Part 1: Nose Point Detection
Ground Truth Nose Examples
In this part, I used 4 layers of CNN and 2 layers of FC with ReLU and max pool. First, here're some examples of the ground truth nose point labels presented from the data loader.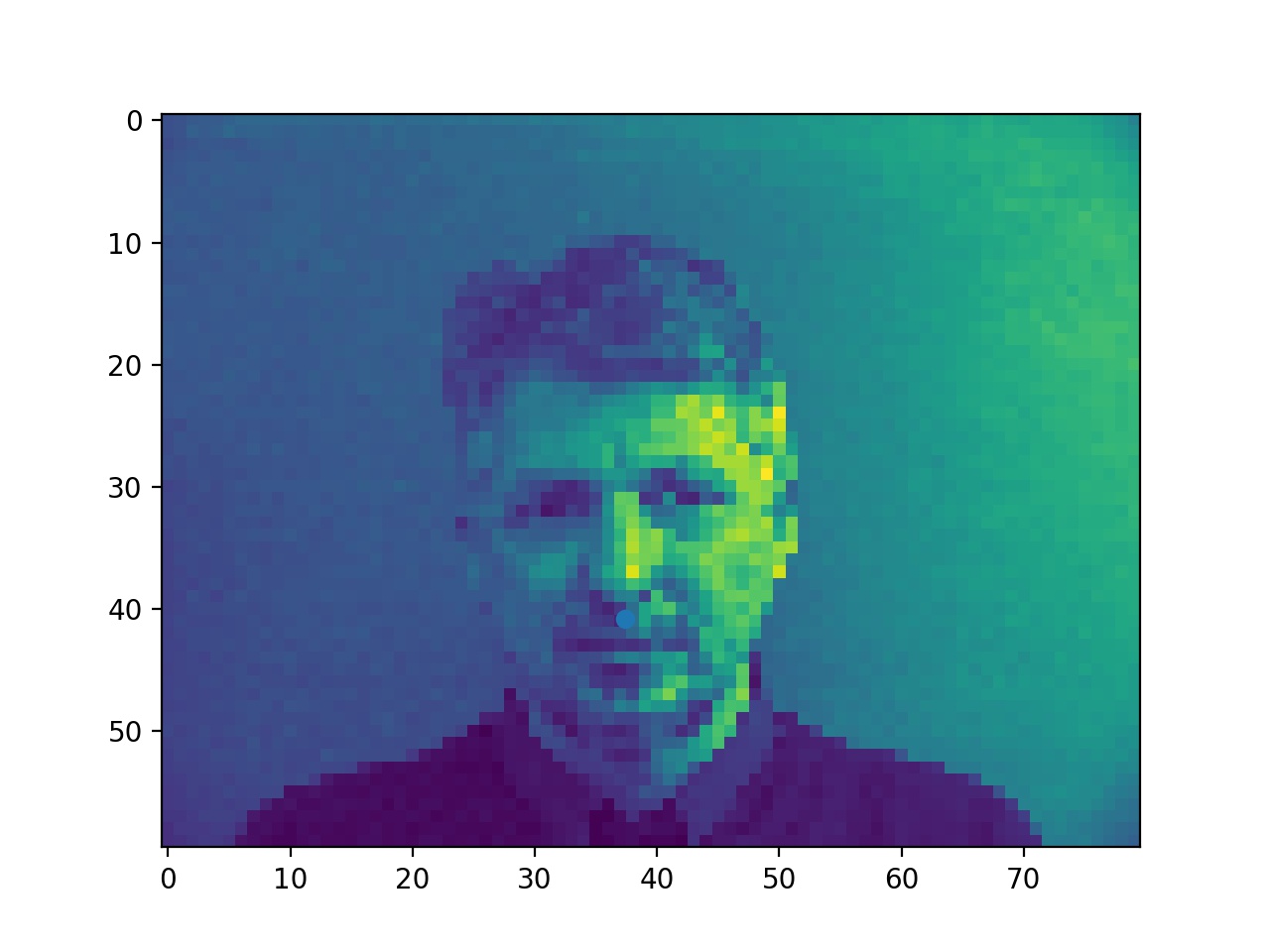
