1: Augmented Reality
Source video
This is the video I took of a marked box, with known 3D coordinates for each intersectio of lines (every line is spaced by 1cm).

Tracking corners
I used a hacky harris corner detector. Starting with the first frame, which has known image coordinates for each 3d coordinate, I looked the next frame. In the next frame, the corner is the closest corner found to the previous frame's known corner, given it is within 15 pixels in euclidean distance. This is because there is little movement between frames, so the same corner should appear in a very similar position in the next frame. Now we see a video of tracking these points over the course of the entire video. (I didnt use all intersections on the box because I didn't need so many. Since the next frame relies on the previous frame's known coordinats, if we lose sight of an intersection in one frame, then it can never come back in the future. However, since we have so many keypoints, we have enough to do least squares and find the camera projection matrix to convert from real coords to image coords.)
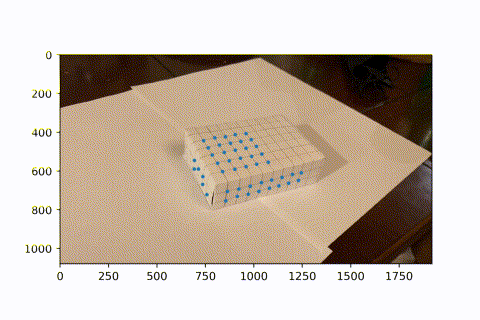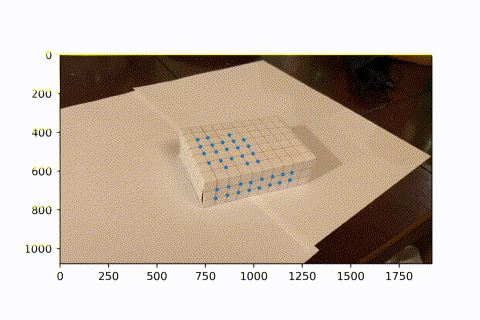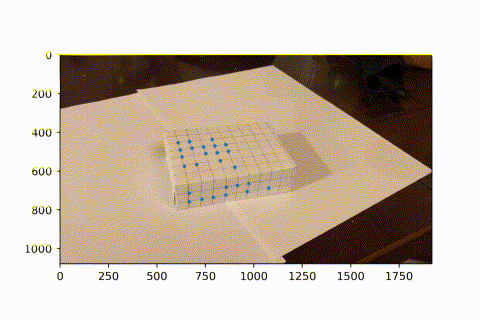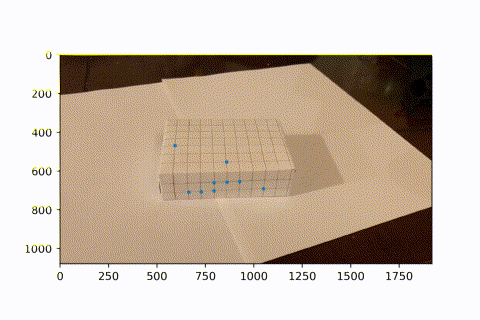
Image Projection
Now that we have many keypoints with known real_world --> image coordinates, we can use least squares to solve for the projection matrix of each frame. We can then use this matrix to project new real_world coords into our image frame. Here, we project a cube onto our image. As the video progresses and the camera moves around, the AR box correctly follows the image world coordinates.

2: Gradient Domain Fusion
With gradient domain fusion, we can blend 2 images without any strange, high frequency seams between the two. This is done by matching the derivative inside a source image (one that is pasted into a destination image).Instead of matching the pixel colors of the source image, it matches the derivative. This means the color may change from green to red, but the overall appearance of the image will be the same. The destination image is kept as-is (except for the part that is pasted on top of.)
Part 1: Toy Problem
As a simple example of least squares, we start by taking an image from Toy Story, and creating a new image that has as similar a gradient (in both x and y) as possible. We set up the Ax=b least squares problem, where x is our recovered image. A is of size (2*width*height + 1, height*width). Each row represents a constraint. The first width*height rows represent the x-gradient constraint for every pixel. The next width*height rows represent the y-gradient constraint for every pixel. Finally, to ensure the image looks similar, the last row sets the top left corner of the image to be the same value as the original image. Similarly, b is of size (2*width*height + 1, 1). It is created by taking the dot product of A and the toy image. Like in A, the first width*height entries represent the x-gradient, the next width*height entries are the y-gradient, and the last entry is the top left pixel value, all from the image of the toy. Now, when we solve for b, we ensure all gradients are the same, and the top left pixel is the same. The result is extremeley similar to the original image.


Part 2: Poisson Blending
We now use a very similar technique to solve the following problem, where v is the result image, and s is the source image. We solve this separately for each channel, and then stack them together to create a final image.
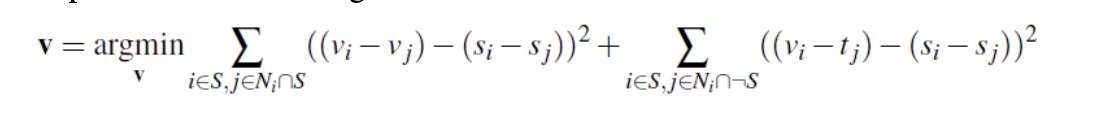
And here are some results.












another cool blended result of Trump's face on Obama's body.
Now we look at a couple bad results. The outputs are decent, but the difference in the 2 images was too high, resulting in a clear blurry outline of the image.


2: Bells and Whistles
I tried doing the mixed gradient part of Gradient Domain Fusion. I was able to correctly create the new b vector, which contains the sum of highest gradients in x and y, from the source or target. I have shown the source and target images used, as well as the mixed gradient vector found. However, when solving with least squares like in the previous part, I am not able to recreate an image that places the text onto the texture of the wall. I used the same A that worked in previous parts, and b as described above, but using least squares to solve for x in A*x = b did not return a meaningful result.

