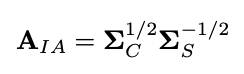As per the paper, I replaced the max pool layers in VGG-19
with average pools. Moreover, I used LBFGS as the optimizer for gradient
descent. I also experimented with ADAM, but LBFGS seemed to give the best
results. I used a default learning rate of 1.0 and achieved good
results.
Another change I made as opposed to the original paper is
that I changed the weights for the style loss contributed from each layer.
Namely, in the paper the loss is weighted equally for each layer, where as I
tinkered with these ratios for the images I generated to achieve better
results.
Bells and Whistles
A followup to the above paper addressed the issue of the colors in the
generated image matching the colors of the style image. Sometimes, we want
the newly generated image to match the color scheme of the content image.
This was adressed in this
paper. For my bells and whistles, I decided to implement one of the
approaches for transferring color.
One approach to transfer color is to apply a linear transformation to each
picture in the style image to change its color. Then, this newly colored
style image can be passed through the base generating algorithm we used for
the first part of the project. The methodology to generate this linear
transformation is subject to a few constraints: After the transformation, we
want the new mean vector (colors) to match the mean color vector of the
content image, and we want the new pixel (color) covariance matrix to match
the pixel color covariance matrix for the content image. There are a few
ways to do this, but one is done by the following:
I implemented the computation of this matrix and applied it to transfer
colors between images. Here are some results:
Finally, I generated images using the color transfer. Here are some results: