




We follow the paper. We use VGG19 Net, backpropping on an image (or white noise) so that it converges to the desired content and style image with respective weights.
| style image | generated output |
|
|
|
|
|
|
|
|
|
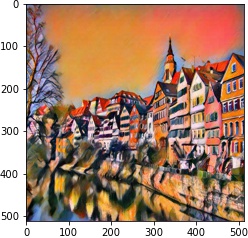
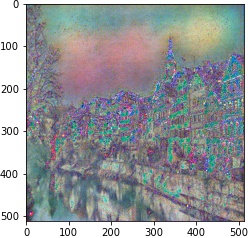
| 10^5 | 10^4 | 10^3 | 10^2 | |
| 1 layer | 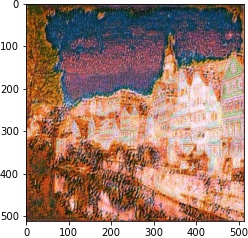 |
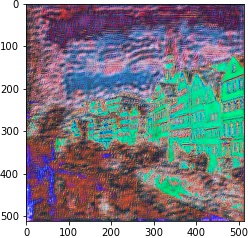 |
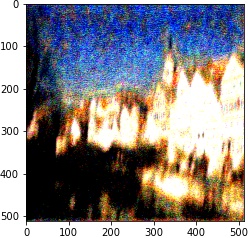 |
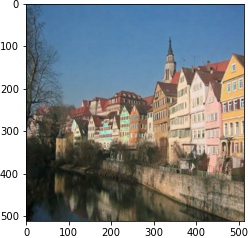 |
| 2 layer | 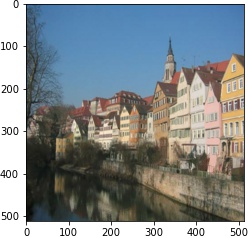 |
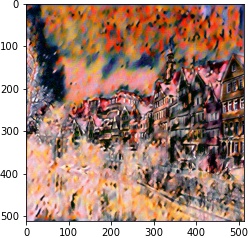 |
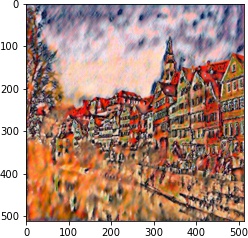 |
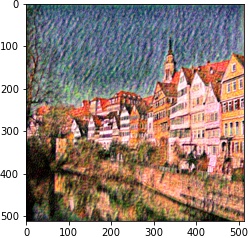 |
| 2 layer | 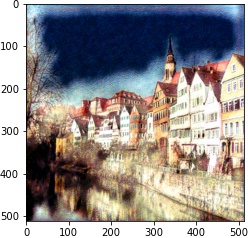 |
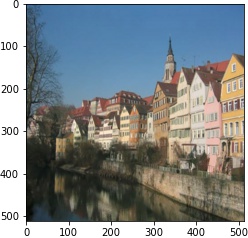 |
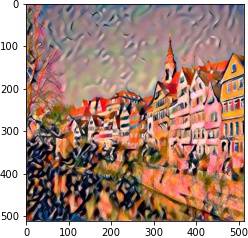 |
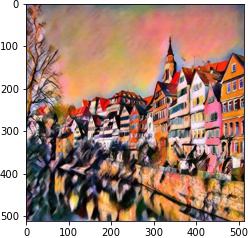 |
| 3 layer | 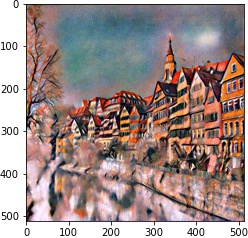 |
 |
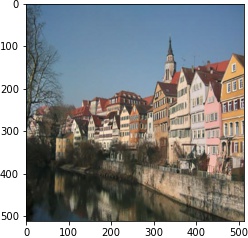 |
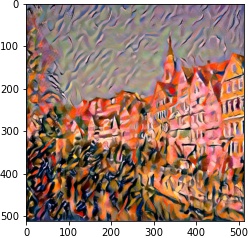 |
| 4 layer | 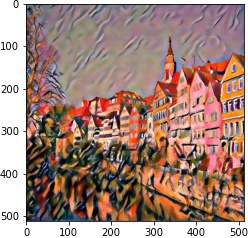 |
 |
 |
 |
We first use plt.ginput to get the camera coordinates of the box.
We then use cv2.TrackerMedianFlow_create() to estimate the camera coordinates for all the other
frames.
We then find camera projection with least square for each frame.
We use pyrender to render the object. We set pyrender.constants.RenderFlags.RGBA to get RGBA images
so that it can be blended with the video frames.
In addition to cv2.calibrateCamera, we also need cv2.Rodrigues to facilitate us to get
the Rt matrix.
Afterwards we traverse through the frames and calculate the new Rt matrix for every frame to position and rotate
the mesh object.