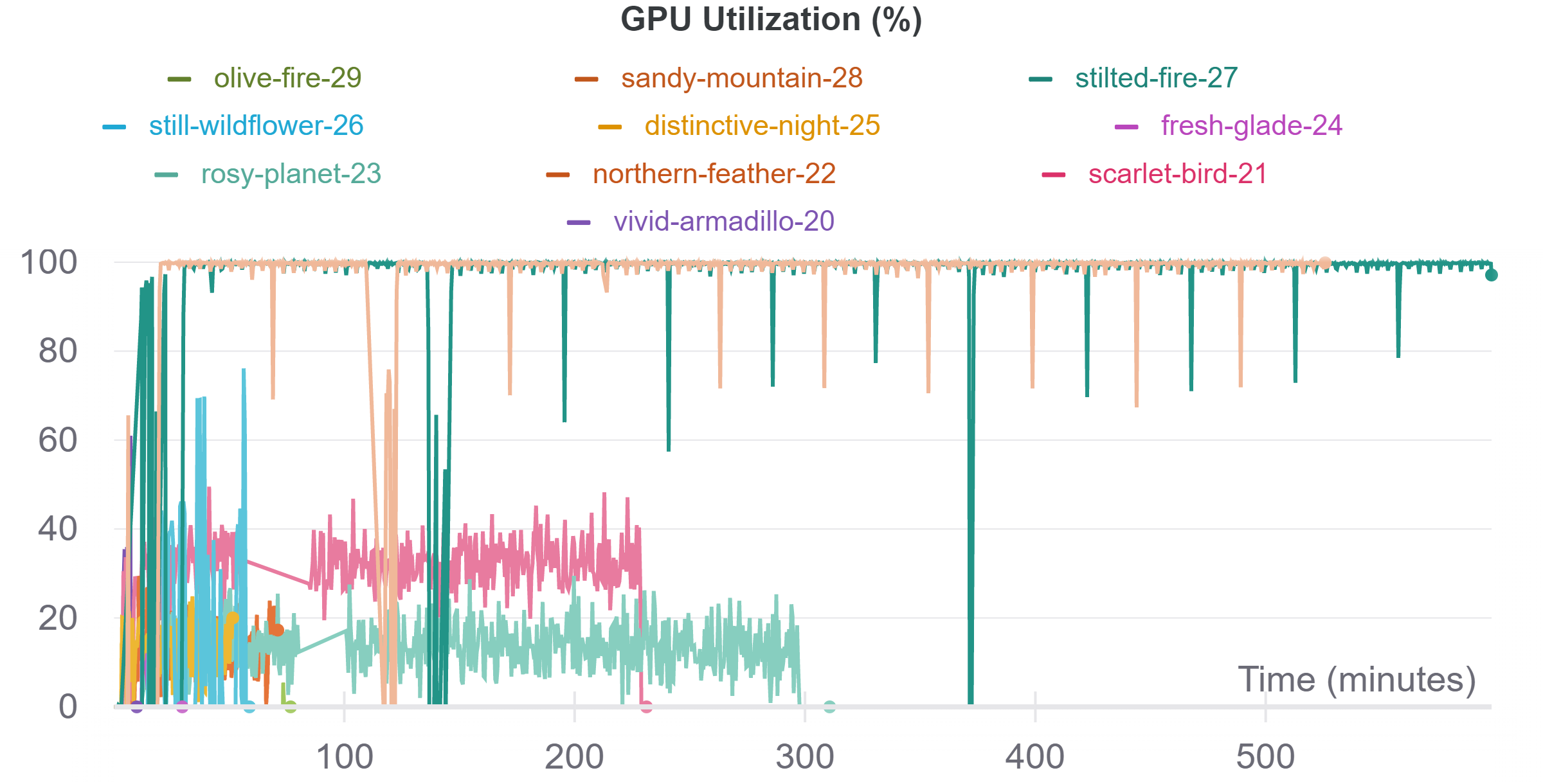
Due to the size of ResUnet (mainly the FC layer I added), this monster is really hard to train, here is the reuslt I got (And the Utilization graph of Colab's P100 GPU, just for fun :P):
Here are some image I picked from the test set as a demostration of the capbility of my NN:



Here are some images I ran from my own collection. As you can see, the model is quite well on pic 1 and 3, so I am a little bit shocked when I saw image 2 (it is a fail case I picked out of lots of successful result though)