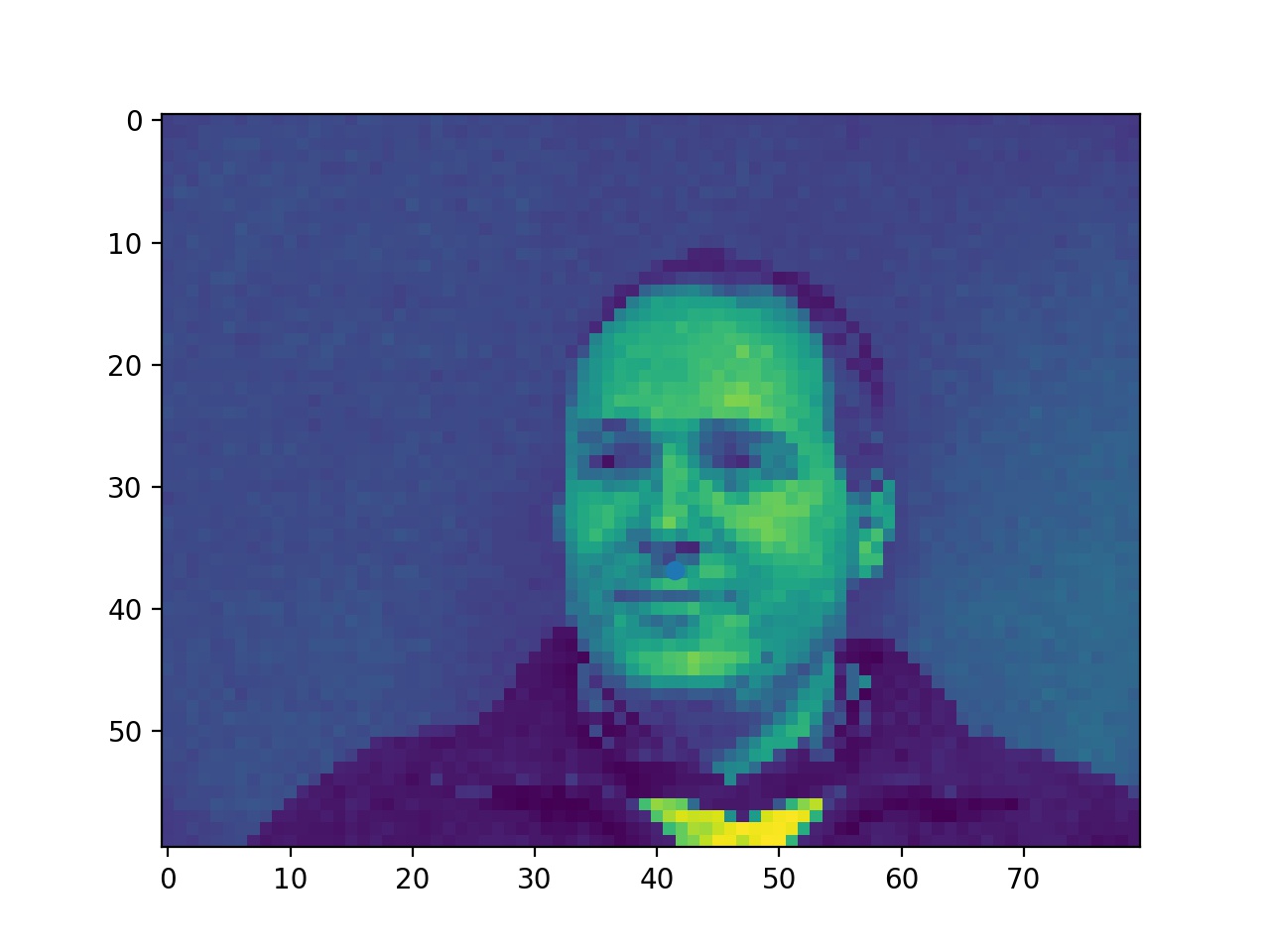
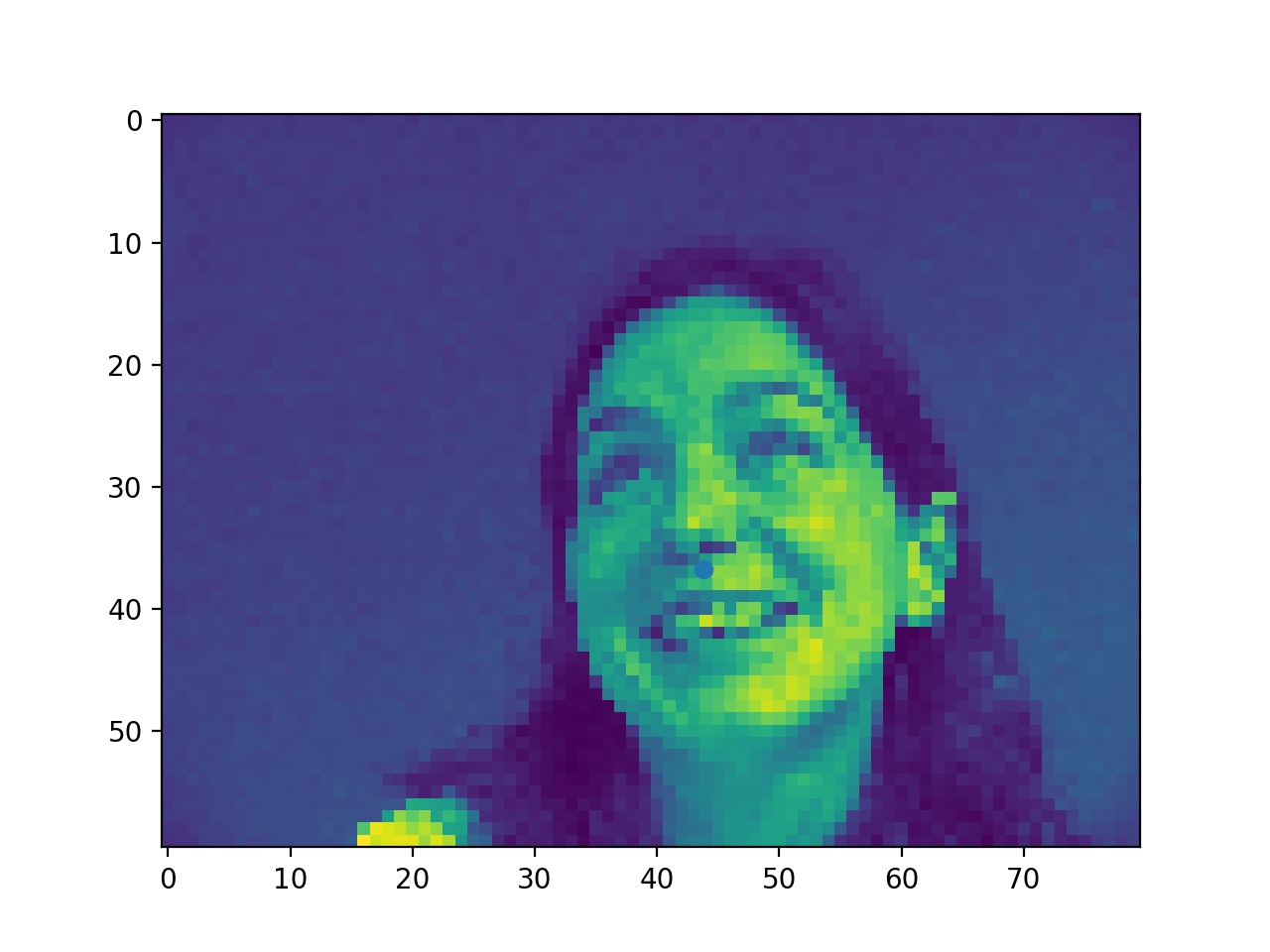
Ground Truth Noses (it's kind of hard to see because the points are blue but you will find it if you look closely)
Training and Validation Loss
