CS194-26 Project 5: Facial Keypoint Detection with Neural Networks
Overview:
Don't we all love neural networks? The idea of removing all human knowledge and having an AI learn it for you has been a fascinating subject.
Now we'll make it a reality! Instead of manually clicking on facial keypoints, we'll train a neural network to find keypoints for us, removing the time and effort from us, and also having an agent that can perform the task better than most humans.
We'll use the same image dataset as in Project 3, the Danes dataset.

Part 1: Detecting the Nosetip
1.1
We'll start off small, training a network to detect only the nosetip.
Here's what the nosetip points from a few randomly selected images look like:










1.2
Lets make our neural network! Here's what our neural network architecture is:
Net(
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(24, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=768, out_features=20, bias=True)
(fc2): Linear(in_features=20, out_features=2, bias=True)
)
Also, we'll use batch size of 1
Training on the first 192 images and then using the remaining images as a validation set, here's what our loss curve looks like:
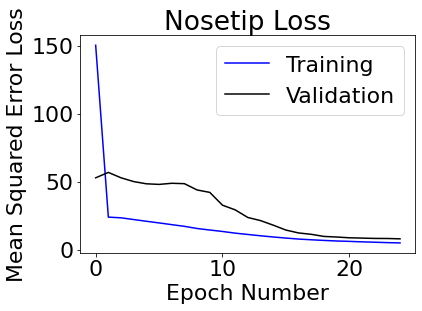 1.3
1.3
Here's what the neural network predicts for the nosepoints on these images (including training and validation):










The last images are from the validtion set. It seems to predict (blue points) fairly well, but fails on images where faces are turned those are smiling (image 5 and 6) seem to give my neural network trouble.
Part 2: Detecting All Facepoints
2.1
Next, we'll scale to detect all keypoints, the landmarks from the entire dataset.
Here's what the facepoint landmarks from a few of the selected images look like (same set as above):










2.2
Here's what our updated neural network architecture that I settled on.
I found that keeping the same starting, but making the later sizes have a smaller shift worked best
Net2(
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(12, 20, kernel_size=(6, 6), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(20, 24, kernel_size=(5, 5), stride=(1, 1), padding=(1, 1))
(conv4): Conv2d(24, 28, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
(conv5): Conv2d(28, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fc1): Linear(in_features=5632, out_features=400, bias=True)
(fc2): Linear(in_features=400, out_features=116, bias=True)
)
We'll still use a batch size of 1
Training on the first 192 images (after some shifting) and then using the remaining images as a validation set, here's what our loss curve looks like:
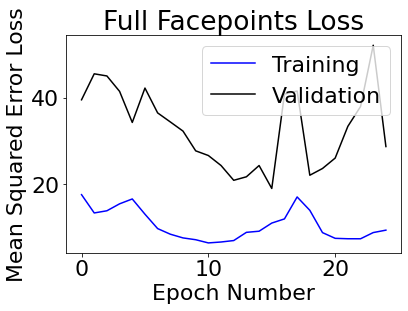 2.3
2.3
Here's what the neural network predicts for the facial keypoints on these images (including training and validation):










The last images are from the validtion set. It seems to predict (blue points) fairly well. Once again, while some turns and smiles are fine, certain ones like image 7 and 9 sometimes gives my model trouble.
The jawline also seems to have problems on a multitude of pictures, but I think some humans would also disagree with the labels.
Here is the visualization filter for the last layer on the network:

Part 3: Larger Dataset
3.1
Now we move to a larger dataset
A few samples of the scaled images turned to black and white:



