Pixel values have been normalized to be in [-0.5, 0.5] and image has been resized to be 60 x 80. The nose keypoint coordinates have also been normalized to be in [0, 1]
We train for 15 epochs with lr 1e-3 and batch size 4. Our network consists of 3 convolutional layers (each followed by a relu and maxpool) as well as 2 fully connected layers.

Generally it works well for images that are centered with the faces facing forward. It tends to fail on off centered images as well as faces at different angles most likely due to the limited amount of data we have with off centered and rotated faces. It also seems to fail on some images that are brighter than others (more contrast).




Pixel values have been normalized to be in [-0.5, 0.5] and image has been resized to be 240 x 180. The facial keypoint coordinates have also been normalized to be in [0, 1]. Below are some ground truth labels for a couple images.



We have larger network consisting of 5 convolutional layers and 3 fully connected layers. The detailed breakdown is shown below.
FacialPointsConvNet(
(conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1))
(conv2): Conv2d(12, 15, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(15, 24, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(24, 20, kernel_size=(3, 3), stride=(1, 1))
(conv5): Conv2d(20, 15, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=225, out_features=200, bias=True)
(fc2): Linear(in_features=200, out_features=200, bias=True)
(fc3): Linear(in_features=200, out_features=116, bias=True)
)
Hyperparameters:
lr: 1e-3
batch_size: 32
epochs:20
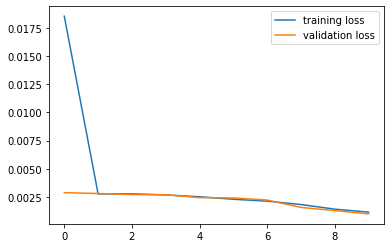
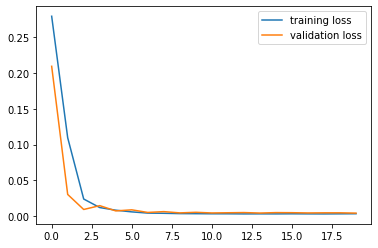
Plot of training and validation loss shown below.
Generally it works well for images that are centered with the faces facing forward. It tends to fail on off centered images as well as faces at different angles most likely due to the limited amount of data we have with off centered and rotated faces. Although we do perform data augmentation, we still only have a very limited amount of faces. We also use the entire image which consists of a lot of background pixels which are used as features and may contribute to noise. Our kernels are also fairly small and may not capture larger features. Additionally, there are many points that are normalized so small shifts in points may not increase the loss by that much.




Visualizing filters for each layer below
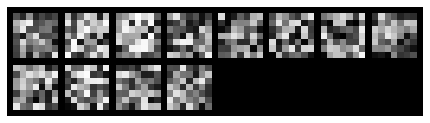

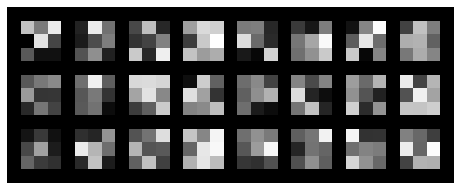
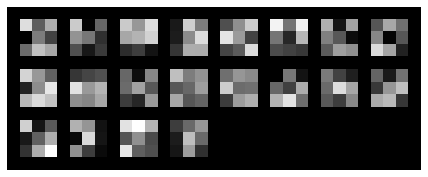
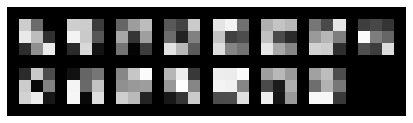
Below is an example of an image with ground truth keypoints, cropped using the bounding boxed, resized, and augmented

For this larger dataset, we used the ResNet18 Architecture which is described below.
test
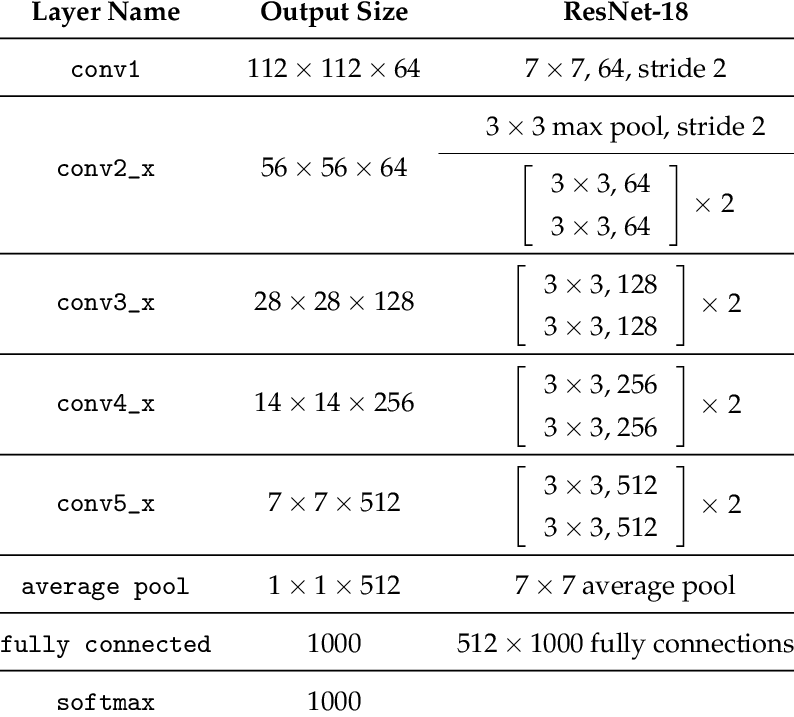
It consists of 5 convolutional layers and a full connected layer. It was
pretrained on color images but this wasn't applicable since we train on grayscale images.
We modify the first layer to take 1 input channel and the final full connected layer to output
68 * 2 points.
Hyperparameters:
lr: 1e-3
batch_size: 64
epochs:10
Plot of training and validation loss shown below.