Here's the graph of training loss vs validation loss. Hyperparameters: learning rate = 0.001, batch size = 32, epoch = 20.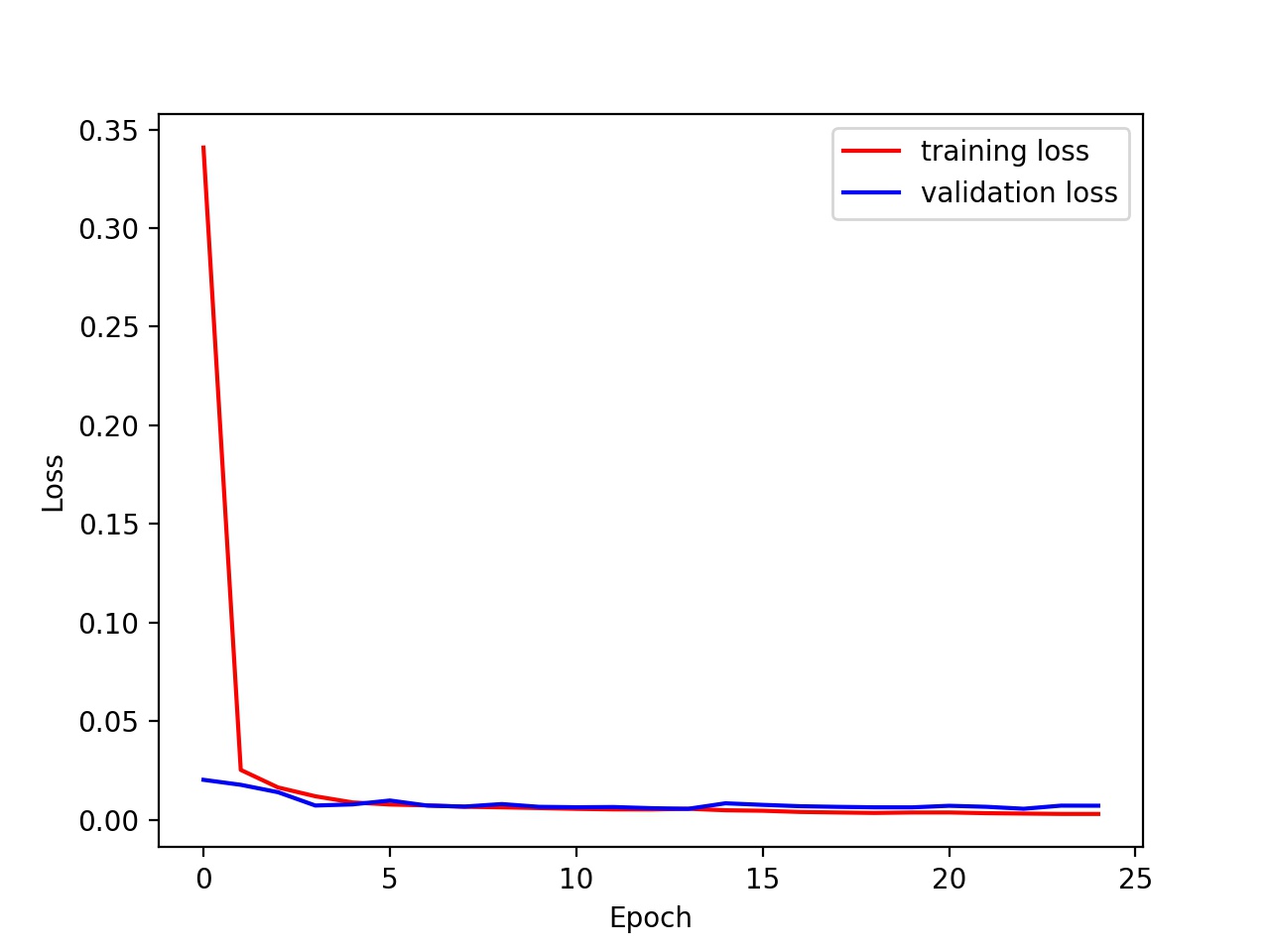
Training loss and validation loss
Hyperparameters Tuning
I then tried different hyperparamters: batch size and learning rate.Learning Rate
