Neural Algorithm of Artistic Style
Introduction
In this project, we will investigate a neural algoirthm for image style transfer. Different from popular models like GAN, which involves large scale parameters, this algorithm applies gradient descent directly to the input image. The only deep neural network involved here is VGG19, but the model achieves comparable result as large-scale GAN. In later sections, we will deeply discuss the flow of this algorithm, and visualize the final outcome.
VGG-19 Deep Neural Network
Throughout the style transfer process, we are using the VGG-19 network pretrained on ImageNet. We will extract from some intermediate layers for content features and style features, and use them for alignment. The rightmost column in the picture below describes the architecture of a VGG-19 network. Note that all hidden layers are followed by a ReLU unit. We will not use any of the fully connected layers since they are for classification tasks. We also replaced "maxpool" layers with "avgpool" layers as they improve gradient flow and can generate slightly more appealing results.
VGG-19 Architecture:
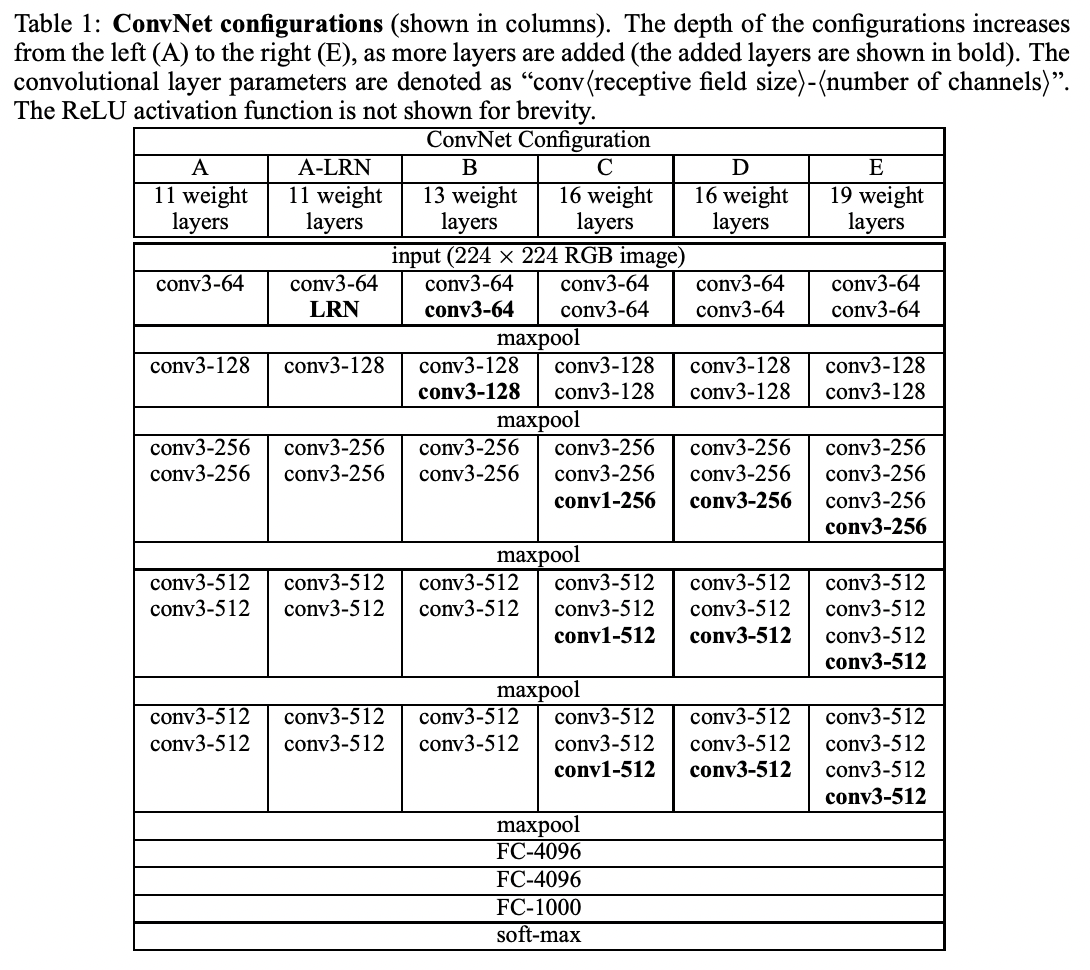
Model Setup
For image style transfer, we have two source images: the content image and the style image. Additionally, we will initialize an output image with random noise. The basic idea of this algorithm is to pass each of these three images down the VGG19 neural network, and extract content features and style features from intermediate layers. We will then calculate content loss between content features from the content image and those from the output image, as well as style loss between style features from the style image and those from the output image.
Content Loss
We will use intermediate output from 'conv4_2' as the content features. Since in the current period we focus more on the texture (pixel values), content loss is calculated using the squared difference between each feature value in the latent vector.
Style Loss
Style features are extracted from 5 intermediate layers: 'conv1_1', 'conv2_1', 'conv3_1', 'conv4_1', 'conv5_1'. For style alignment, we focus more on the relationship between pixels. Therefore, for each intermediate latent vector, we flatten the height and width dimension to turn a 3D feature into 2D (i.e, for a
Total style loss is computed as a weighted sum of each intermediate layer.
Finally, we combine content loss and style loss together by:
Implementation Details and Visualization
In our model,
Below is a content image and a group of style images along with their corresponding outputs:
Content image:

Style image 1:

Style transfer 1:

Style image 2:

Style transfer 2:

Style image 3:

Style transfer 3:

Style image 4:

Style transfer 4:

Style image 5:

Style transfer 5:
