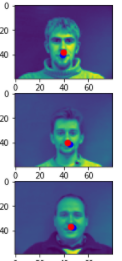
Here are three pictures I selected from the training set, where the red dots in the pictures are the ground truth value, and the blue dots is the nose tip position that my network predicts.
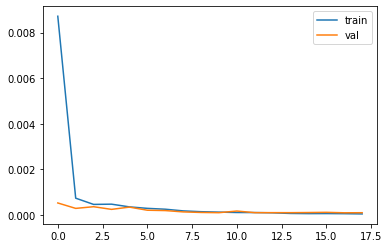
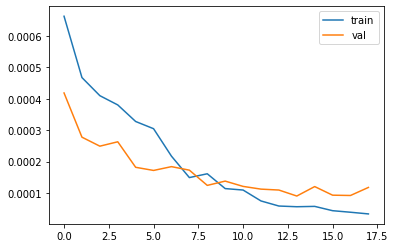
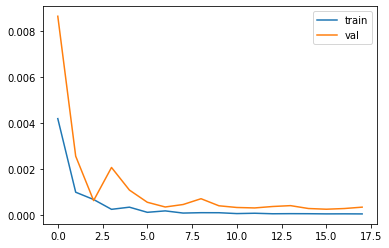
Here is the MSE loss for the training set and validation set, the learning rate I used is the 2e-3 and batch size 8.
The hyperparameters I tuned are the batch size, and the learning rate.
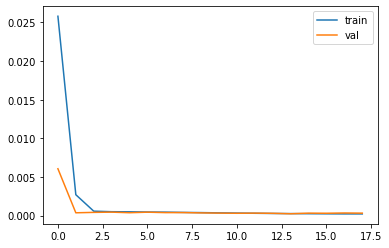
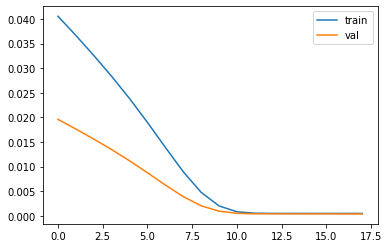
The learning rate I tested are 2e-3, 1e-3, 1e-4, 1e-5, and here are the MSE loss comparisons. From the those graph, all the training error and validation error reaches to the 1e-5 level with different speed, so the learning rate doesn't really affect the accuracy of the final output of the model
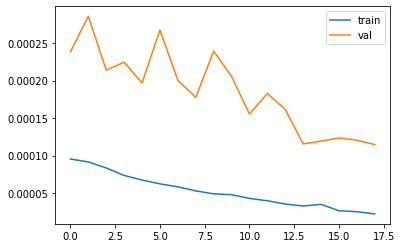
Here are the the batch size I tuned, the final batch size I used are 16. Here are the performance of the batch size 32 and 64, which both were worse than size 8 which the top one I showed before. Batch size affects the performance
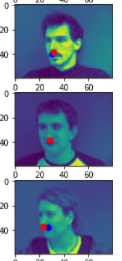
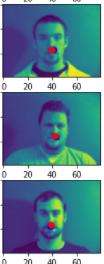
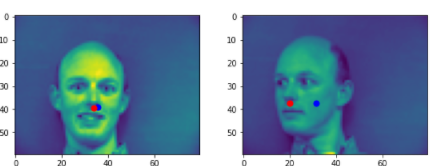
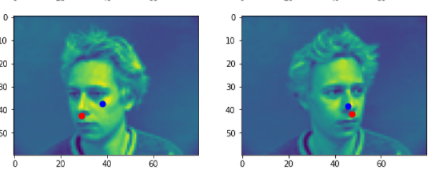
Here are two comparisons of good prediction and bad prediction.
From these two pictures from the validation, the blue points are the nosetips predictions from the model.
My models predicts well when the face is in the middle or slightly turned left or right. It performs bad when the face is far away from the midpoint. Since these examples are not common in the training set, thus the model didn't learn enough from the training set.
Here are some groundtruth points with their images. For the data agumentation, I rotated from -15 to 15 degrees and change the brightness then turned them into a resized grayscale pictures



Here are the architecture of the Neural network for this part
Part2Net(
(features): Sequential(
(0): Conv2d(1, 10, kernel_size=(7, 7), stride=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(20, 40, kernel_size=(3, 3), stride=(1, 1))
(7): ReLU(inplace=True)
(8): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(9): Conv2d(40, 80, kernel_size=(3, 3), stride=(1, 1))
(10): ReLU(inplace=True)
(11): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc1): Linear(in_features=2800, out_features=1500, bias=True)
(fc2): Linear(in_features=1500, out_features=800, bias=True)
(fc3): Linear(in_features=800, out_features=116, bias=True)
)
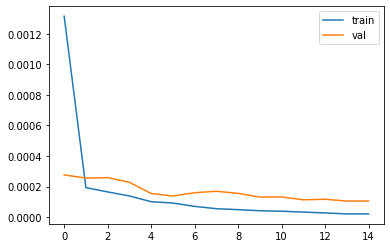
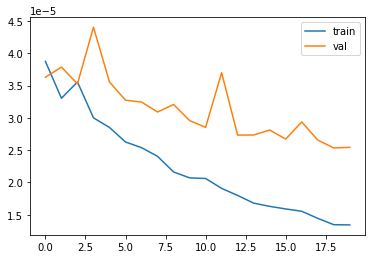
Here is the MSE loss for the training set and validation set, the learning rate I used is the 1e-3 and batch size 16.