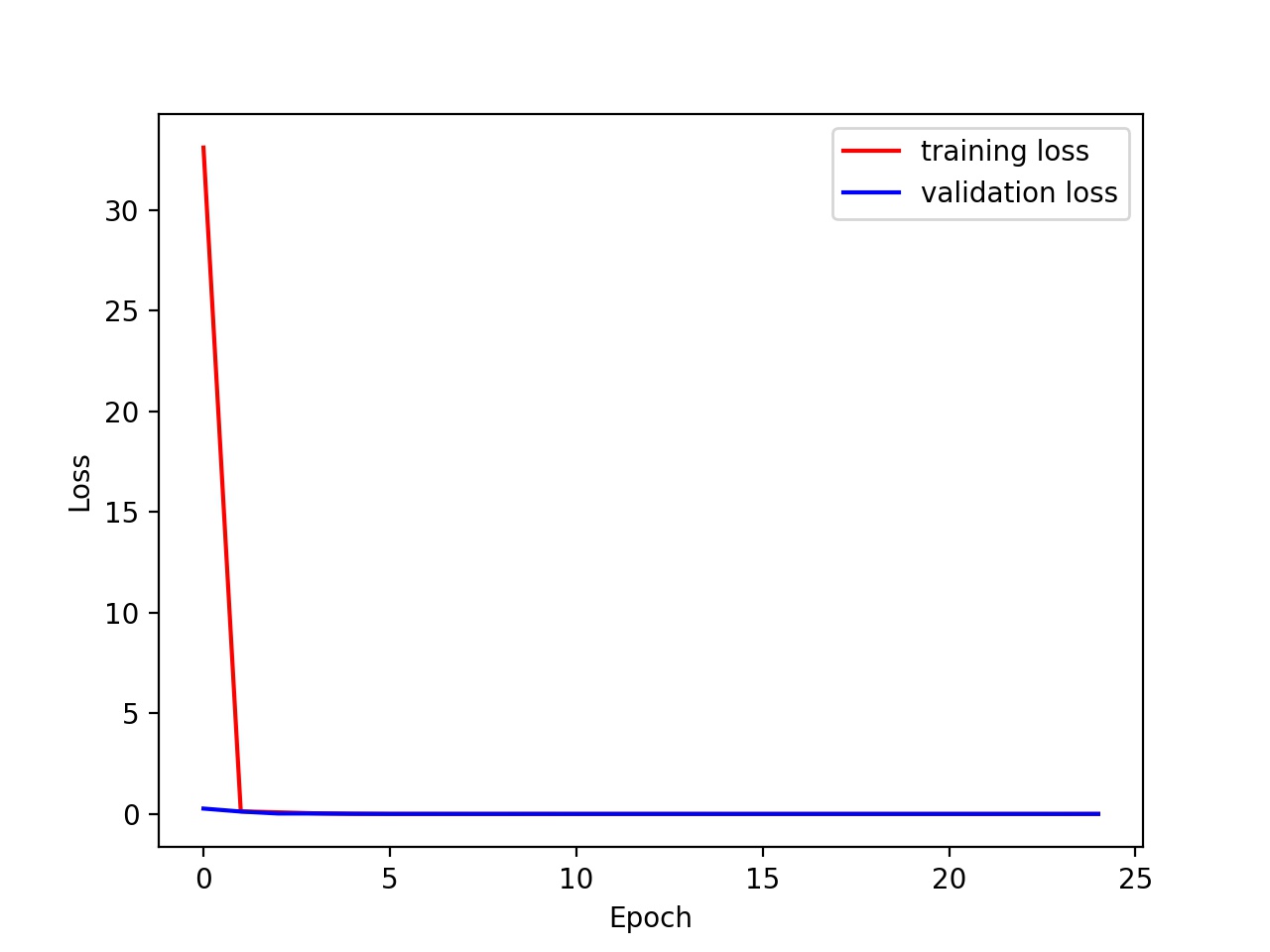
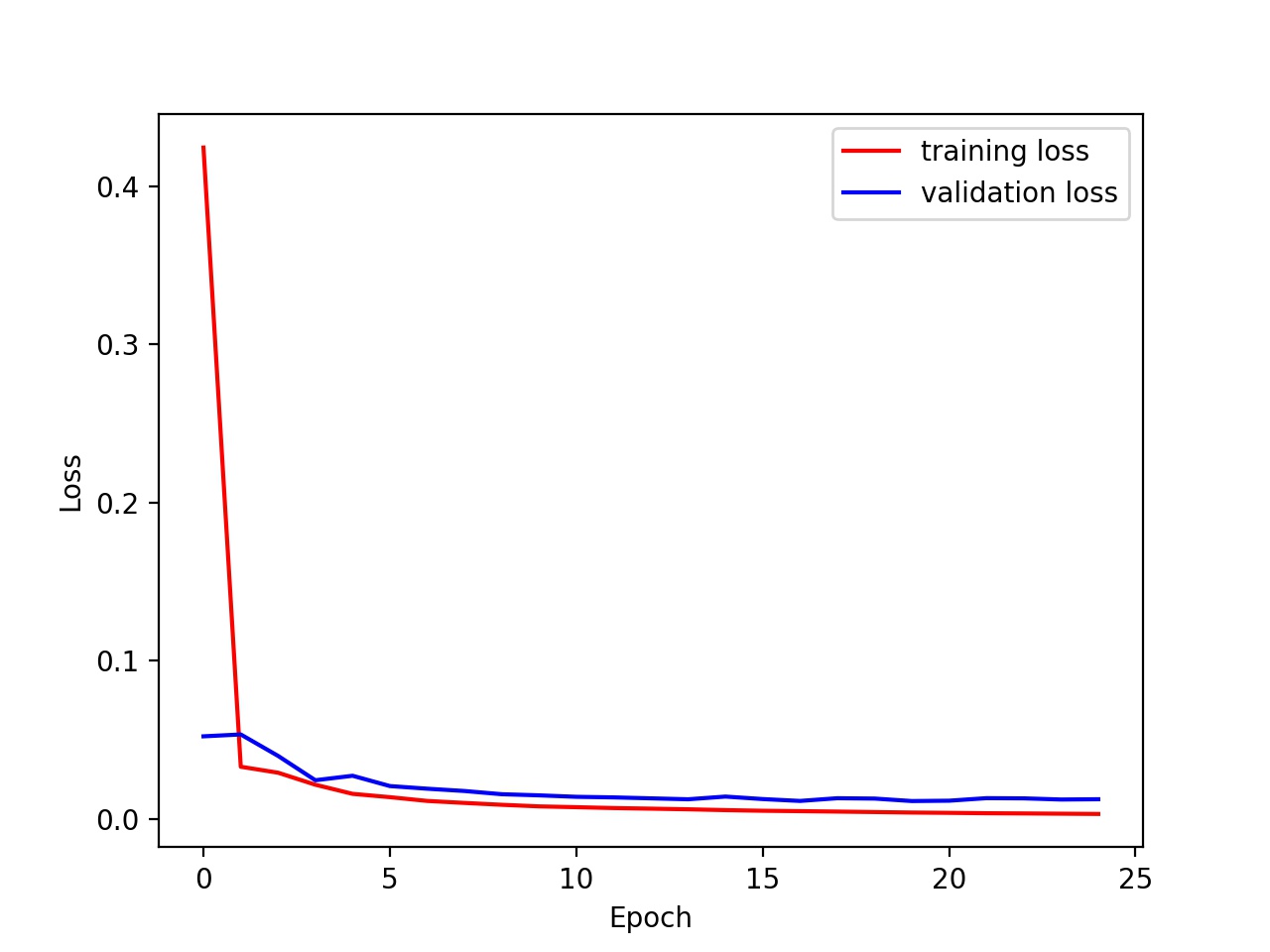
Learning rates of 0.01, 0.001, and 0.0001 and batch size is kept at 32
We can clearly see that a slower learning rate makes the model converge slightly slower.
Batch Size