3.2
I ended up using resnet18.
We'll still use a batch size of 1, and run it on 10 epochs. Here's the loss curve:
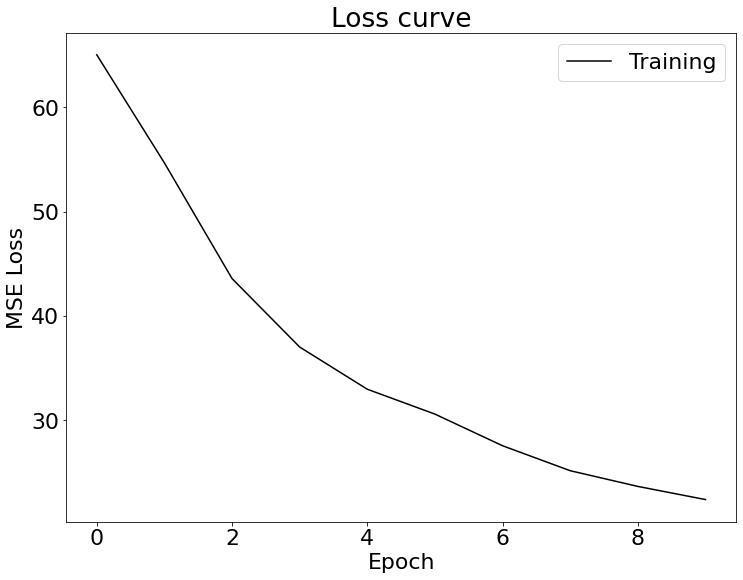
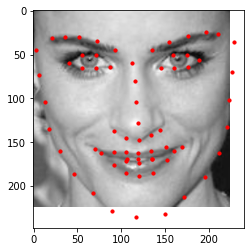
Here's what the neural network predicts for the facial keypoints on the validation images (in red):




Here is the visualization filter for the last layer on the network:

3.3
Training on the kaggle set, here's what some of the predictions are, visualized in their native format:







Seems good, enough, lets try to see the results on kaggle! Here are the results:
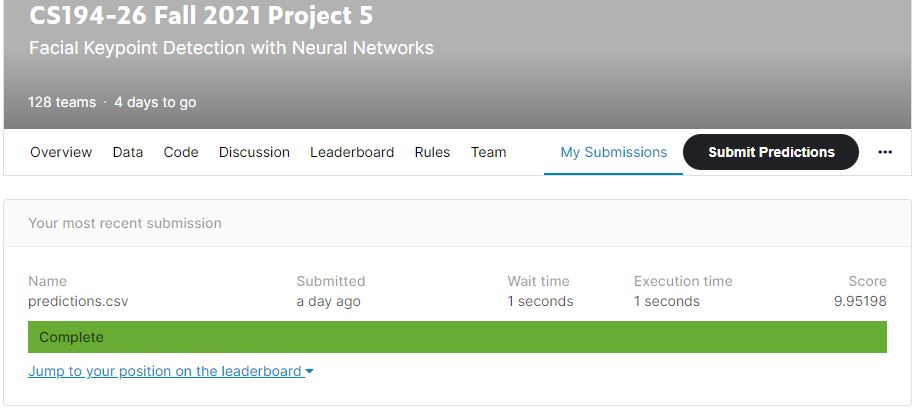
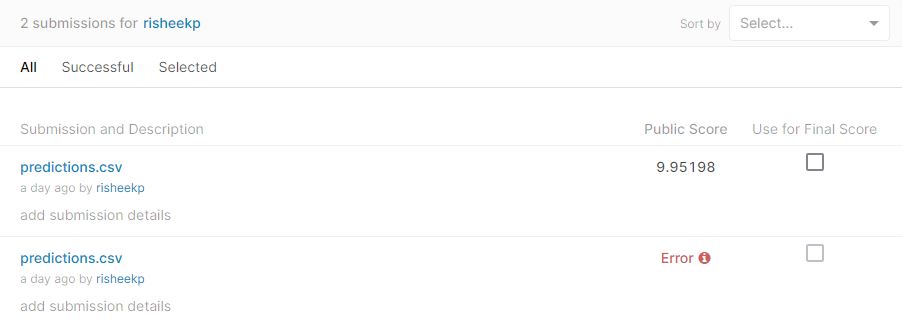
Not bad!
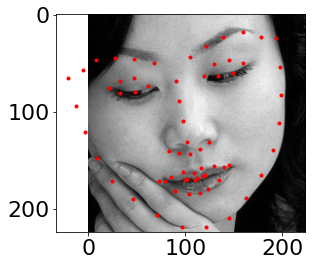
Finally, lets try it on my own face:



While it wroks on my second and third face, the first face is quite off, even after personally correcting the points; moreover, the zooming is quite off for the plotting on the points which makes it seem like it doesn't work at all.
What did we learn?
Neural Networks are harder to get right than I thought. Even though it takes all the evidence and learns independently, not knowing how right it is can be nerve-racking.
Still, it was really neat to run a generic program that has no immediate connection to the dataset and see visible results!