This project creates AR population in real space by utilizing a grid box in the real world to track points in space. The overall idea for the project is meant to utilize the homography matrix we learned in Project 4 to transform a drawing made on our image to match world space to camera space to screen space.
The video I used to create my AR video is here.
I first selected 20 points on the grid that I would use to track my video. Then, I used the Median Tracker to track the selected points across the image frames.


In order to make sure my points were moving along with the trackers through the video, I created a Homography matrix that mapped coordinates in box space (based on the axis picture above) to camera space (the pixels selected by my points). The homography matrix was closely related to what I made for Project 4, except I solved for a system of 10 equations (having selected 20 points). Then, I applied the homography matrix to each cube corner pixel that I was drawing so that I could draw a cube using the converted pixel coordinates. This process was repeated for each frame in the video.
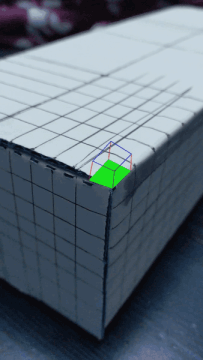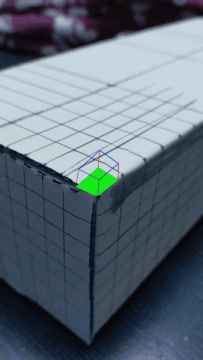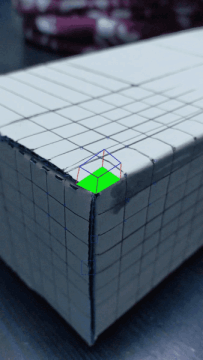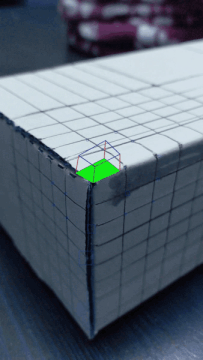
Inaccuracies in the way the box wasn't completely matching the points may be attributed to the lines that I drew on the box itself, which weren't completely clean, or maybe due to there being lines rather than clean points. That may have caused inconsistencies with how the points followed the corners of the grids. Another way to improve the output of my video would have been to use more points, and not have used the points in the areas where there were large dark spots, as I think that confused the tracker.
This project utilizes deep neural networks to apply artistic styles from input images onto output images, such that the outputs will be "drawn" in the input image's style.
I wanted to use a variety of famous paintings with different styles. Here are the style images I used:





I just used Starry Night because I wanted to check to make sure my images looked similar to the examples.
For my content images, I wanted to compare whether highly detailed city buildings or large spanning nature scenes would affect the stylization of the images.


Referring back to the paper, I created a convolutional neural network to extract the textures in the input style images, which divided the image into convolutional layers extracted via a VGG-19 network. Then, I applied these textures to the content image so that they maintained similar colors and textures to the style input. By applying these layers to the content image separately before combining them all into one image, I was able to apply the style from a general to specific level of detail. The weighted sum also ensured that neither style nor content image overpowered the image, and applied an equal amount of style and content in the resulting image.
I attempted to apply each of my style images to both of my content images:












Some of the results that I found had astronomically large losses during later runs and had really strange resulting images, which changed every time (see guernica + 2nd content image). I believe this might have been because the compositions of both images weren't similar enough to apply the style to, which the paper said that the two images had to be similar enough for the styles to apply correctly. This issue reappeared for some of my other images, but restarting the kernel tended to help in all cases except this one specifically. In other cases, like in the Still Life application to my first content image, there were small areas where the colors were off. I think this might be because the details were too small in comparison to the textures on the style image, so the neural network was unable to apply any stylization to those small detail areas.