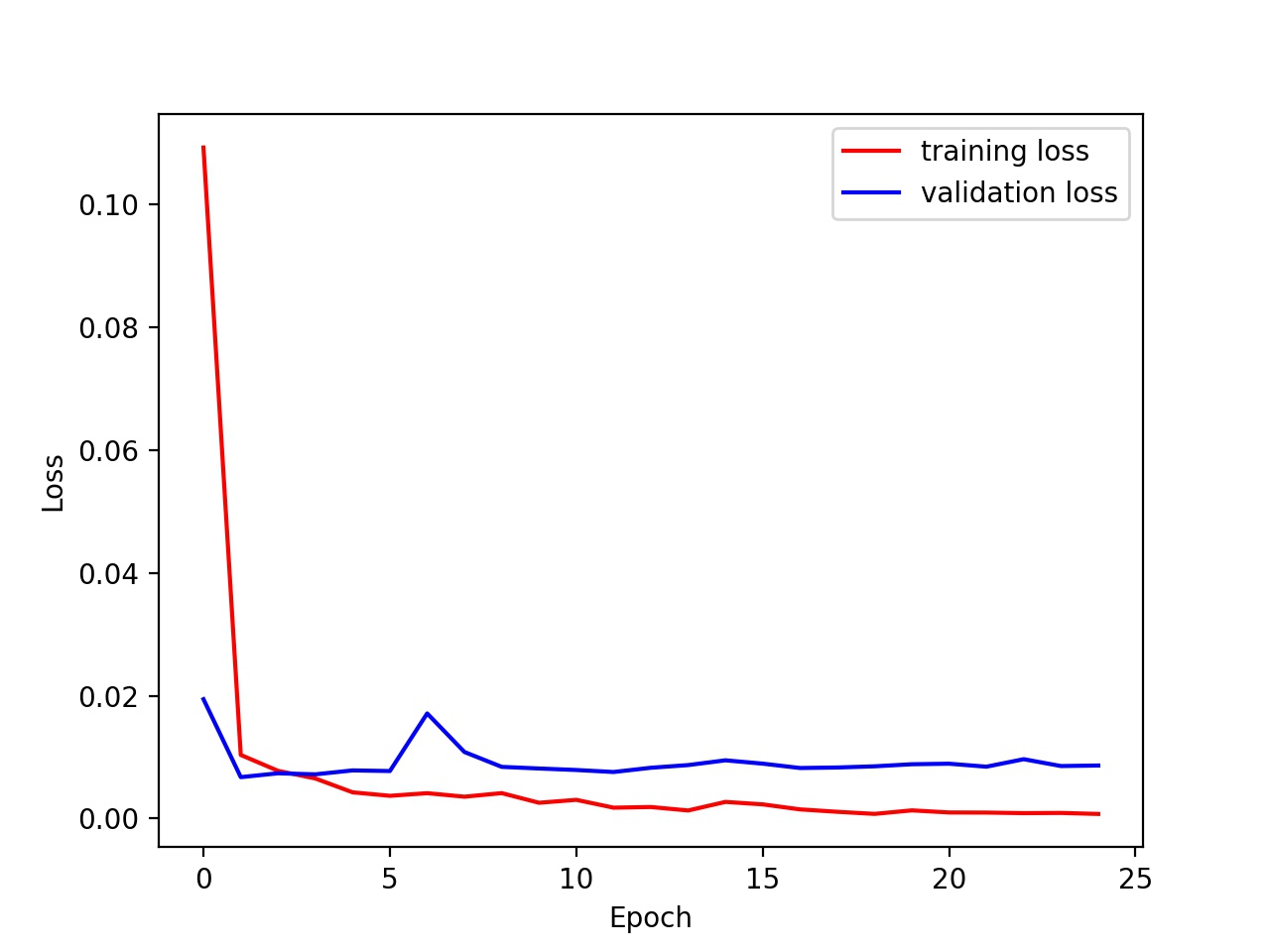
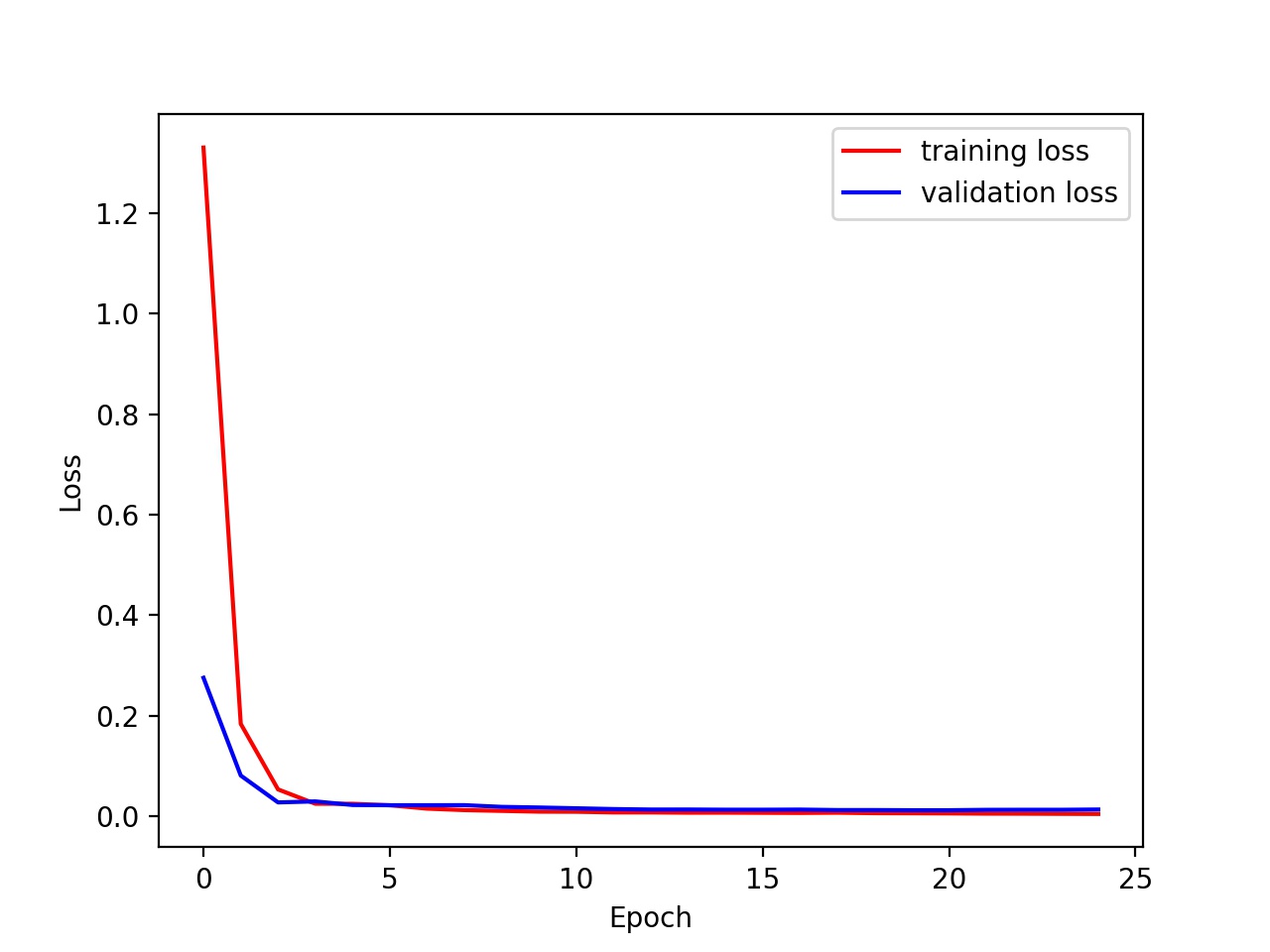
The batch sizes are 8, 32, and 64 and learning rate is kept at 0.001
We cannot see that much of a different from the graph, but higher batch size trains faster as it uses more parallelism of numpy.