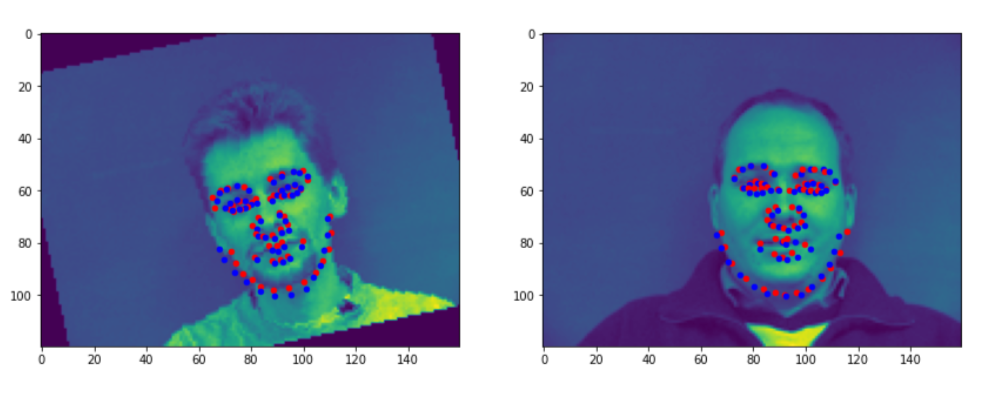
Here are a few good predictions. The red dots are the groundTruth, while the blue ones are the predictions
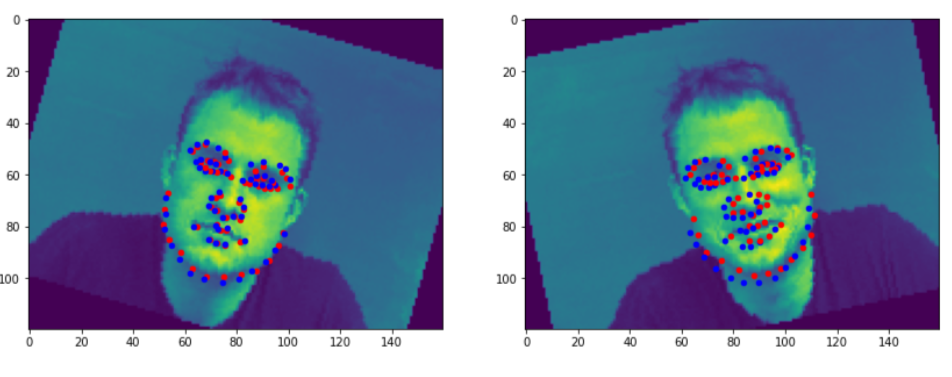
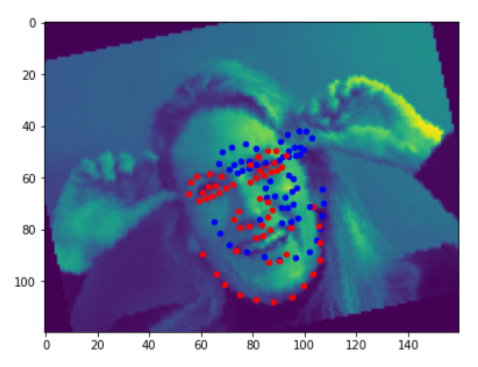
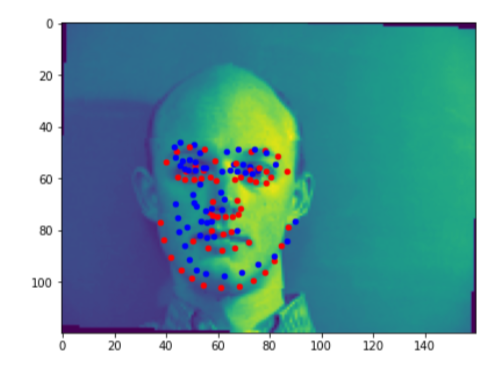
Here are a few bad predictions. The red dots are the groundTruth, while the blue ones are the predictions. The reason they fails I think is that they were far away from the center, thus the models may assume their heads are turned left or right. or they are from a very extreme rotation degree which are few in the training set
Here are the images of the filters of the first conv2 layer, since there are ten channels
I used the ResNet18 as the model, but changed the first conv2 layer to 1 input channel in order to fit the grayscale pictures.
I changed the last fc layer to 2 * 68 outputs since we needs the x,y coordinates for the 68 points
Here are a few good predictions for the points in the test sets. The blue ones are the predictions




Here are a few good predictions for the points of my own collections. The blue ones are the predictions





