CS194-26 Fall 2022 Final Project
Lightfield Camera and Artistic Style Transfer
Grace Chen
Light Field Camera
Overview
In this project, we average 289 pictures taken from 17 x 17 camerage arranged in an array to mimic the effects of an camera.
This project is mainly composed of 2 components:
- Depth Refocusing
- Aperture Adjustment
Part 1 Depth Refocusing
Naively, we can average the 289 images to get an image such that objects farther are focused and objects close by are blurry.
In this part of the project, we shift, and align the images before average so that we can adjust the image to focus at different depths.
Specifically, we know the position of the camera with respect to the 17x17 grid and we know the distance from which they vary.
Using these information, we can find the middle x and y values and shift accordingly.
Then, we multiple the shift by an alpha value between 0 and 1 to focus at different depth.
We can observe that smaller alpha values suggests that the final image would be similar to the result of naive averaging where the closer objects would be blurry.
Meanwhile, larger values, such as 0.5, will result in closer objects being focused and farther objects being blurry.
Part 2 Aperture Adjustment
In this part of the project, we adjust the aperture by taking a subset of the 289 images that we have.
Given a specified radius, we can choose this subset by expanding the number of images used from the center as the radius increases.
A Neural Algorithm of Artistic Style
Overview
In this project, I reimplemented the paper A Neural Algorithm for Artistic Styles (linked here https://arxiv.org/pdf/1508.06576.pdf).
Following the approach described in the paper, I extracted the style and content separately using different layers of VGG networks.
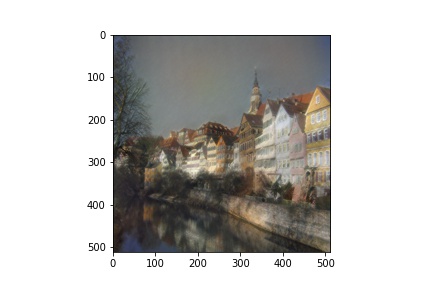
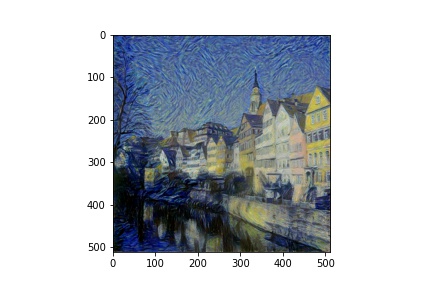
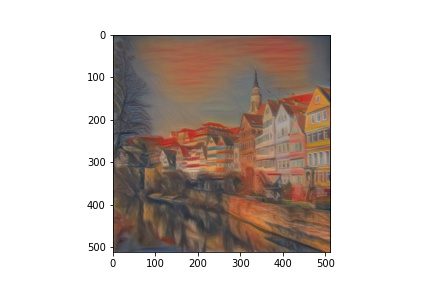
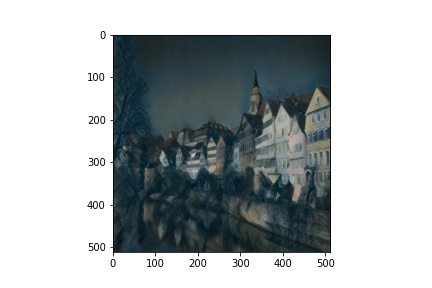
Then, setting one image to be the content and another to be the style, I was able to transfer the styles onto this new content image with example outputs below.
My Approach
Specifically,
I used a pretrained VGG network that I found online. I changed all style and content images to be of size 3, 512, 512.
I also normalized all inputs with means (0.485, 0.456, 0.406) and standard deviations (0.229, 0.224, 0.225) across the 3 color channels in the same way VGG would.
I declared the content loss to be MSE loss and style loss to be the MSE loss over the Gram matrix and used a LBFGS optimizer.
The network would try to minimize a weighted sum of the style loss and the content loss to obtain the desired outputs.
It is interesting to see that we train the images, not the network.
I experimented with different layers and different style weight to content weight ratios as hyperparameters.
The model I built on top of VGG with layers to compute style loss and content loss is as such.
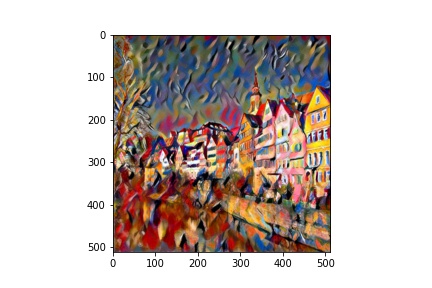
Outputs (Style and Content from paper)
More Outputs (of my own choosing)
Conclusion
I gained a lot of insights into both artistical style transfer and lightfield cameras.
In particular, it was exciting to see that I was able to produce outputs that were along the same lines as the "AI" art generations that is in so much hype right now.
It was such a fun final project experience an amazing semester!
This has truly been one of my favourit courses at Berkeley!