Some Example Cases
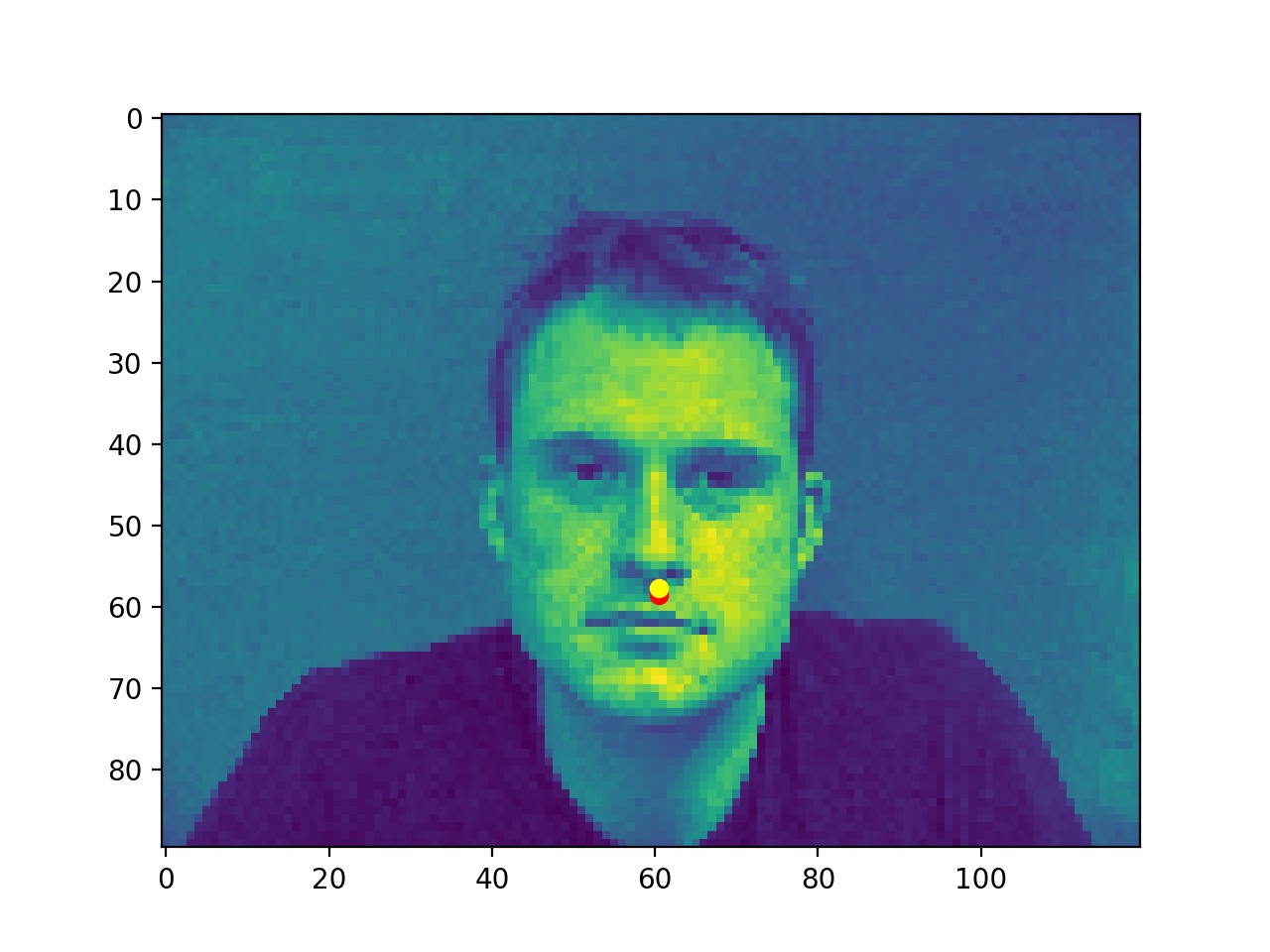
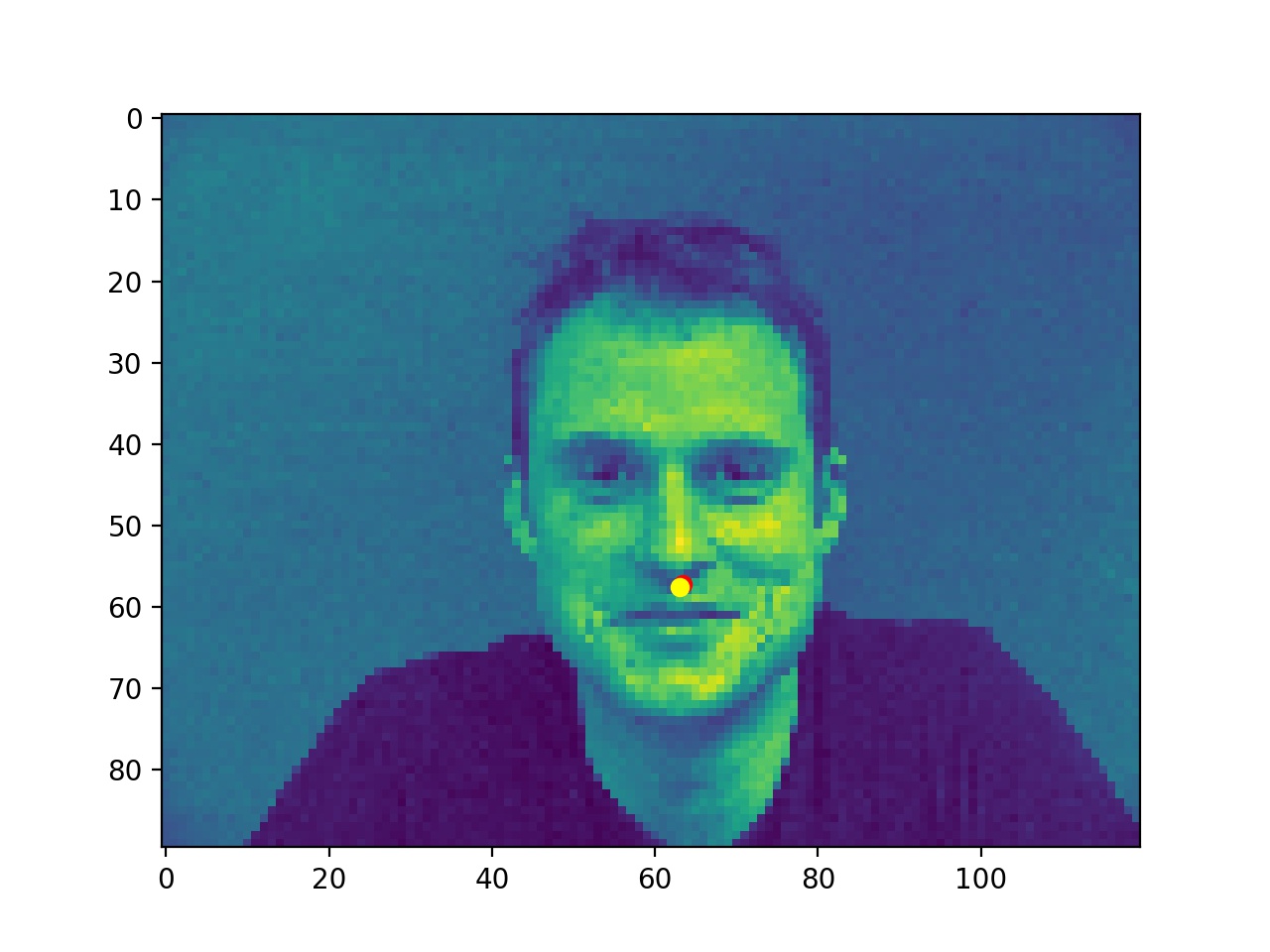
Good ones probably because the faces are facing front
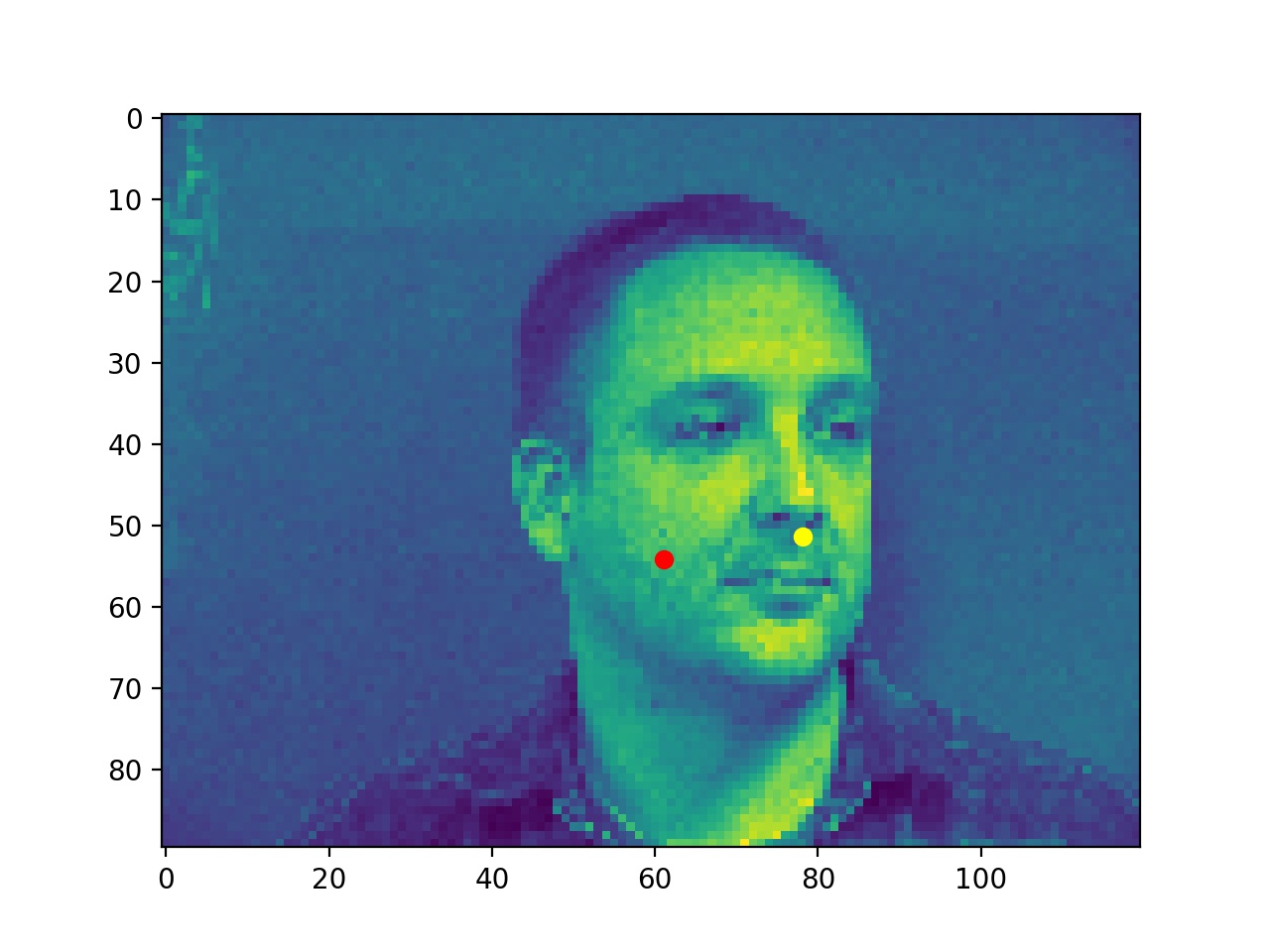
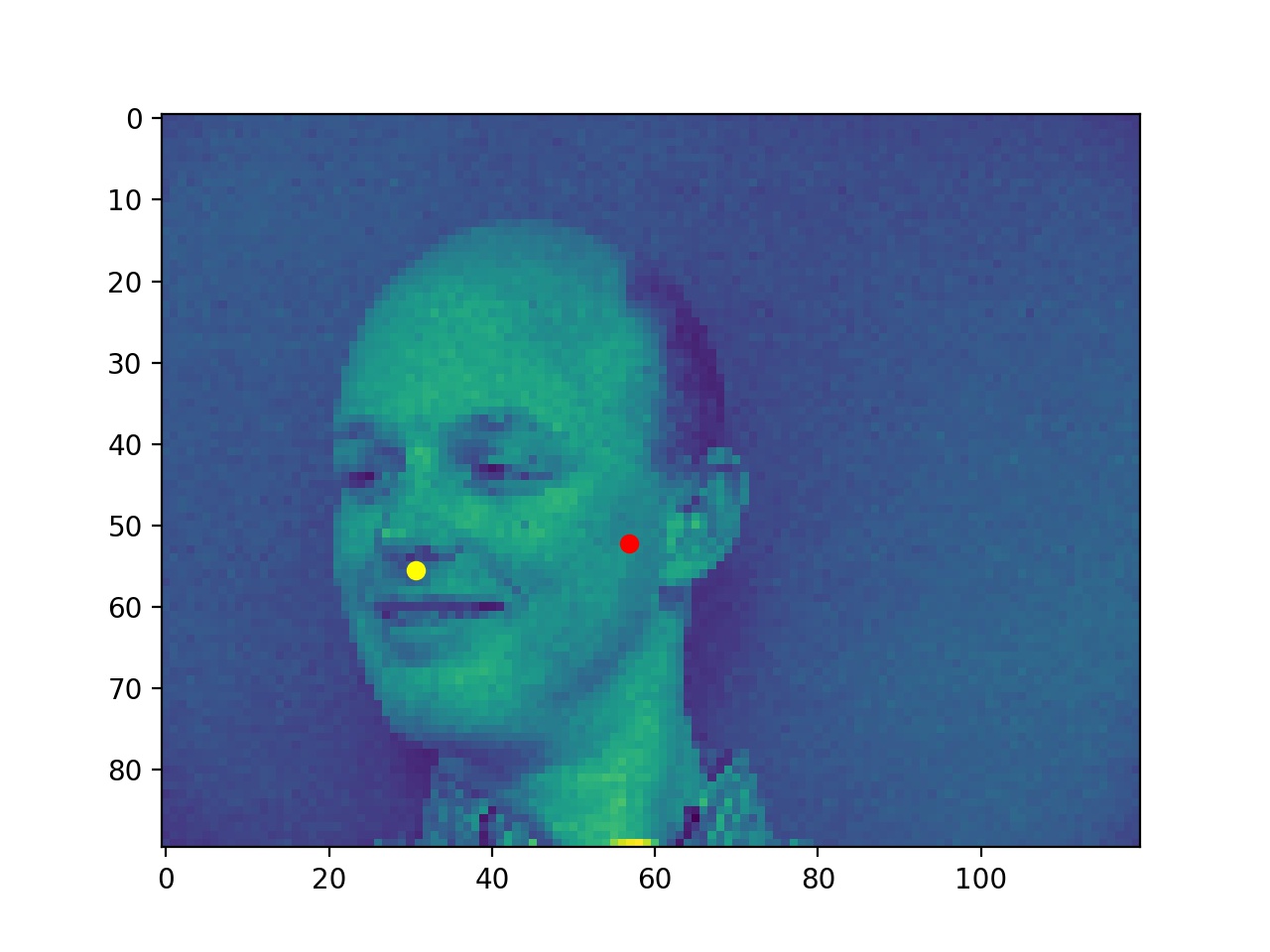
Bad ones probably because the faces are side ways
Part 2: full face detection
Example Labels
I used a slightly more complex model and here're some examples of the grund truth labels for the full facial features.

Ground truth examples with data augmentation
Detailed Architecture
The neural networks architectures I used here is 6 layers of CNN with kernel 5 where 4 of them are followed by a max pool of kernel 2, and all of them are followed by a ReLU activation. Then, I have 3 layers of FC where only the last layer does not have ReLU activation (output layer).
I also used data augmentation such as random crop to give the images more variety.
Training and Validation Loss
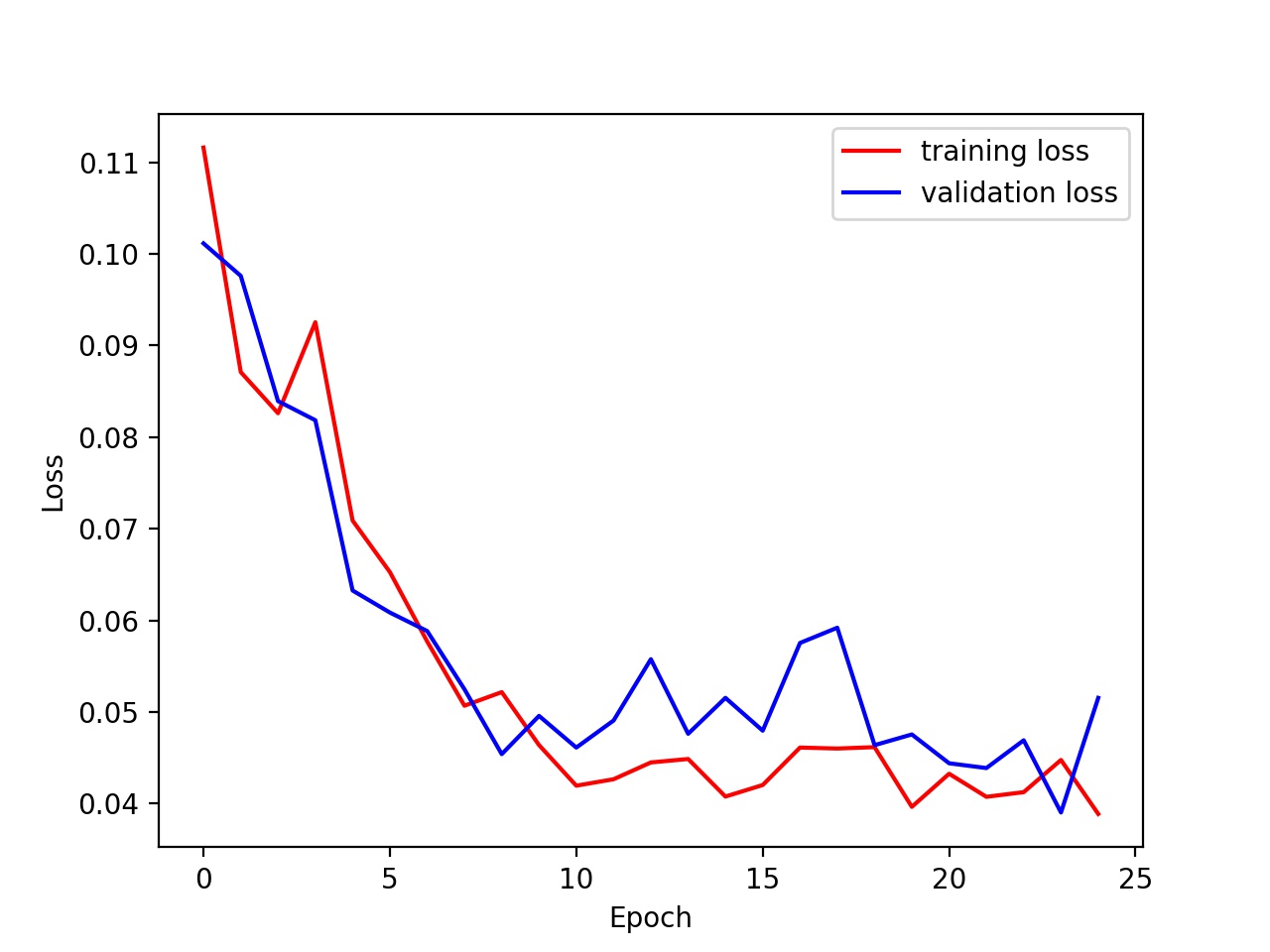
Training and Validation loss where lr = 0.001 and batch size = 32
Some Example Cases


Some good predictions
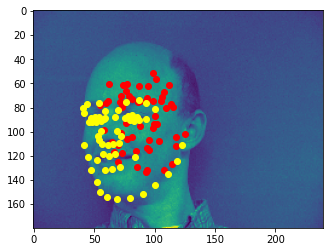

Bad predictions, I think probably because they're sideways and their facial features are not as prominent
Visualize the Training Filters
We can graph the training filters to visualize them.
Training Filters Visualized
Part 3: Larger Dataset
In this part I trained my neural network on a larger dataset, namely, a dataset of 6666 images along with 68 keypoints per image. I submitted my test predictions on kaggle and my user name is Mitchell Ding. I divided the dataset into 80/20 as training and validation set. Specifically, 5300 images for training and 1366 images for validation.Detailed Architecture
I used the pretained network ResNet18 and modified its input and output layer to match our image dimensions. I started with its pretained weights, and then trained for 10 epoch on the dataset.Training and Validation Loss
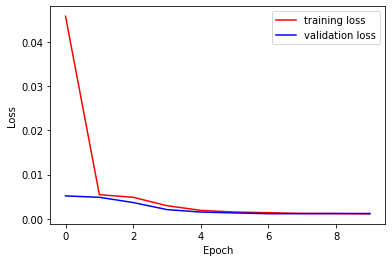
Training and Validation Loss with lr = 0.001 and batch_size = 128
Results on validation set
Here're some predictions that I made on the validation set.


These are pretty good predictions.
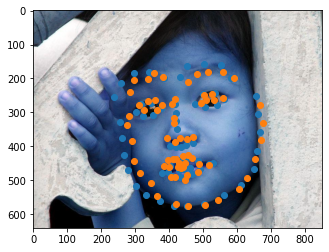
This one is relatively worse, but still better than what we did in part2, because we have more data now.
Results on test set



Some predictions made on the test set
My own photos



My own photos



Keypoints my model detected on my own photos. We can see that the middle picture was much better than the other two. I suspect it's because the dataset that I trained the model has predominatly white face and thus it doesn't do a good job detecting east asian faces.